Product
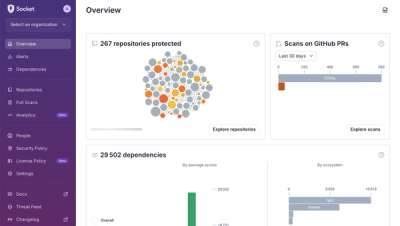
A New Overview in our Dashboard
We redesigned Socket's first logged-in page to display rich and insightful visualizations about your repositories protected against supply chain threats.
By André Staltz - Apr 29, 2025
![]()
fast-langdetect is an ultra-fast and highly accurate language detection library based on FastText, a library developed by Facebook. Its incredible speed and accuracy make it 80x faster than conventional methods and deliver up to 95% accuracy.
3.9 to 3.13.numpy required (thanks to @dalf).Background
This project builds upon zafercavdar/fasttext-langdetect with enhancements in packaging. For more information about the underlying model, see the official FastText documentation: Language Identification.
Possible memory usage
This library requires at least 200MB memory in low-memory mode.
To install fast-langdetect, you can use either pip or pdm:
pip install fast-langdetect
pdm add fast-langdetect
In scenarios where accuracy is important, you should not rely on the detection results of small models, use low_memory=False to download larger models!
FTLANG_CACHE environment variableLangDetectConfig(cache_dir="your/path")from fast_langdetect import detect, detect_multilingual, LangDetector, LangDetectConfig, DetectError
# Simple detection
print(detect("Hello, world!"))
# Output: {'lang': 'en', 'score': 0.12450417876243591}
# Using large model for better accuracy
print(detect("Hello, world!", low_memory=False))
# Output: {'lang': 'en', 'score': 0.98765432109876}
# Custom configuration with fallback mechanism
config = LangDetectConfig(
cache_dir="/custom/cache/path", # Custom model cache directory
allow_fallback=True # Enable fallback to small model if large model fails
)
detector = LangDetector(config)
try:
result = detector.detect("Hello world", low_memory=False)
print(result) # {'lang': 'en', 'score': 0.98}
except DetectError as e:
print(f"Detection failed: {e}")
# How to deal with multiline text
multiline_text = """
Hello, world!
This is a multiline text.
"""
multiline_text = multiline_text.replace("\n", " ")
print(detect(multiline_text))
# Output: {'lang': 'en', 'score': 0.8509423136711121}
# Multi-language detection
results = detect_multilingual(
"Hello 世界 こんにちは",
low_memory=False, # Use large model for better accuracy
k=3 # Return top 3 languages
)
print(results)
# Output: [
# {'lang': 'ja', 'score': 0.4},
# {'lang': 'zh', 'score': 0.3},
# {'lang': 'en', 'score': 0.2}
# ]
We provide a fallback mechanism: when allow_fallback=True, if the program fails to load the large model (low_memory=False), it will fall back to the offline small model to complete the prediction task.
# Disable fallback - will raise error if large model fails to load
# But fallback disabled when custom_model_path is not None, because its a custom model, we will directly use it.
import tempfile
config = LangDetectConfig(
allow_fallback=False,
custom_model_path=None,
cache_dir=tempfile.gettempdir(),
)
detector = LangDetector(config)
try:
result = detector.detect("Hello world", low_memory=False)
except DetectError as e:
print("Model loading failed and fallback is disabled")
detect_language Functionfrom fast_langdetect import detect_language
# Single language detection
print(detect_language("Hello, world!"))
# Output: EN
print(detect_language("Привет, мир!"))
# Output: RU
print(detect_language("你好,世界!"))
# Output: ZH
# Load model from local file
config = LangDetectConfig(
custom_model_path="/path/to/your/model.bin", # Use local model file
disable_verify=True # Skip MD5 verification
)
detector = LangDetector(config)
result = detector.detect("Hello world")
For text splitting based on language, please refer to the split-lang repository.
For detailed benchmark results, refer to zafercavdar/fasttext-langdetect#benchmark.
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification
@article{joulin2016bag,
title={Bag of Tricks for Efficient Text Classification},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.01759},
year={2016}
}
[2] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, FastText.zip: Compressing text classification models
@article{joulin2016fasttext,
title={FastText.zip: Compressing text classification models},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{\'e}gou, H{\'e}rve and Mikolov, Tomas},
journal={arXiv preprint arXiv:1612.03651},
year={2016}
}
FAQs
Quickly detect text language and segment language
We found that fast-langdetect demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
We redesigned Socket's first logged-in page to display rich and insightful visualizations about your repositories protected against supply chain threats.

Product
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.

Security News
CISA denies CVE funding issues amid backlash over a new CVE foundation formed by board members, raising concerns about transparency and program governance.