
Security News
MCP Community Begins Work on Official MCP Metaregistry
The MCP community is launching an official registry to standardize AI tool discovery and let agents dynamically find and install MCP servers.
By Sarah Gooding - May 09, 2025
Fast and accurate natural language detection. Detector written in Python. Nito-ELD, ELD.
![]()
![]()
Efficient language detector (Nito-ELD or ELD) is a fast and accurate language detector, is one of the fastest non compiled detectors, while its accuracy is within the range of the heaviest and slowest detectors.
It's 100% Python, easy installation and no dependencies other than regex.
ELD is also available in Javascript and PHP.
This is the first version of a port made from the original version in PHP, the structure might not be definitive, the code can be optimized. My knowledge of Python is basic, feel free to suggest improvements.
$ pip install eld
Alternatively, download / clone the files can work too, by changing the import path.
from eld import LanguageDetector
detector = LanguageDetector()
detect() expects a UTF-8 string, and returns an object, with a 'language' variable, which is either an ISO 639-1 code or None
print(detector.detect('Hola, cómo te llamas?'))
# Object { language: "es", scores(): {"es": 0.53, "et": 0.21, ...}, is_reliable(): True }
# Object { language: None|str, scores(): None|dict, is_reliable(): bool }
print(detector.detect('Hola, cómo te llamas?').language)
# "es"
# if clean_text(True), detect() removes Urls, domains, emails, alphanumerical & numbers
detector.clean_text(True) # Default is False
lang_subset = ['en', 'es', 'fr', 'it', 'nl', 'de']
# Option 1
# with dynamic_lang_subset(), detect() executes normally, and then filters excluded languages
detector.dynamic_lang_subset(lang_subset)
# Returns an object with a list named 'languages', with the validated languages or 'None'
# Option 2. lang_subset() Will first remove the excluded languages, from the n-grams database
# For a single detection is slower than dynamic_lang_subset(), but for several will be faster
# If save option is true (default), the new Ngrams subset will be stored, and loaded next call
detector.lang_subset(lang_subset) # lang_subset(langs, save=True)
# Returns object {success: True, languages: ['de', 'en', ...], error: None, file: 'ngramsM60...'}
# To remove either dynamic_lang_subset() or lang_subset(), call the methods with None as argument
detector.lang_subset(None)
# Finally the optimal way to regularly use a language subset: we create the instance with a file
# The file in the argument can be a subset by lang_subset() or another database like 'ngramsL60'
langSubsetDetect = LanguageDetector('ngramsL60')
I compared ELD with a different variety of detectors, since the interesting part is the algorithm.
| URL | Version | Language |
|---|---|---|
| https://github.com/nitotm/efficient-language-detector-py/ | 0.9.0 | Python |
| https://github.com/nitotm/efficient-language-detector/ | 1.0.0 | PHP |
| https://github.com/pemistahl/lingua-py | 1.3.2 | Python |
| https://github.com/CLD2Owners/cld2 | Aug 21, 2015 | C++ |
| https://github.com/google/cld3 | Aug 28, 2020 | C++ |
| https://github.com/wooorm/franc | 6.1.0 | Javascript |
Benchmarks: Tweets: 760KB, short sentences of 140 chars max.; Big test: 10MB, sentences in all 60 languages supported; Sentences: 8MB, this is the Lingua sentences test, minus unsupported languages.
Short sentences is what ELD and most detectors focus on, as very short text is unreliable, but I included the Lingua Word pairs 1.5MB, and Single words 880KB tests to see how they all compare beyond their reliable limits.
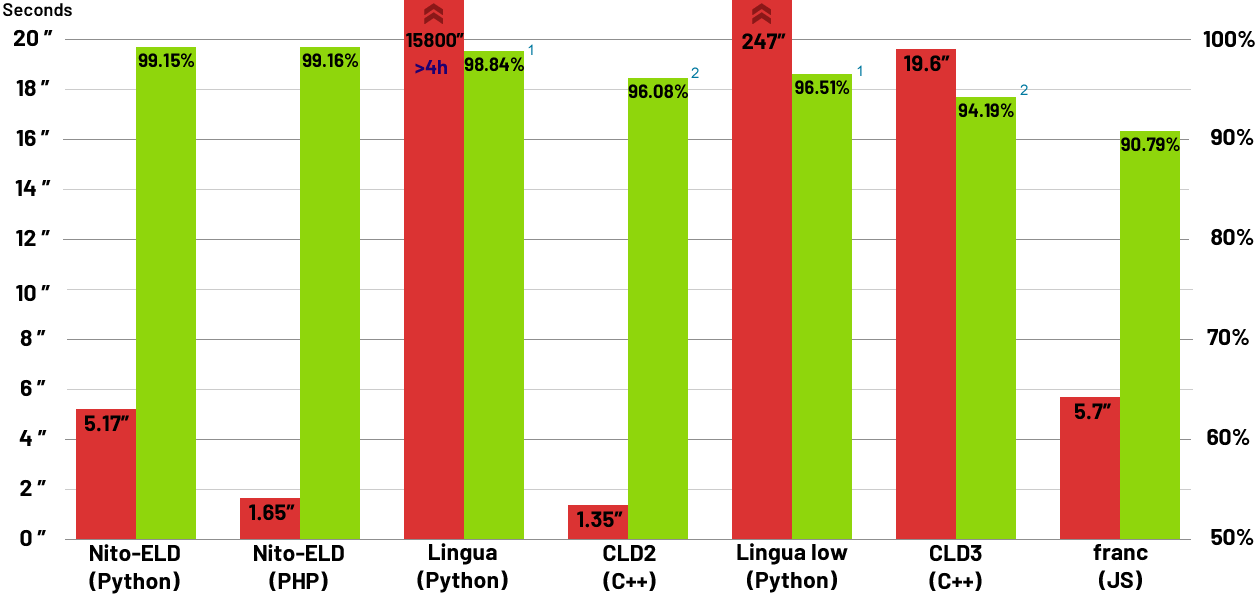
These are the results, first, accuracy and then execution time.


1. Lingua could have a small advantage as it participates with 54 languages, 6 less.
2. CLD2 and CLD3, return a list of languages, the ones not included in this test where discarded, but usually they return one language, I believe they have a disadvantage.
Also, I confirm the results of CLD2 for short text are correct, contrary to the test on the Lingua page, they did not use the parameter "bestEffort = True", their benchmark for CLD2 is unfair.
Lingua is the average accuracy winner, but at what cost, the same test that in ELD or CLD2 is below 10 seconds, in Lingua takes more than 5 hours! It acts like a brute-force software. Also, its lead comes from single and pair words, which are unreliable regardless.
The Python version of NITO-ELD is not the fastest but is still considered fast, as it is faster than any other non compiled detector tested.
I added ELD-L for comparison, which has a 2.3x bigger database, but only increases execution time marginally, a testament to the efficiency of the algorithm. ELD-L is not the main database as it does not improve language detection in sentences.
Here is the average, per benchmark, of Tweets, Big test & Sentences.
These are the ISO 639-1 codes of the 60 supported languages for Nito-ELD v1
'am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu', 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl', 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur', 'vi', 'yo', 'zh'
Full name languages:
Amharic, Arabic, Azerbaijani (Latin), Belarusian, Bulgarian, Bengali, Catalan, Czech, Danish, German, Greek, English, Spanish, Estonian, Basque, Persian, Finnish, French, Gujarati, Hebrew, Hindi, Croatian, Hungarian, Armenian, Icelandic, Italian, Japanese, Georgian, Kannada, Korean, Kurdish (Arabic), Lao, Lithuanian, Latvian, Malayalam, Marathi, Malay (Latin), Dutch, Norwegian, Oriya, Punjabi, Polish, Portuguese, Romanian, Russian, Slovak, Slovene, Albanian, Serbian (Cyrillic), Swedish, Tamil, Telugu, Thai, Tagalog, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba, Chinese
Donate / Hire
If you wish to Donate for open source improvements, Hire me for private modifications / upgrades, or to Contact me, use the following link: https://linktr.ee/nitotm
FAQs
Fast and accurate natural language detection. Detector written in Python. Nito-ELD, ELD.
We found that eld demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP community is launching an official registry to standardize AI tool discovery and let agents dynamically find and install MCP servers.

Research
Security News
Socket uncovers an npm Trojan stealing crypto wallets and BullX credentials via obfuscated code and Telegram exfiltration.

Research
Security News
Malicious npm packages posing as developer tools target macOS Cursor IDE users, stealing credentials and modifying files to gain persistent backdoor access.