DdddOcr 带带弟弟OCR通用验证码离线本地识别SDK免费开源版
DdddOcr,其由 本作者 与 kerlomz 共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
DdddOcr、最简依赖的理念,尽量减少用户的配置和使用成本,希望给每一位测试者带来舒适的体验
项目地址: 点我传送






一个容易使用的通用验证码识别python库
探索本项目的文档 »
·
报告Bug
·
提出新特性
目录
赞助合作商
 | YesCaptcha | 谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口 点我 直达VIP4 |
 | 超级鹰 | 全球领先的智能图片分类及识别商家,安全、准确、高效、稳定、开放,强大的技术及校验团队,支持大并发。7*24h作业进度管理 |
 | Malenia | Malenia企业级代理IP网关平台/代理IP分销软件 |
| 雨云VPS | 注册首月5折 | 浙江节点低价大带宽,100M每月30元 |
上手指南
环境支持
| Windows 64位 | √ | √ | 3.12 | 部分版本windows需要安装vc运行库 |
| Windows 32位 | × | × | - | |
| Linux 64 / ARM64 | √ | √ | 3.12 | |
| Linux 32 | × | × | - | |
| Macos X64 | √ | √ | 3.12 | M1/M2/M3...芯片参考#67 |
安装步骤
i. 从pypi安装
pip install ddddocr
ii. 从源码安装
git clone https://github.com/sml2h3/ddddocr.git
cd ddddocr
python setup.py
请勿直接在ddddocr项目的根目录内直接import ddddocr,请确保你的开发项目目录名称不为ddddocr,此为基础常识。
文件目录说明
eg:
ddddocr
├── MANIFEST.in
├── LICENSE
├── README.md
├── /ddddocr/
│ │── __init__.py 主代码库文件
│ │── common.onnx 新ocr模型
│ │── common_det.onnx 目标检测模型
│ │── common_old.onnx 老ocr模型
│ │── logo.png
│ │── README.md
│ │── requirements.txt
├── logo.png
└── setup.py
项目底层支持
本项目基于dddd_trainer 训练所得,训练底层框架位pytorch,ddddocr推理底层抵赖于onnxruntime,故本项目的最大兼容性与python版本支持主要取决于onnxruntime。
使用文档
i. 基础ocr识别能力
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写or通过设置结果范围圈定大小写)、数字以及部分特殊字符。
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)
本库内置有两套ocr模型,默认情况下不会自动切换,需要在初始化ddddocr的时候通过参数进行切换
import ddddocr
ocr = ddddocr.DdddOcr(beta=True)
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)
提示
对于部分透明黑色png格式图片得识别支持: classification 方法 使用 png_fix 参数,默认为False
ocr.classification(image, png_fix=True)
注意
之前发现很多人喜欢在每次ocr识别的时候都重新初始化ddddocr,即每次都执行ocr = ddddocr.DdddOcr(),这是错误的,通常来说只需要初始化一次即可,因为每次初始化和初始化后的第一次识别速度都非常慢
参考例图
包括且不限于以下图片




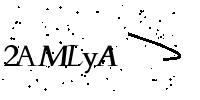




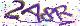


ii. 目标检测能力
主要用于快速检测出图像中可能的目标主体位置,由于被检测出的目标不一定为文字,所以本功能仅提供目标的bbox位置 (在⽬标检测⾥,我们通常使⽤bbox(bounding box,缩写是 bbox)来描述⽬标位置。bbox是⼀个矩形框,可以由矩形左上⻆的 x 和 y 轴坐标与右下⻆的 x 和 y 轴坐标确定)
如果使用过程中无需调用ocr功能,可以在初始化时通过传参ocr=False关闭ocr功能,开启目标检测需要传入参数det=True
import ddddocr
import cv2
det = ddddocr.DdddOcr(det=True)
with open("test.jpg", 'rb') as f:
image = f.read()
bboxes = det.detection(image)
print(bboxes)
im = cv2.imread("test.jpg")
for bbox in bboxes:
x1, y1, x2, y2 = bbox
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
参考例图
包括且不限于以下图片
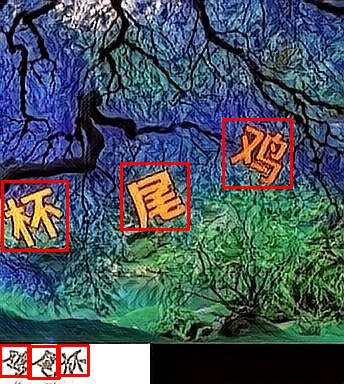

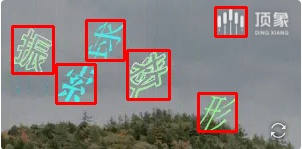


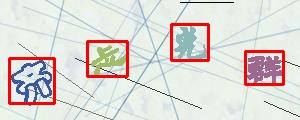

Ⅲ. 滑块检测
本项目的滑块检测功能并非AI识别实现,均为opencv内置算法实现。可能对于截图党用户没那么友好~,如果使用过程中无需调用ocr功能或目标检测功能,可以在初始化时通过传参ocr=False关闭ocr功能或det=False来关闭目标检测功能
本功能内置两套算法实现,适用于两种不同情况,具体请参考以下说明
a.算法1
算法1原理是通过滑块图像的边缘在背景图中计算找到相对应的坑位,可以分别获取到滑块图和背景图,滑块图为透明背景图
滑块图

背景图

det = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
res = det.slide_match(target_bytes, background_bytes)
print(res)
由于滑块图可能存在透明边框的问题,导致计算结果不一定准确,需要自行估算滑块图透明边框的宽度用于修正得出的bbox
提示:如果滑块无过多背景部分,则可以添加simple_target参数, 通常为jpg或者bmp格式的图片
slide = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.jpg', 'rb') as f:
target_bytes = f.read()
with open('background.jpg', 'rb') as f:
background_bytes = f.read()
res = slide.slide_match(target_bytes, background_bytes, simple_target=True)
print(res)
a.算法2
算法2是通过比较两张图的不同之处进行判断滑块目标坑位的位置
参考图a,带有目标坑位阴影的全图

参考图b,全图

slide = ddddocr.DdddOcr(det=False, ocr=False)
with open('bg.jpg', 'rb') as f:
target_bytes = f.read()
with open('fullpage.jpg', 'rb') as f:
background_bytes = f.read()
img = cv2.imread("bg.jpg")
res = slide.slide_comparison(target_bytes, background_bytes)
print(res)
Ⅳ. OCR概率输出
为了提供更灵活的ocr结果控制与范围限定,项目支持对ocr结果进行范围限定。
可以通过在调用classification方法的时候传参probability=True,此时classification方法将返回全字符表的概率
当然也可以通过set_ranges方法设置输出字符范围来限定返回的结果。
Ⅰ. set_ranges 方法限定返回字符返回
本方法接受1个参数,如果输入为int类型为内置的字符集限制,string类型则为自定义的字符集
如果为int类型,请参考下表
| 0 | 纯整数0-9 |
| 1 | 纯小写英文a-z |
| 2 | 纯大写英文A-Z |
| 3 | 小写英文a-z + 大写英文A-Z |
| 4 | 小写英文a-z + 整数0-9 |
| 5 | 大写英文A-Z + 整数0-9 |
| 6 | 小写英文a-z + 大写英文A-Z + 整数0-9 |
| 7 | 默认字符库 - 小写英文a-z - 大写英文A-Z - 整数0-9 |
如果为string类型请传入一段不包含空格的文本,其中的每个字符均为一个待选词
如:"0123456789+-x/=""
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
ocr.set_ranges("0123456789+-x/=")
result = ocr.classification(image, probability=True)
s = ""
for i in result['probability']:
s += result['charsets'][i.index(max(i))]
print(s)
Ⅴ. 自定义OCR训练模型导入
本项目支持导入来自于 dddd_trainer 进行自定义训练后的模型,参考导入代码为
import ddddocr
ocr = ddddocr.DdddOcr(det=False, ocr=False, import_onnx_path="myproject_0.984375_139_13000_2022-02-26-15-34-13.onnx", charsets_path="charsets.json")
with open('test.jpg', 'rb') as f:
image_bytes = f.read()
res = ocr.classification(image_bytes)
print(res)
版本控制
该项目使用Git进行版本管理。您可以在repository参看当前可用版本。
相关推荐文章or项目
带带弟弟OCR,纯VBA本地获取网络验证码整体解决方案
ddddocr rust 版本
captcha-killer的修改版
通过ddddocr训练字母数字验证码模型并识别部署调用
...
欢迎更多优秀案例或教程等进行投稿,可直接新建issue标题以【投稿】开头,附上公开教程站点链接,我会选择根据文章内容选择相对不重复或者有重点内容等进行readme展示,感谢各位朋友~
作者
sml2h3@gamil.com

好友数过多不一定通过,有问题可以在issue进行交流
版权说明
该项目签署了MIT 授权许可,详情请参阅 LICENSE
捐赠 (如果项目有帮助到您,可以选择捐赠一些费用用于ddddocr的后续版本维护,本项目长期维护)


Star 历史





