Product
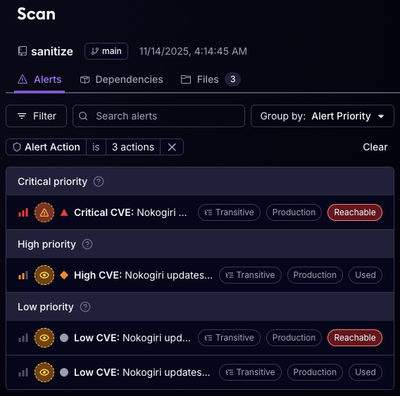
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
The Firecrawl Python SDK is a library that allows you to easily scrape and crawl websites, and output the data in a format ready for use with language models (LLMs). It provides a simple and intuitive interface for interacting with the Firecrawl API.
To install the Firecrawl Python SDK, you can use pip:
pip install firecrawl-py
FIRECRAWL_API_KEY or pass it as a parameter to the Firecrawl class.Here's an example of how to use the SDK:
from firecrawl import Firecrawl
from firecrawl.types import ScrapeOptions
firecrawl = Firecrawl(api_key="fc-YOUR_API_KEY")
# Scrape a website (v2):
data = firecrawl.scrape(
'https://firecrawl.dev',
formats=['markdown', 'html']
)
print(data)
# Crawl a website (v2 waiter):
crawl_status = firecrawl.crawl(
'https://firecrawl.dev',
limit=100,
scrape_options=ScrapeOptions(formats=['markdown', 'html'])
)
print(crawl_status)
To scrape a single URL, use the scrape method. It takes the URL as a parameter and returns a document with the requested formats.
# Scrape a website (v2):
scrape_result = firecrawl.scrape('https://firecrawl.dev', formats=['markdown', 'html'])
print(scrape_result)
To crawl a website, use the crawl method. It takes the starting URL and optional parameters as arguments. You can control depth, limits, formats, and more.
crawl_status = firecrawl.crawl(
'https://firecrawl.dev',
limit=100,
scrape_options=ScrapeOptions(formats=['markdown', 'html']),
poll_interval=30
)
print(crawl_status)
Looking for async operations? Check out the Async Class section below.
To enqueue a crawl asynchronously, use start_crawl. It returns the crawl ID which you can use to check the status of the crawl job.
crawl_job = firecrawl.start_crawl(
'https://firecrawl.dev',
limit=100,
scrape_options=ScrapeOptions(formats=['markdown', 'html']),
)
print(crawl_job)
To check the status of a crawl job, use the get_crawl_status method. It takes the job ID as a parameter and returns the current status of the crawl job.
crawl_status = firecrawl.get_crawl_status("<crawl_id>")
print(crawl_status)
To cancel an asynchronous crawl job, use the cancel_crawl method. It takes the job ID of the asynchronous crawl as a parameter and returns the cancellation status.
cancel_crawl = firecrawl.cancel_crawl(id)
print(cancel_crawl)
Use map to generate a list of URLs from a website. Options let you customize the mapping process, including whether to use the sitemap or include subdomains.
# Map a website (v2):
map_result = firecrawl.map('https://firecrawl.dev')
print(map_result)
{/* ### Extracting Structured Data from Websites
To extract structured data from websites, use the extract method. It takes the URLs to extract data from, a prompt, and a schema as arguments. The schema is a Pydantic model that defines the structure of the extracted data.
*/}
To crawl a website with WebSockets, use the crawl_url_and_watch method. It takes the starting URL and optional parameters as arguments. The params argument allows you to specify additional options for the crawl job, such as the maximum number of pages to crawl, allowed domains, and the output format.
# inside an async function...
nest_asyncio.apply()
# Define event handlers
def on_document(detail):
print("DOC", detail)
def on_error(detail):
print("ERR", detail['error'])
def on_done(detail):
print("DONE", detail['status'])
# Function to start the crawl and watch process
async def start_crawl_and_watch():
# Initiate the crawl job and get the watcher
watcher = app.crawl_url_and_watch('firecrawl.dev', exclude_paths=['blog/*'], limit=5)
# Add event listeners
watcher.add_event_listener("document", on_document)
watcher.add_event_listener("error", on_error)
watcher.add_event_listener("done", on_done)
# Start the watcher
await watcher.connect()
# Run the event loop
await start_crawl_and_watch()
The SDK handles errors returned by the Firecrawl API and raises appropriate exceptions. If an error occurs during a request, an exception will be raised with a descriptive error message.
For async operations, you can use the AsyncFirecrawl class. Its methods mirror the Firecrawl class, but you await them.
from firecrawl import AsyncFirecrawl
firecrawl = AsyncFirecrawl(api_key="YOUR_API_KEY")
# Async Scrape (v2)
async def example_scrape():
scrape_result = await firecrawl.scrape(url="https://example.com")
print(scrape_result)
# Async Crawl (v2)
async def example_crawl():
crawl_result = await firecrawl.crawl(url="https://example.com")
print(crawl_result)
For legacy code paths, v1 remains available under firecrawl.v1 with the original method names.
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="YOUR_API_KEY")
# v1 methods (feature‑frozen)
doc_v1 = firecrawl.v1.scrape_url('https://firecrawl.dev', formats=['markdown', 'html'])
crawl_v1 = firecrawl.v1.crawl_url('https://firecrawl.dev', limit=100)
map_v1 = firecrawl.v1.map_url('https://firecrawl.dev')
FAQs
Python SDK for Firecrawl API
We found that firecrawl demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.