{kind=link}

Security News
Opengrep Adds Apex Support and New Rule Controls in Latest Updates
The latest Opengrep releases add Apex scanning, precision rule tuning, and performance gains for open source static code analysis.
By Sarah Gooding - Aug 12, 2025
Inspect, search, organize, programmatically extract values and generate static website mirrors from, archive, view, and replay `HTTP` archives/dumps in `WRR` ("Web Request+Response", produced by the `Hoardy-Web` Web Extension browser add-on) and `mitmproxy` (`mitmdump`) file formats.
hoardy-web?hoardy-web is a tool to inspect, search, organize, programmatically extract values and generate static website mirrors from, archive, view, and replay HTTP archives/dumps in WRR ("Web Request+Response", produced by the Hoardy-Web Web Extension browser add-on, also on GitHub) and mitmproxy (mitmdump) file formats.
The top part of this README file (from here to "Usage") is designed to be read in a linear fashion, not piece-meal.
The "Usage" section can be read and referenced to in arbitrary order.
Install Python 3:
Add python.exe to PATH checkbox, then Install (the default options are fine).python3 via your package manager. Realistically, it probably is installed already.On a Windows system:
Open cmd.exe (press Windows+R, enter cmd.exe, press Enter), install this with
python -m pip install hoardy-web
and run as
python -m hoardy_web --help
On a POSIX system or on a Windows system with Python's /Scripts added to PATH:
Open a terminal/cmd.exe, install this with
pip install hoardy-web
and run as
hoardy-web --help
Alternatively, for light development (without development tools, for those see nix-shell below):
Open a terminal/cmd.exe, cd into this directory, then install with
python -m pip install -e .
# or
pip install -e .
and run as:
python -m hoardy_web --help
# or
hoardy-web --help
Alternatively, on a system with Nix package manager
nix-env -i -f ./default.nix
hoardy-web --help
Though, in this case, you'll probably want to do the first command from the parent directory, to install everything all at once.
Alternatively, to replicate my development environment:
nix-shell ./default.nix --arg developer true
python -m hoardy_web serve --implicit --archive-to C:\Users\Me\Documents\hoardy-web\raw
# or
hoardy-web serve --implicit --archive-to ~/hoardy-web/raw
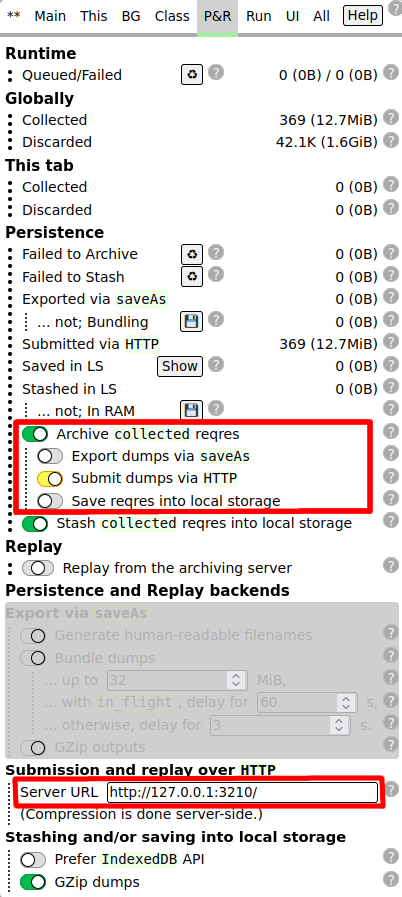
Hoardy-Web extension into your browser.Submit dumps via 'HTTP' mode and ensure it points to the URL of the above hoardy-web serve instance (like this screenshot of the P&R tab shows).HTTPYou can then navigate to
This is very reminiscent of the Wayback Machine by design, yes.
You can also use your archived data to generate a local offline static website mirror that can be opened in a web browser without accessing the Internet, similar to what wget -mpk does.
The invocation is slightly different depending on if the data was exported via saveAs by the Hoardy-Web extension itself, saved via the hoardy-web-sas simple archiving server, or via hoardy-web serve --archive-to (see below):
# for "Export via `saveAs`"
hoardy-web mirror --to ~/hoardy-web/mirror1 ~/Downloads/Hoardy-Web-export-*
# for `hoardy-web-sas` and/or `hoardy-web serve --archive-to`
hoardy-web mirror --to ~/hoardy-web/mirror1 ../simple_server/pwebarc-dump ~/hoardy-web/raw
You can then, e.g. rsync/copy ~/hoardy-web/mirror1 to your e-book reader/phone before hopping on a plane or going on a deep-sea dive, and still be able to read all those pages.
The default settings should work for most simple websites, but a section below contains more info and more usage examples.
A reqres (Reqres when a Python type) is an instance of a structure representing HTTP request+response pair with some additional metadata.
WARC is an ISO web archiving file format used by the Wayback Machine (heritrix) and many other tools.
mitmproxy is a tool stripping TLS from a connection, dumping and/or modifying the traffic going through it, and re-adding TLS back.
I.e. a Man-In-The-Middle proxy.
In the context of this project, mitmproxy is also a file format produced by the mitmdump tool.
WRR is a native archiving format used by Hoardy-Web project.
It is very much inspired by mitmproxy in that it stores a raw HTTP request+response pairs (instead of encoding GET documents like WARC does), but, unlike, mitmproxy, WRR is a CBOR (RFC8949) encoding of HTTP request+response pairs, not some custom binary encoding.
WRR file is a file with a single WRR dump in it.
Typically, these use .wrr file extension.
When you use the Hoardy-Web extension together with the hoardy-web-sas archiving server or hoardy-web serve, the latter two write WRR dumps the extension generates, one dump per file, into separate .wrr files in its dumping directory.
The situation is similar if you instead use the Hoardy-Web extension with Export via 'saveAs' option enabled but Export via 'saveAs' > Bundle dumps option disabled.
The only difference is that WRR files get written to your ~/Downloads or similar.
ls ~/Downloads/Hoardy-Web-export-*
WRR bundle is a file containing a concatenation of a bunch of plain uncompressed WRR dumps, which are then optionally compressed with GZip.
Typically, these use .wrrb file extension.
When you use the Hoardy-Web extension together with both Export via 'saveAs' and bundling options enabled, it archives your data by generating WRR bundles, which then get written to your ~/Downloads or similar.
HAR (abandoned W3C spec, a nicer spec) is an archiving file format used by the "Network Monitor" tools of most modern browsers.
It is similar mitmproxy and WRR in that it, too, stores HTTP request+response pairs, but it uses a very inefficient JSON encoding with body data encoded as base64 and a lot of the metadata duplicated multiple times across the structure.
PCAP is a file format used by many raw packet capture tools.
At the moment hoardy-web tool supports
WRR files (both compressed and not),WRR bundles (similarly),mitmproxy dumps, andHAR (using mitmproxy's parser).WARC and built-in HAR support will be added soon-ish, PCAP support will be added eventually.
All sub-commands of hoardy-web except for
organize when run with --move, --hardlink, or --symlink (i.e. with anything other than --copy),get, andruncan take all supported file formats as inputs. So, most examples described below will work fine with any mix of inputs as arguments.
You can, however, force hoardy-web to use a specific loader for all given inputs, e.g.:
hoardy-web mirror --to ~/hoardy-web/mirror1 \
--load-mitmproxy mitmproxy.*.dump
This is slightly faster than the default --load-any and, for most loaders, produces more specific errors that explain exactly what failed to parse, instead of simply saying that all tried parsers failed to work.
WRRTo use hoardy-web organize, get, and run sub-commands on data stored in file formats other than separate WRR files, you will have to import them first:
hoardy-web import bundle --to ~/hoardy-web/raw ~/Downloads/Hoardy-Web-export-*
hoardy-web import mitmproxy --to ~/hoardy-web/mitmproxy ~/mitmproxy/mitmproxy.*.dump
Note that .wrr files can be parsed as single-dump .wrrb files, so the first command above will work even when some of the exported dumps were exported as separate .wrr files by the Hoardy-Web extension (because you configured it to do that, because it exported a bucket with a single dump as a separate file, because it exported a dump that was larger than set maximum bundle size as a separate file, etc).
So, essentially, the first command above command is equivalent to
hoardy-web organize --copy --to ~/hoardy-web/raw ~/Downloads/Hoardy-Web-export-*.wrr
hoardy-web import bundle --to ~/hoardy-web/raw ~/Downloads/Hoardy-Web-export-*.wrrb
In fact, internally, hoardy-web import bundle is actually an alias for hoardy-web organize --copy --load-wrrb --defer-number 0.
You can search your archive directory by using hoardy-web find sub-command, that prints paths to those of its inputs which match given conditions.
For example, to list reqres from ~/hoardy-web/raw that contain complete GET requests with 200 OK responses, you can run:
hoardy-web find --method GET --status-re .200C ~/hoardy-web/raw
To limit the above to responses containing text/html bodies with a (whole) word "Potter" in them:
hoardy-web find --method GET --method DOM --status-re .200C --response-mime text/html \
--response-body-grep-re "\bPotter\b" ~/hoardy-web/raw
Most other sub-commands also accept the same filtering options. So, for instance, you can pretty-print or generate a static mirror from such files instead:
hoardy-web pprint --method GET --method DOM --status-re .200C --response-mime text/html \
--response-body-grep-re "\bPotter\b" \
~/hoardy-web/raw
# we set `--index-all-inputs` to disable its default input filters
hoardy-web mirror --index-all-inputs \
--method GET --method DOM --status-re .200C --response-mime text/html \
--response-body-grep-re "\bPotter\b" \
--to ~/hoardy-web/mirror-potter ~/hoardy-web/raw
Or, say, you want a list of all domains you ever visited that use CloudFlare:
hoardy-web stream --format=raw -ue hostname \
--response-headers-grep-re '^server: cloudflare' \
~/hoardy-web/raw | sort | uniq
Or, say, you want to get all responses from a certain host with JSONs, except when they were fetched from CloudFlare and encoded with br, and then feed them to a script:
hoardy-web find -z --url-re 'https://example\.org/.*' --response-mime text/json \
--not-response-headers-and-grep-re '^server: cloudflare' \
--not-response-headers-and-grep-re '^content-encoding: br' \
~/hoardy-web/raw > found-paths
xargs -0 my-example-org-json-parser < found-paths
See the "Usage" section below for all possible filtering options.
In principle, the possibilities are limitless since hoardy-web has a tiny expression language which you can use to do things not directly supported by the command-line options:
hoardy-web find --and "response.body|eb|len|> 10240" ~/hoardy-web/raw
and, if you are a developer, you can easily add your own custom functions into there.
To merge multiple input directories into one you can simply hoardy-web organize them --to a new directory.
hoardy-web will automatically deduplicate all the files in the generated result.
That is to say, for hoardy-web organize
--move is de-duplicating when possible,--copy, --hardlink, and --symlink are non-duplicating when possible.For example, if you duplicate an input directory via --copy or --hardlink:
hoardy-web organize --copy --to ~/hoardy-web/copy1 ~/hoardy-web/original
hoardy-web organize --hardlink --to ~/hoardy-web/copy2 ~/hoardy-web/original
(In real-life use different copies usually end up on different backup drives or some such.)
Then, repeating the same command would a noop:
# noops
hoardy-web organize --copy --to ~/hoardy-web/copy1 ~/hoardy-web/original
hoardy-web organize --hardlink --to ~/hoardy-web/copy2 ~/hoardy-web/original
And running the opposite command would also be a noop:
# noops
hoardy-web organize --hardlink --to ~/hoardy-web/copy1 ~/hoardy-web/original
hoardy-web organize --copy --to ~/hoardy-web/copy2 ~/hoardy-web/original
And copying between copies is also a noop:
# noops
hoardy-web organize --hardlink --to ~/hoardy-web/copy2 ~/hoardy-web/copy1
hoardy-web organize --copy --to ~/hoardy-web/copy2 ~/hoardy-web/copy1
But doing hoardy-web organize --move while supplying directories that have the same data will deduplicate the results:
hoardy-web organize --move --to ~/hoardy-web/all ~/hoardy-web/copy1 ~/hoardy-web/copy2
# `~/hoardy-web/all` will have each file only once
find ~/hoardy-web/copy1 ~/hoardy-web/copy2 -type f
# the output will be empty
hoardy-web organize --move --to ~/hoardy-web/original ~/hoardy-web/all
# `~/hoardy-web/original` will not change iff it is already organized using `--output default`
# otherwise, some files there will be duplicated
find ~/hoardy-web/all -type f
# the output will be empty
Similarly, hoardy-web organize --symlink resolves its input symlinks and deduplicates its output symlinks:
hoardy-web organize --symlink --output hupq_msn --to ~/hoardy-web/pointers ~/hoardy-web/original
hoardy-web organize --symlink --output shupq_msn --to ~/hoardy-web/schemed ~/hoardy-web/original
# noop
hoardy-web organize --symlink --output hupq_msn --to ~/hoardy-web/pointers ~/hoardy-web/original ~/hoardy-web/schemed
I.e. the above will produce ~/hoardy-web/pointers with unique symlinks pointing to each file in ~/hoardy-web/original only once.
Assuming you keep your WRR dumps in ~/hoardy-web/raw, the following commands will generate a file system hierarchy under ~/hoardy-web/latest organized in such a way that, for each URL from ~/hoardy-web/raw, it will contain a symlink from under ~/hoardy-web/latest to a file in ~/hoardy-web/raw pointing to the most recent WRR file containing 200 OK response for that URL:
# import exported extension outputs
hoardy-web import bundle --to ~/hoardy-web/raw ~/Downloads/Hoardy-Web-export-*
# and/or move and rename `hoardy-web-sas` outputs
hoardy-web organize --move --to ~/hoardy-web/raw ../simple_server/pwebarc-dump
# and then organize them
hoardy-web organize --symlink --latest --output hupq --to ~/hoardy-web/latest --status-re .200C ~/hoardy-web/raw
Personally, I prefer flat_mhs format (see the documentation of the --output below), as I dislike deep file hierarchies.
Using it also simplifies filtering in my ranger file browser, so I do this:
hoardy-web organize --symlink --latest --output flat_mhs --to ~/hoardy-web/latest --status-re .200C ~/hoardy-web/raw
The above commands rescan the whole contents of ~/hoardy-web/raw and so can take a while to complete.
If you have a lot of WRR files and you want to keep your symlink tree updated in near-real-time you will need to use a two-stage pipeline by giving the output of hoardy-web organize --zero-terminated to hoardy-web organize --stdin0 to perform complex updates.
E.g. the following will rename new WRR files from ../simple_server/pwebarc-dump to ~/hoardy-web/raw renaming them with --output default (the for loop is there to preserve buckets/profiles):
for arg in ../simple_server/pwebarc-dump/* ; do
hoardy-web organize --zero-terminated --to ~/hoardy-web/raw/"$(basename "$arg")" "$arg"
done > changes
Then, you can reuse the paths saved in changes file to update the symlink tree, like in the above:
hoardy-web organize --symlink --latest --output flat_mhs --to ~/hoardy-web/latest --status-re .200C --stdin0 < changes
Then, optionally, you can reuse changes file again to symlink all new files from ~/hoardy-web/raw to ~/hoardy-web/all, showing all URL versions, by using --output hupq_msn format:
hoardy-web organize --symlink --output hupq_msn --to ~/hoardy-web/all --stdin0 < changes
wget -mpkTo render your archived data into a local offline static website mirror containing interlinked HTML files and their requisite resources similar to (but better than) what wget -mpk (wget --mirror --page-requisites --convert-links) does, you need to run something like this:
# separate `WRR` files
hoardy-web mirror --to ~/hoardy-web/mirror1 ~/hoardy-web/raw
# separate `WRR` files and/or `WRR` bundles
hoardy-web mirror --to ~/hoardy-web/mirror1 ~/Downloads/Hoardy-Web-export-*
# `mitmproxy` dumps
hoardy-web mirror --to ~/hoardy-web/mirror1 mitmproxy.*.dump
# any mix of these
hoardy-web mirror --to ~/hoardy-web/mirror1 \
~/hoardy-web/raw \
~/Downloads/Hoardy-Web-export-* \
mitmproxy.*.dump
On completion, ~/hoardy-web/mirror1 will contain said newly generated interlinked HTML files, their resource requisites, and everything else available from given archive files.
The set of mirrored files can be limited with using several methods described below.
By default, the resulting HTML files will be stripped of all JavaScript and other stuff of various levels of evil.
The results should be completely self-contained (i.e., work inside a browser running in "Work offline" mode) and safe to view in a dumb unconfigured browser (i.e., the resulting web pages should not request any page requisites --- like images, media, CSS, fonts, etc --- from the Internet).
(In practice, though, hoardy-web mirror is not completely free of bugs and HTML5 spec is constantly evolving, with new things getting added there all the time.
So, it is entirely possible that the output of the above hoardy-web mirror invocation will not be completely self-contained.
Which is why the Hoardy-Web extension has its own per-tab Work offline mode which, by default, gets enabled for tabs with file: URLs.
That feature prevents the outputs of hoardy-web mirror from accessing the Internet regardless of any bugs or missing features in hoardy-web.
It also helps with debugging.)
If you are unhappy with the above and, for instance, want to keep JavaScript and produce human-readable HTMLs, you can run the following instead:
hoardy-web mirror \
-e 'response.body|eb|scrub response &all_refs,+scripts,+pretty' \
--to ~/hoardy-web/mirror2 ~/hoardy-web/raw
Or, say, you want to produce minimized outputs:
hoardy-web mirror \
-e 'response.body|eb|scrub response &all_refs,-verbose,-whitespace,-optional_tags' \
--to ~/hoardy-web/mirror2 ~/hoardy-web/raw
See the documentation for the --remap-* options of mirror sub-command and the options of the scrub function below for more info.
If you instead want a mirror made of raw files without any content censorship or link conversions, run:
# --raw-(re)s(ponse)body
hoardy-web mirror --raw-sbody --to ~/hoardy-web/mirror-raw ~/hoardy-web/raw
The later command will render your mirror rather quickly, but the other mirror commands use the scrub function, and that can be a bit slow, mostly because html5lib and tinycss2 that hoardy-web uses for paranoid HTML and CSS parsing and filtering are fairly slow.
Under CPython on my 2013-era laptop hoardy-web mirror manages to render, on average, 1-20 web pages per second, depending on the website.
Bunches of small pages reusing the same CSS files across them take less time, large pages, pages with a lot of complex HTML, or lots of inlined CSS take more.
Though, this is not very characteristic of the overall mirroring speed, since images and other media just get copied around at expected speeds of 300+ files per second.
Also, enabling +indent (or +pretty) in scrub will make HTML scrubbing slightly slower (since it will have to track more stuff) and CSS scrubbing a lot slower (since it will force complete structural parsing, not just tokenization).
By default, hoardy-web mirror runs with an implied --remap-all option which remaps all links in mirrored HTML files to local files, even if source WRR files for those would-be mirrored files are missing.
This allows you to easily update your mirror directory incrementally by re-running hoardy-web mirror with the same --to argument on new inputs.
For instance:
# render everything archived in 2023
hoardy-web mirror --to ~/hoardy-web/mirror1 ~/hoardy-web/raw/*/2023
# now, add new stuff archived in 2024, keeping already exported files as-is
hoardy-web mirror --skip-existing --to ~/hoardy-web/mirror1 ~/hoardy-web/raw/*/2024
# same, but updating old files
hoardy-web mirror --overwrite-dangerously --to ~/hoardy-web/mirror1 ~/hoardy-web/raw/*/2024
After the first of the above commands, links from pages generated from WRR files of ~/hoardy-web/raw/*/2023 to URLs contained in files from ~/hoardy-web/raw/*/2024 but not contained in files from ~/hoardy-web/raw/*/2023 will point to non-existent, yet unmirrored, files on disk.
I.e. those links will be broken.
Running the second or the third command from the example above will then mirror additional files from ~/hoardy-web/raw/*/2024, thus fixing some or all of those links.
wget -mpk doesIf you want to treat links pointing to not yet hoarded URLs exactly like wget -mpk does, i.e. you want to keep them pointing to their original URLs instead of remapping them to yet non-existent local files (like the default --remap-all does), you need to run mirror with --remap-open option:
hoardy-web mirror --remap-open --to ~/hoardy-web/mirror4 ~/hoardy-web/raw
In practice, however, you probably won't want the exact behaviour of wget -mpk, since opening pages generated that way is likely to make your web browser try to access the Internet to load missing page requisites.
To solve this problem, hoardy-web provides --remap-semi option, which does what --remap-open does, except it also remaps unavailable action links and page requisites into void links, fixing that problem:
hoardy-web mirror --remap-semi --to ~/hoardy-web/mirror4 ~/hoardy-web/raw
See the documentation for the --remap-* options below for more info.
Obviously, using --remap-open or --remap-semi will make incremental updates to your mirror impossible.
The simplest way to mirror a subset of your data is to run one of hoardy-web organize --symlink --latest commands described above, and then do something like this:
hoardy-web mirror --to ~/hoardy-web/mirror5 ~/hoardy-web/latest/archiveofourown.org
thus mirroring everything ever archived from https://archiveofourown.org.
--root-*, and --depthAs an alternative to (or in combination with) keeping a symlink hierarchy of latest versions, you can limit the set of files hoardy-web mirror will consider for mirroring by setting some input filters, e.g.:
hoardy-web mirror \
--to ~/hoardy-web/mirror6 ~/hoardy-web/raw/*/2023 \
--url-prefix 'https://archiveofourown.org/works/3733123' \
--url-prefix 'https://archiveofourown.org/works/30186441'
Note, however, that doing this will prevent mirror from processing reqres not accepted by specified filters.
Which, in the above example, will prevent mirror from processing most of requisite resources of those pages.
When running with --remap-all, as the above does, this can be solved by running hoardy-web mirror repeatedly with different input filters, e.g., to mostly fix the above outputs you could then run:
hoardy-web mirror \
--to ~/hoardy-web/mirror6 ~/hoardy-web/raw/*/2023 \
--url-re 'https://archiveofourown\.org/.*\.css'
but this is quite inconvenient, and when running with something other than --remap-all, it will leave many output pages completely broken anyway.
Which is why hoardy-web can instead load (an index of) an assortment of WRR files into its memory but then only mirror a subset of those reqres with all requisite resources needed to properly render those pages.
This can be archived by specifying some --root-* filtering options, e.g.:
hoardy-web mirror \
--to ~/hoardy-web/mirror6 ~/hoardy-web/raw/*/2023 \
--root-url-prefix 'https://archiveofourown.org/works/3733123' \
--root-url-prefix 'https://archiveofourown.org/works/30186441'
The --root-* options have exactly the same syntax and semantics as the normal input filtering options, except they start with --root- prefix, and instead of making hoardy-web accept reqres satisfying them as inputs, they make hoardy-web mirror queue such reqres for mirroring at the initial depth of 0.
An yes, there is also --depth option, which works similarly to wget's --level option in that it will follow all jump (a href) and action links accessible with no more than --depth browser navigations from recursion --root-*s and then mirror all those URLs and their requisites too.
When using --root-* options, --remap-open works exactly like wget's --convert-links in that it will only remap the URLs that are going to be mirrored and will keep the rest as-is.
Similarly, --remap-semi and --remap-closed will consider only the URLs reachable from the --root-*s in no more that --depth jumps as available.
Unlike most other sub-commands of hoardy-web which set no default filters, mirror runs with implied --ignore-some-inputs and --skip-some-indexed options which set some useful default input and root filters.
This can be disabled with --index-all-inputs and/or --queue-all-indexed, which can useful when using mirror to do weird things with custom --exprs, with the default --exprs, using these options is likely to produce a broken mirror, unless you add some specific filters manually.
See the documentation all of those options below for more info.
Also, note, that hoardy-web loads (indexes) WRR files pretty fast, so if you are running from an SSD, you can totally feed it years of WRR files and then only mirror a couple of URLs, and it will finish pretty quickly anyway.
By default, files are read, queued, and then mirrored in the order they are specified on the command line, in lexicographic file system walk order when an argument is a directory.
(See --paths-* and --walk-* options below if you want to change this.)
However, the above rule does not apply to page requisites, those are always (with or without --root-*, regardless of --paths-* and --walk-* options) get mirrored just after their parent HTML document gets parsed and before that document gets written to disk.
I.e., mirror will produce a new file containing an HTML document only after first producing all of its requisites.
I.e., when mirroring into an empty directory, if you see mirror generated an HTML document, you can be sure that all of its requisites loaded (indexed) by this mirror invocation are rendered too.
Meaning, you can go ahead and open it in your browser, even if mirror did not finish yet.
Moreover, unlike all other sub-commands mirror handles duplication in its input files in a special way: it remembers the files it has already seen and ignores them when they are given the second time.
(All other commands don't, they will just process the same file the second time, the third time, and so on.
This is by design, other commands are designed to handle potentially enormous file hierarchies in constant memory.)
The combination of all of the above means you can prioritize rendering of some documents over others by specifying them earlier on the command line and then, in a later argument, specifying their containing directory to allow mirror to also see their requisites and documents they link to.
For instance,
hoardy-web mirror \
--to ~/hoardy-web/mirror7 \
~/hoardy-web/latest/archiveofourown.org/works__3733123*.wrr \
~/hoardy-web/latest/archiveofourown.org
will mirror all of ~/hoardy-web/latest/archiveofourown.org, but the web pages contained in files named ~/hoardy-web/latest/archiveofourown.org/works__3733123*.wrr and their requisites will be mirrored first.
This also works with --root-* options.
E.g., the following
hoardy-web mirror \
--to ~/hoardy-web/mirror7 \
~/hoardy-web/latest/archiveofourown.org/works__3733123*.wrr \
~/hoardy-web/latest/archiveofourown.org \
--root-url-prefix 'https://archiveofourown.org/works/'
will mirror all pages those URLs start with https://archiveofourown.org/works/ and all their requisites, but the pages contained in files named ~/hoardy-web/latest/archiveofourown.org/works__3733123*.wrr and their requisites will be mirrored first.
Finally, there is also the --boring option, which allows you to load some input PATHs without queuing them as roots, even when no --root-* options are specified or specified --root-* options say those reqres should be taken as roots.
E.g., the following
hoardy-web mirror \
--to ~/hoardy-web/mirror8 \
--boring ~/hoardy-web/latest/i.imgur.com \
--boring ~/hoardy-web/latest/archiveofourown.org \
~/hoardy-web/latest/archiveofourown.org/works__[0-9]*.wrr
will load (an index of) everything under ~/hoardy-web/latest/i.imgur.com and ~/hoardy-web/latest/archiveofourown.org into memory but will only mirror the contents of ~/hoardy-web/latest/archiveofourown.org/works__[0-9]*.wrr files and their requisites.
By default, hoardy-web mirror runs with the implied --latest option, which renders the latest available version (visit) to each URL.
Usually, this is fine, as most modern web-sites use versioned page requisites to improve caching.
But it can produce broken results sometimes.
For instance, when two different web pages share an unversioned CSS file and one those pages was recently revisited while the other was not, then, with the default --latest, only the latter version of the CSS file in question will be mirrored, making the older page broken.
To fix this, you can run mirror with --latest-hybrid option
hoardy-web mirror \
--to ~/hoardy-web/mirror8 \
--root-url-prefix 'https://en.wikipedia.org/wiki/'
--latest-hybrid \
~/hoardy-web/raw
which will mirror each web page with its date-vise closest available resource requisites.
This takes quite a bit of memory, though, since mirror has to index and keep in memory references to all versions of all reqres to produce such hybrid results.
Similarly, you can also mirror the --oldest available version of each URL:
hoardy-web mirror \
--to ~/hoardy-web/mirror9 \
--root-url-prefix 'https://archiveofourown.org/works/'
--oldest \
~/hoardy-web/raw
or a version closest to a certain date:
hoardy-web mirror \
--to ~/hoardy-web/mirror9 \
--root-url-prefix 'https://en.wikipedia.org/wiki/'
--nearest 2020-10-31 \
~/hoardy-web/raw
both of which also have --*-hybrid variants.
There is also --all, which mirrors all available versions of all --root-*s and --depth-reachable URLs.
When using --all, you'll probably want to switch to a time-versioned output format, otherwise those default simply-numbered hupq_n outputs will be impossible to interpret:
hoardy-web mirror \
--to ~/hoardy-web/mirror9 \
--root-url-prefix 'https://en.wikipedia.org/wiki/'
--all \
--output hupq_tn \
~/hoardy-web/raw
Note that, by default, hoardy-web mirror runs with the implied --hardlink option, which makes it render and write each mirrored file to <--to>/_content/<hash/based/path>.<ext> and only then hardlink the result to <--to>/<output/format/based/path>.<ext> target destination.
The <hash/based/path> is derived from the sha256 hash of the generated file content.
This trick saves quite a bit of space in many cases.
E.g., when pages refer to the same resource requisites by slightly different URLs, same images and fonts get distributed via different CDN hosts, when you mirror --all visits to some URLs and many of those are absolutely identical, etc.
You can change the destination those hash-based paths get written to by specifying --content-to.
This allows you to easily share files between different mirrors:
hoardy-web mirror \
--content-to ~/hoardy-web/shared \
--to ~/hoardy-web/mirror10 \
--root-url-prefix 'https://archiveofourown.org/works/'
~/hoardy-web/raw
hoardy-web mirror \
--content-to ~/hoardy-web/shared \
--to ~/hoardy-web/mirror11 \
--root-url-prefix 'https://www.royalroad.com/'
~/hoardy-web/raw
You can also control the path of the generated files by setting --content-output, e.g.:
hoardy-web mirror \
--content-output 'format:%(content_sha256|take_prefix 1|to_hex)s/%(content_sha256|take_prefix 2|take_suffix 1|to_hex)s/%(content_sha256|to_hex)s'
--content-to ~/storage/sha256 \
--to ~/hoardy-web/mirror12 \
~/hoardy-web/raw
hoardy-web mirror never overwrites any files under --content-to.
It does, however, check that any existing files it references from there have the contents it expects, and generates errors if they do not.
That is, you can set --content-output to anything and give any directory as --content-to, and hoardy-web will still ensure that the results are consistent, even when the --content-to cache is poisoned, or when different file contents compute to the same hash (produce a hash collision).
Also note that, by default, mirror treats jump-links (a href, etc) and links to resource requisites quite differently, remappings jump-links to normal --to destination paths, while remapping resource requisites to their hash-based --content-to paths instead.
This renders identical HTML and CSS files referencing identical resources into identical results, which also saves quite a bit of space.
Note, however, that all of the above does make mirror slightly slower, since it needs to compute a lot of hashes and check contents of many files on disk.
It also requires hardlink support on the target file system.
Also, pointing --content-to outside of --to stops the mirrored results in --to from being self-contained.
Which is why you can disable all of this by specifying --copy:
hoardy-web mirror \
--to ~/hoardy-web/mirror10 \
--copy \
~/hoardy-web/raw
Also, you can make it use --symlinks instead of hardlinks.
Though, enabling --symlink also enables the --absolute option by default because browsers treat file:// URLs pointing to symlinks as redirects.
hoardy-web serve for archival and replay over HTTPhoardy-web comes with a builtin web server that can do
archival of WRR captures produced by the Hoardy-Web extension to disk;
i.e., it can play a role of an archiving server for Hoardy-Web, replacing the hoardy-web-sas simple archiving server;
replay of WRR and other supported file formats via Wayback Machine-esque URLs like http://127.0.0.1:3210/web/2/https://archiveofourown.org/works/3733123;
do both at the same time, allowing newly archived URLs to be replayed immediately (after the 200 OK response to the archiving POST).
In other words, hoardy-web serve is, essentially, a combination of hoardy-web-sas archiving server and an on-demand hoardy-web mirror which talks over HTTP instead of just dumping rendered documents to disk.
For interactive use, this is not only more convenient than hoardy-web mirror, it's also usually much faster since required URL rewrites are much cheaper and no recursive requisite resource rendering is required here.
That is, unlike mirror, serve is pretty snappy even on ancient hardware.
When invoking hoardy-web serve, the argument to the --archive-to option will be used by the archiving server parts, while the positional PATH arguments will used by the replay server parts.
That is,
hoardy-web serve \
--archive-to ~/hoardy-web/raw \
~/hoardy-web/raw/*/2024 \
../simple_server/pwebarc-dump \
~/Downloads/Hoardy-Web-export-* \
mitmproxy.*.dump
~/hoardy-web/raw/*/2024 and ../simple_server/pwebarc-dump,
as well as all files named ~/Downloads/Hoardy-Web-export-* (which are, usually, Hoardy-Web exports) and
files named mitmproxy.*.dump (which are probably mitmproxy dumps);~/hoardy-web/raw.When the argument to --archive-to and the first PATH are the same, you can specify --implicit --- or -i --- to simplify it:
hoardy-web serve --implicit --archive-to ~/hoardy-web/raw
# which is equivalent to
hoardy-web serve --archive-to ~/hoardy-web/raw ~/hoardy-web/raw
# which can be shortened to
hoardy-web serve -i --to ~/hoardy-web/raw
# or even
hoardy-web serve -i -t ~/hoardy-web/raw
By default, hoardy-web serve runs with an implied --all option, which makes it keep the index of all given archives in memory, allowing arbitrary visits to be replayed.
If you dislike this behaviour, you can run it with the --latest, --oldest, or --nearest options instead
hoardy-web serve --latest -i -t ~/hoardy-web/raw
# or
hoardy-web serve --oldest -i -t ~/hoardy-web/raw
# or
hoardy-web serve --nearest 2024-06-01 -i -t ~/hoardy-web/raw
which, for each URL, will make hoardy-web serve keep and allow replay of the last, the first, or the one closest to the given timestamp, respectively.
This greatly improves resource consumption, but it also has the same caveats as hoardy-web mirror --latest, --oldest, and --nearest (see above).
When running with both --latest and archiving enabled, newly archived WRRs will elide older ones from the index, thus making that hoardy-web serve instance serve only the freshest archived version of each URL.
You can also disable indexing and replay completely by running it with --no-replay
hoardy-web serve --no-replay --to ~/hoardy-web/raw
which will make it essentially equivalent to hoardy-web-sas, except for serve having a customizable --output format.
The listening address and port can be controlled with --host and --port options, exactly the same as hoardy-web-sas:
hoardy-web serve --host 127.0.10.1 --port 4321 --archive-to ~/hoardy-web/raw
Currently enabled features can be queried programmatically from /hoardy-web/server-info endpoint
curl 'http://127.0.0.1:3210/hoardy-web/server-info'
which returns a JSON like
{"version": 1, "dump_wrr": "/pwebarc/dump", "index_ideal": null, "replay_oldest": "/web/-inf/{url}", "replay_latest": "/web/+inf/{url}", "replay_any": "/web/{timestamp}/{url}"}
WRR files, listen to them via TTS, open them with xdg-open, etcSee the script sub-directory for examples that show how to use pandoc and/or w3m to turn WRR files into previews and readable plain-text that can viewed or listened to via other tools, or dump them into temporary raw data files that can then be immediately fed to xdg-open for one-click viewing.
Inspect, search, organize, programmatically extract values and generate static website mirrors from, archive, view, and replay HTTP archives/dumps in WRR ("Web Request+Response", produced by the Hoardy-Web Web Extension browser add-on) and mitmproxy (mitmdump) file formats.
Glossary: a reqres (Reqres when a Python type) is an instance of a structure representing HTTP request+response pair with some additional metadata.
options:
--version
: show program's version number and exit-h, --help
: show this help message and exit--markdown
: show help messages formatted in Markdownsubcommands:
{pprint,print,inspect,get,run,spawn,stream,find,organize,import,mirror,serve}
pprint (print, inspect)
: pretty-print given inputsget
: print values produced by evaluating given expressions on a given inputrun (spawn)
: spawn a process with temporary files generated from given expressions evaluated on given inputsstream
: stream lists containing values produced by evaluating given expressions on given inputs, a generalized hoardy-web getfind
: print paths of inputs matching specified criteriaorganize
: programmatically copy/rename/move/hardlink/symlink given input files based on their metadata and/or contentsimport
: convert other HTTP archive formats into WRRmirror
: convert given inputs into a local offline static website mirror stored in interlinked files, a-la wget -mpkserve
: run an archiving server and/or serve given input files for replay over HTTPfiltering options:
--ignore-case
: when filtering with --*grep*, match case-insensitively--case-sensitive
: when filtering with --*grep*, match case-sensitively--smart-case
: when filtering with --*grep*, match case-insensitively if there are no uppercase letters in the corresponding *PATTERN* option argument and case-sensitively otherwise; defaultinput filters; if none are specified, then all reqres from input PATHs will be taken; can be specified multiple times in arbitrary combinations; the resulting logical expression that will be checked is all_of(before) and all_of(not_before) and all_of(after) and all_of(not_after) and any_of(protocol) and not any_of(not_protcol) and any_of(request_method) and not any_of(not_request_method) ... and any_of(grep) and not any_of(not_grep) and all_of(and_grep) and not all_of(not_and_grep) and all_of(ands) and any_of(ors):
--before DATE
: accept reqres for processing when its stime is smaller than this; the DATE can be specified either as a number of seconds since UNIX epoch using @<number> format where <number> can be a floating point, or using one of the following formats:YYYY-mm-DD HH:MM:SS[.NN*] (+|-)HHMM, YYYY-mm-DD HH:MM:SS[.NN*], YYYY-mm-DD HH:MM:SS, YYYY-mm-DD HH:MM, YYYY-mm-DD, YYYY-mm, YYYY; if no (+|-)HHMM part is specified, the DATE is assumed to be in local time; if other parts are unspecified they are inherited from <year>-01-01 00:00:00.0--not-before DATE
: accept reqres for processing when its stime is larger or equal than this; the DATE format is the same as above--after DATE
: accept reqres for processing when its stime is larger than this; the DATE format is the same as above--not-after DATE
: accept reqres for processing when its stime is smaller or equal than this; the DATE format is the same as above--protocol PROTOCOL
: accept reqres for processing when one of the given PROTOCOL option arguments is equal to its protocol (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--protocol-prefix PROTOCOL_PREFIX
: accept reqres for processing when one of the given PROTOCOL_PREFIX option arguments is a prefix of its protocol (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--protocol-re PROTOCOL_RE
: accept reqres for processing when one of the given PROTOCOL_RE regular expressions matches its protocol (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--not-protocol NOT_PROTOCOL
: accept reqres for processing when none of the given NOT_PROTOCOL option arguments are equal to its protocol (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--not-protocol-prefix NOT_PROTOCOL_PREFIX
: accept reqres for processing when none of the given NOT_PROTOCOL_PREFIX option arguments are a prefix of its protocol (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--not-protocol-re NOT_PROTOCOL_RE
: accept reqres for processing when none of the given NOT_PROTOCOL_RE regular expressions match its protocol (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a blacklisted element rule--request-method REQUEST_METHOD, --method REQUEST_METHOD
: accept reqres for processing when one of the given REQUEST_METHOD option arguments is equal to its request.method (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--request-method-prefix REQUEST_METHOD_PREFIX, --method-prefix REQUEST_METHOD_PREFIX
: accept reqres for processing when one of the given REQUEST_METHOD_PREFIX option arguments is a prefix of its request.method (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--request-method-re REQUEST_METHOD_RE, --method-re REQUEST_METHOD_RE
: accept reqres for processing when one of the given REQUEST_METHOD_RE regular expressions matches its request.method (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--not-request-method NOT_REQUEST_METHOD, --not-method NOT_REQUEST_METHOD
: accept reqres for processing when none of the given NOT_REQUEST_METHOD option arguments are equal to its request.method (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--not-request-method-prefix NOT_REQUEST_METHOD_PREFIX
: accept reqres for processing when none of the given NOT_REQUEST_METHOD_PREFIX option arguments are a prefix of its request.method (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--not-request-method-re NOT_REQUEST_METHOD_RE
: accept reqres for processing when none of the given NOT_REQUEST_METHOD_RE regular expressions match its request.method (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a blacklisted element rule--status STATUS
: accept reqres for processing when one of the given STATUS option arguments is equal to its status (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--status-prefix STATUS_PREFIX
: accept reqres for processing when one of the given STATUS_PREFIX option arguments is a prefix of its status (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--status-re STATUS_RE
: accept reqres for processing when one of the given STATUS_RE regular expressions matches its status (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--not-status NOT_STATUS
: accept reqres for processing when none of the given NOT_STATUS option arguments are equal to its status (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--not-status-prefix NOT_STATUS_PREFIX
: accept reqres for processing when none of the given NOT_STATUS_PREFIX option arguments are a prefix of its status (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--not-status-re NOT_STATUS_RE
: accept reqres for processing when none of the given NOT_STATUS_RE regular expressions match its status (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a blacklisted element rule--url URL
: accept reqres for processing when one of the given URL option arguments is equal to its net_url (of hoardy-web get --expr, which see); Punycode UTS46 IDNAs, plain UNICODE IDNAs, percent-encoded URL components, and UNICODE URL components in arbitrary mixes and combinations are allowed; e.g. https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ will be silently normalized into its Punycode UTS46 and percent-encoded version of https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, which will then be matched against; in short, this option defines a whitelisted element rule--url-prefix URL_PREFIX
: accept reqres for processing when one of the given URL_PREFIX option arguments is a prefix of its net_url (of hoardy-web get --expr, which see); similarly to the previous option, arbitrary mixes of URL encodinds are allowed; in short, this option defines a whitelisted element rule--url-re URL_RE
: accept reqres for processing when one of the given URL_RE regular expressions matches its net_url or pretty_net_url (of hoardy-web get --expr, which see); only Punycode UTS46 IDNAs with percent-encoded URL components or plain UNICODE IDNAs with UNICODE URL components are allowed; regular expressions that use mixes of differently encoded parts will fail to match properly; this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--not-url NOT_URL
: accept reqres for processing when none of the given NOT_URL option arguments are equal to its net_url (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--not-url-prefix NOT_URL_PREFIX
: accept reqres for processing when none of the given NOT_URL_PREFIX option arguments are a prefix of its net_url (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--not-url-re NOT_URL_RE
: accept reqres for processing when none of the given NOT_URL_RE regular expressions match its net_url or pretty_net_url (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--request-headers-or-grep OR_PATTERN, --request-headers-grep OR_PATTERN
: accept reqres for processing when at least one of the given OR_PATTERN option arguments is a substring of at least one of the elements of the list containing all request.headers (of hoardy-web get --expr, which see); each HTTP header of *.headers is matched as a single <header_name>: <header_value> value; at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--request-headers-or-grep-re OR_PATTERN_RE, --request-headers-grep-re OR_PATTERN_RE
: accept reqres for processing when at least one of the given OR_PATTERN_RE regular expressions matches a substring of at least one of the elements of the above list; matching caveats are the same as above; in short, this option defines a whitelisted element rule--not-request-headers-or-grep NOT_OR_PATTERN, --not-request-headers-grep NOT_OR_PATTERN
: accept reqres for processing when none of the given NOT_OR_PATTERN option arguments are substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--not-request-headers-or-grep-re NOT_OR_PATTERN_RE, --not-request-headers-grep-re NOT_OR_PATTERN_RE
: accept reqres for processing when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--request-headers-and-grep AND_PATTERN
: accept reqres for processing when each of the given AND_PATTERN option arguments is a substring of some element of the above list; matching caveats are the same as above--request-headers-and-grep-re AND_PATTERN_RE
: accept reqres for processing when each of the given AND_PATTERN_RE regular expressions matches a substring of some element of the above list; matching caveats are the same as above--not-request-headers-and-grep NOT_AND_PATTERN
: accept reqres for processing when one or more of the given NOT_AND_PATTERN option arguments is not a substring of the elements of the above list; matching caveats are the same as above--not-request-headers-and-grep-re NOT_AND_PATTERN_RE
: accept reqres for processing when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of the elements of the above list; matching caveats are the same as above--request-body-or-grep OR_PATTERN, --request-body-grep OR_PATTERN
: accept reqres for processing when at least one of the given OR_PATTERN option arguments is a substring of request.body (of hoardy-web get --expr, which see); at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--request-body-or-grep-re OR_PATTERN_RE, --request-body-grep-re OR_PATTERN_RE
: accept reqres for processing when at least one of the given OR_PATTERN_RE regular expressions matches a substring of request.body; matching caveats are the same as above; in short, this option defines a whitelisted element rule--not-request-body-or-grep NOT_OR_PATTERN, --not-request-body-grep NOT_OR_PATTERN
: accept reqres for processing when none of the given NOT_OR_PATTERN option arguments are substrings of request.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--not-request-body-or-grep-re NOT_OR_PATTERN_RE, --not-request-body-grep-re NOT_OR_PATTERN_RE
: accept reqres for processing when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of request.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--request-body-and-grep AND_PATTERN
: accept reqres for processing when each of the given AND_PATTERN option arguments is a substring of request.body; matching caveats are the same as above--request-body-and-grep-re AND_PATTERN_RE
: accept reqres for processing when each of the given AND_PATTERN_RE regular expressions matches a substring of request.body; matching caveats are the same as above--not-request-body-and-grep NOT_AND_PATTERN
: accept reqres for processing when one or more of the given NOT_AND_PATTERN option arguments is not a substring of request.body; matching caveats are the same as above--not-request-body-and-grep-re NOT_AND_PATTERN_RE
: accept reqres for processing when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of request.body; matching caveats are the same as above--request-mime REQUEST_MIME
: accept reqres for processing when one of the given REQUEST_MIME option arguments is equal to its request_mime (of hoardy-web get --expr, which see); both canonical and non-canonical MIME types are allowed; e.g., giving application/x-grip or application/gzip will produce the same predicate; in short, this option defines a whitelisted element rule--request-mime-prefix REQUEST_MIME_PREFIX
: accept reqres for processing when one of the given REQUEST_MIME_PREFIX option arguments is a prefix of its request_mime (of hoardy-web get --expr, which see); given prefixes will only ever be matched against canonicalized MIME types; in short, this option defines a whitelisted element rule--request-mime-re REQUEST_MIME_RE
: accept reqres for processing when one of the given REQUEST_MIME_RE regular expressions matches its request_mime (of hoardy-web get --expr, which see); given regular expressions will only ever be matched against canonicalized MIME types; this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--not-request-mime NOT_REQUEST_MIME
: accept reqres for processing when none of the given NOT_REQUEST_MIME option arguments are equal to its request_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--not-request-mime-prefix NOT_REQUEST_MIME_PREFIX
: accept reqres for processing when none of the given NOT_REQUEST_MIME_PREFIX option arguments are a prefix of its request_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--not-request-mime-re NOT_REQUEST_MIME_RE
: accept reqres for processing when none of the given NOT_REQUEST_MIME_RE regular expressions match its request_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--response-headers-or-grep OR_PATTERN, --response-headers-grep OR_PATTERN
: accept reqres for processing when at least one of the given OR_PATTERN option arguments is a substring of at least one of the elements of the list containing all response.headers (of hoardy-web get --expr, which see); each HTTP header of *.headers is matched as a single <header_name>: <header_value> value; at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--response-headers-or-grep-re OR_PATTERN_RE, --response-headers-grep-re OR_PATTERN_RE
: accept reqres for processing when at least one of the given OR_PATTERN_RE regular expressions matches a substring of at least one of the elements of the above list; matching caveats are the same as above; in short, this option defines a whitelisted element rule--not-response-headers-or-grep NOT_OR_PATTERN, --not-response-headers-grep NOT_OR_PATTERN
: accept reqres for processing when none of the given NOT_OR_PATTERN option arguments are substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--not-response-headers-or-grep-re NOT_OR_PATTERN_RE, --not-response-headers-grep-re NOT_OR_PATTERN_RE
: accept reqres for processing when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--response-headers-and-grep AND_PATTERN
: accept reqres for processing when each of the given AND_PATTERN option arguments is a substring of some element of the above list; matching caveats are the same as above--response-headers-and-grep-re AND_PATTERN_RE
: accept reqres for processing when each of the given AND_PATTERN_RE regular expressions matches a substring of some element of the above list; matching caveats are the same as above--not-response-headers-and-grep NOT_AND_PATTERN
: accept reqres for processing when one or more of the given NOT_AND_PATTERN option arguments is not a substring of the elements of the above list; matching caveats are the same as above--not-response-headers-and-grep-re NOT_AND_PATTERN_RE
: accept reqres for processing when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of the elements of the above list; matching caveats are the same as above--response-body-or-grep OR_PATTERN, --response-body-grep OR_PATTERN
: accept reqres for processing when at least one of the given OR_PATTERN option arguments is a substring of response.body (of hoardy-web get --expr, which see); at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--response-body-or-grep-re OR_PATTERN_RE, --response-body-grep-re OR_PATTERN_RE
: accept reqres for processing when at least one of the given OR_PATTERN_RE regular expressions matches a substring of response.body; matching caveats are the same as above; in short, this option defines a whitelisted element rule--not-response-body-or-grep NOT_OR_PATTERN, --not-response-body-grep NOT_OR_PATTERN
: accept reqres for processing when none of the given NOT_OR_PATTERN option arguments are substrings of response.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--not-response-body-or-grep-re NOT_OR_PATTERN_RE, --not-response-body-grep-re NOT_OR_PATTERN_RE
: accept reqres for processing when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of response.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--response-body-and-grep AND_PATTERN
: accept reqres for processing when each of the given AND_PATTERN option arguments is a substring of response.body; matching caveats are the same as above--response-body-and-grep-re AND_PATTERN_RE
: accept reqres for processing when each of the given AND_PATTERN_RE regular expressions matches a substring of response.body; matching caveats are the same as above--not-response-body-and-grep NOT_AND_PATTERN
: accept reqres for processing when one or more of the given NOT_AND_PATTERN option arguments is not a substring of response.body; matching caveats are the same as above--not-response-body-and-grep-re NOT_AND_PATTERN_RE
: accept reqres for processing when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of response.body; matching caveats are the same as above--response-mime RESPONSE_MIME
: accept reqres for processing when one of the given RESPONSE_MIME option arguments is equal to its response_mime (of hoardy-web get --expr, which see); both canonical and non-canonical MIME types are allowed; e.g., giving application/x-grip or application/gzip will produce the same predicate; in short, this option defines a whitelisted element rule--response-mime-prefix RESPONSE_MIME_PREFIX
: accept reqres for processing when one of the given RESPONSE_MIME_PREFIX option arguments is a prefix of its response_mime (of hoardy-web get --expr, which see); given prefixes will only ever be matched against canonicalized MIME types; in short, this option defines a whitelisted element rule--response-mime-re RESPONSE_MIME_RE
: accept reqres for processing when one of the given RESPONSE_MIME_RE regular expressions matches its response_mime (of hoardy-web get --expr, which see); given regular expressions will only ever be matched against canonicalized MIME types; this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--not-response-mime NOT_RESPONSE_MIME
: accept reqres for processing when none of the given NOT_RESPONSE_MIME option arguments are equal to its response_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--not-response-mime-prefix NOT_RESPONSE_MIME_PREFIX
: accept reqres for processing when none of the given NOT_RESPONSE_MIME_PREFIX option arguments are a prefix of its response_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--not-response-mime-re NOT_RESPONSE_MIME_RE
: accept reqres for processing when none of the given NOT_RESPONSE_MIME_RE regular expressions match its response_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--or-grep OR_PATTERN, --grep OR_PATTERN
: accept reqres for processing when at least one of the given OR_PATTERN option arguments is a substring of at least one of the elements of the list containing raw_url, url, pretty_url, all request.headers, request.body, all response.headers, and response.body (of hoardy-web get --expr, which see); each HTTP header of *.headers is matched as a single <header_name>: <header_value> value; at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--or-grep-re OR_PATTERN_RE, --grep-re OR_PATTERN_RE
: accept reqres for processing when at least one of the given OR_PATTERN_RE regular expressions matches a substring of at least one of the elements of the above list; matching caveats are the same as above; in short, this option defines a whitelisted element rule--not-or-grep NOT_OR_PATTERN, --not-grep NOT_OR_PATTERN
: accept reqres for processing when none of the given NOT_OR_PATTERN option arguments are substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--not-or-grep-re NOT_OR_PATTERN_RE, --not-grep-re NOT_OR_PATTERN_RE
: accept reqres for processing when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--and-grep AND_PATTERN
: accept reqres for processing when each of the given AND_PATTERN option arguments is a substring of some element of the above list; matching caveats are the same as above--and-grep-re AND_PATTERN_RE
: accept reqres for processing when each of the given AND_PATTERN_RE regular expressions matches a substring of some element of the above list; matching caveats are the same as above--not-and-grep NOT_AND_PATTERN
: accept reqres for processing when one or more of the given NOT_AND_PATTERN option arguments is not a substring of the elements of the above list; matching caveats are the same as above--not-and-grep-re NOT_AND_PATTERN_RE
: accept reqres for processing when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of the elements of the above list; matching caveats are the same as above--and EXPR
: accept reqres for processing when all of the given expressions of the same format as hoardy-web get --expr (which see) evaluate to true--or EXPR
: accept reqres for processing when some of the given expressions of the same format as hoardy-web get --expr (which see) evaluate to truePretty-print given inputs to stdout.
options:
-q, --quiet
: don't print end-of-filtering warnings to stderr-u, --unabridged
: print all data in full--abridged
: shorten long strings for brevity, useful when you want to visually scan through batch data dumps; defaulterror handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command this simply populates the potentially lists in the output in various ways:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptPrint results produced by evaluating given EXPRessions on a given input to stdout.
Algorithm:
PATH;EXPR expressions on the resulting reqres;The end.
positional arguments:
PATH
: input WRR file pathMIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command higher values make the scrub function (which see) censor out more things when -unknown, -styles, or -scripts options are set; in particular, at the moment, with --sniff-paranoid and -scripts most plain text files will be censored out as potential JavaScript:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptexpression evaluation:
--expr-fd INT
: file descriptor to which the results of evaluations of the following --exprs computations should be written; can be specified multiple times, thus separating different --exprs into different output streams; default: 1, i.e. stdout-e EXPR, --expr EXPR
: an expression to compute; can be specified multiple times in which case computed outputs will be printed sequentially (see also "printing" options below); the default depends on options below; each EXPR describes a state-transformer (pipeline) which starts from value None and evaluates a script built from the following:
es: replace None value with an empty string ""eb: replace None value with an empty byte string b""false: replace None value with Falsetrue: replace None value with Truemissing: True if the value is None0: replace None value with 01: replace None value with 1not: apply logical not to valuelen: apply len to valuestr: cast value to str or failbytes: cast value to bytes or failbool: cast value to bool or failint: cast value to int or failfloat: cast value to float or failecho: replace the value with the given stringquote: URL-percent-encoding quote valuequote_plus: URL-percent-encoding quote value and replace spaces with + symbolsunquote: URL-percent-encoding unquote valueunquote_plus: URL-percent-encoding unquote value and replace + symbols with spacesto_ascii: encode str value into bytes with "ascii" codec, do nothing if the value is already bytesto_utf8: encode str value into bytes with "utf-8" codec, do nothing if the value is already bytesto_hex: replace bytes value with its hexadecimal str representationfrom_hex: replace hexadecimal str value with its decoded bytes valuesha256: replace bytes value with its sha256 hash digest~=: check if the current value matches the regular exprission arg==: apply == arg, arg is cast to the same type as the current value!=: apply != arg, similarly<: apply < arg, similarly<=: apply <= arg, similarly>: apply > arg, similarly>=: apply >= arg, similarlyadd_prefix: add prefix to the current valueadd_suffix: add suffix to the current valuetake_prefix: take first arg characters or list elements from the current valuetake_suffix: take last arg characters or list elements from the current valueabbrev: leave the current value as-is if if its length is less or equal than arg characters, otherwise take first arg/2 followed by last arg/2 charactersabbrev_each: abbrev arg each element in a value listreplace: replace all occurences of the first argument in the current value with the second argument, casts arguments to the same type as the current valueparse_path: parse a URL path component str into path_parts listunparse_path: encode path_parts list into a URL path component strparse_query: parse a URL query component str into query_parts listunparse_query: encode query_parts list into a URL query component strpp_to_path: encode *path_parts list into a POSIX path, quoting as little as neededqsl_to_path: encode query_parts list into a POSIX path, quoting as little as neededscrub: scrub the value by optionally rewriting links and/or removing dynamic content from it; what gets done depends on the MIME type of the value itself and the scrubbing options described below; this function takes two arguments:
- the first must be either of request|response, it controls which HTTP headers scrub should inspect to help it detect the MIME type;
- the second is either defaults or ","-separated string of tokens which control the scrubbing behaviour:
- (+|-|*|/|&)jumps controls how jump-links (a href, area href, and similar HTML tag attributes) should be remapped or censored out:
- + rewrites their values into full URLs, e.g. <a href="/path?query"> -> <a href="https://example.org/path?query">;
- - "voids" all of them, i.e. rewrites them to javascript:void(0) and empty data: URLs;
- * rewrites links in an "open"-ended way, i.e. points them to locally mirrored versions of their URLs when available and leaves them pointing to their original URL otherwise; this is only supported when scrub is used with mirror sub-command; under other sub-commands this is equivalent to +;
- / rewrites links in a "close"-ended way, i.e. points them to locally mirrored versions of their URLs when available and voids them otherwise; this is only supported when scrub is used with mirror sub-command; under other sub-commands this is equivalent to -;
- & rewrites links in a "close"-ended way like / does, except this option uses fallbacks to remap unavailable URLs whenever possible; this is only supported when scrub is used with mirror sub-command; under other sub-commands this is equivalent to -; see the documentation of the --remap-all option for more info;
- (+|-|*|/|&)actions controls how action-links (a ping, form action, and similar HTML tag attributes) should be remapped or censored out; same rewrite options as above;
- (+|-|*|/|&)reqs controls how references to page requisites (img src, iframe src, and similar HTML tag attributes, as well as link src attributes which have rel attribute of their HTML tag set to stylesheet or icon, CSS url references, etc) should be remapped or censored out; same rewrite options as above;
- (+|-|*|/|&)all_refs is equivalent to setting all of jumps, actions, and reqs simultaneously;
- (+|-)styles controls whether CSS stylesheets (both separate files and HTML tags and attributes) should be kept in or censored out;
- (+|-)scripts controls whether JavaScript (both separate files and HTML tags and attributes) should be kept in or censored out;
- (+|-)iepragmas controls whether Internet Explorer's HTML pragmas should be kept in or censored out;
- (+|-)iframes controls whether <iframe> HTML tags should be kept in or censored out;
- (+|-)prefetches controls whether HTML content prefetch link tags should be kept in or censored out;
- (+|-)tracking controls whether other tracking HTML tags and attributes (like a ping) should be kept in or censored out;
- (+|-)navigations controls whether automatic navigations (Refresh HTTP headers and <meta http-equiv> HTML tags) should be kept in or censored out;
- (+|-)all_dyns is equivalent to setting all of styles, scripts, iepragmas, iframes, prefetches, tracking, and navigations simultaneously;
- (+|-)inline_headers controls whether certain HTTP headers (Content-Security-Policy, Default-Style, Link, Refresh, and X-UA-Compatible) should be inlined as <meta http-equiv=*> HTML tags;
scrub will then interpret the contents of and process those tags as usual, as if they were present in the document to begin with;
- (+|-)inline_fallback_icon controls whether <link rel="icon" href="/favicon.ico"> HTML tag browsers use as a fallback when a page does not declare any icons should be made explicit and inlined into the result; that URL will then get remapped like a normal page requisite using reqs and the tag will not be added if that /favicon.ico URL gets remapped into void;
- (+|-)interpret_noscript controls whether the contents of noscript tags should be inlined when -scripts is set;
- (+|-)unknown controls if the data with unknown content types should passed to the output unchanged or censored out (respectively);
- (+|-)verbose controls whether tag censoring controlled by the above options is to be reported in the output (as comments) or stuff should be wiped from existence without evidence instead;
- (+|-)whitespace controls whether HTML and CSS renderers should keep the original whitespace as-is or collapse it away;
- (+|-)optional_tags controls whether HTML renderer should put optional HTML tags into the output or skip them;
- (+|-)indent controls whether HTML and CSS renderers should indent their outputs (where whitespace placement in the original markup allows for it) or not;
- +pretty is an alias for -whitespace,+indent which produces the prettiest possible human-readable output that keeps the original whitespace semantics;
- -pretty is an alias for +whitespace,-indent which produces the approximation of the original markup with censoring applied;
- +debug is a variant of +pretty that also uses a much more aggressive version of indent that ignores the semantics of original whitespace placement, i.e. it indents <p>not<em>sep</em>arated</p> as if there was whitespace before and after p, em, /em, and /p tags; this is useful for debugging;
- -debug is a noop;
- the defaults are:
- *jumps,&actions,&reqs, because these produce a self-contained result that can be fed into another tool --- be it a web browser or pandoc --- without that tool trying to access the Internet;
- -prefetches,-tracking,-navigations, because these ensure the result will not try to prefetch or track anything, or re-navigate elsewhere, when loaded in a web browser;
- +styles,+iframes, because these are are scrubbed properly;
- -scripts, because scrubbing of JavaScript (code whitelisting) is not supported yet;
- -iepragmas, because censoring of contents of such pragmas is not supported yet;
- +inline_headers, because otherwise the result won't be self-contained;
- +inline_fallback_icon when reqs is / or &, -interpret_favicon otherwise;
i.e., by default, scrub inlines fallback favicons if they remap to something non-void and keep the result self-contained;
- +interpret_noscript, because this usually helps;
- +verbose, because this allows you to inspect the generated output and see what hoardy-web did to it, i.e., this minimizes surprises;
- +whitespace,-indent, to keep the output as close to the original as possible;
- +optional_tags, because many tools fail to parse minimized HTML properly;
- +unknown which keeps data of unknown content MIME types as-is;
- note however, that most --remap-* options set different defaults;None with field's value, if reqres is missing the field in question, which could happen for response* fields, the result is None:
version: WEBREQRES format version; intagent: +-separated list of applications that produced this reqres; strprotocol: protocol; e.g. "HTTP/1.1", "HTTP/2.0"; strrequest.started_at: request start time in seconds since 1970-01-01 00:00; Timestamprequest.method: request HTTP method; e.g. "GET", "POST", etc; strrequest.url: request URL, including the fragment/hash part; strrequest.headers: request headers; list[tuple[str, bytes]]request.complete: is request body complete?; boolrequest.body: request body; bytesresponse.started_at: response start time in seconds since 1970-01-01 00:00; Timestampresponse.code: HTTP response code; e.g. 200, 404, etc; intresponse.reason: HTTP response reason; e.g. "OK", "Not Found", etc; usually empty for Chromium and filled for Firefox; strresponse.headers: response headers; list[tuple[str, bytes]]response.complete: is response body complete?; boolresponse.body: response body; Firefox gives raw bytes, Chromium gives UTF-8 encoded strings; bytes | strfinished_at: request completion time in seconds since 1970-01-01 00:00; Timestampwebsocket: a list of WebSocket framesfs_path: file system path for the WRR file containing this reqres; str | bytes | Noneraw_url: aliast for request.url; strmethod: aliast for request.method; strqtime: aliast for request.started_at; mnemonic: "reQuest TIME"; seconds since UNIX epoch; Timestampqtime_ms: qtime in milliseconds rounded down to nearest integer; milliseconds since UNIX epoch; intqtime_msq: three least significant digits of qtime_ms; intqyear: year number of gmtime(qtime) (UTC year number of qtime); intqmonth: month number of gmtime(qtime); intqday: day of the month of gmtime(qtime); intqhour: hour of gmtime(qtime) in 24h format; intqminute: minute of gmtime(qtime); intqsecond: second of gmtime(qtime); intstime: response.started_at if there was a response, finished_at otherwise; mnemonic: "reSponse TIME"; seconds since UNIX epoch; Timestampstime_ms: stime in milliseconds rounded down to nearest integer; milliseconds since UNIX epoch; intstime_msq: three least significant digits of stime_ms; intsyear: similar to qyear, but for stime; intsmonth: similar to qmonth, but for stime; intsday: similar to qday, but for stime; intshour: similar to qhour, but for stime; intsminute: similar to qminute, but for stime; intssecond: similar to qsecond, but for stime; intftime: aliast for finished_at; seconds since UNIX epoch; Timestampftime_ms: ftime in milliseconds rounded down to nearest integer; milliseconds since UNIX epoch; intftime_msq: three least significant digits of ftime_ms; intfyear: similar to qyear, but for ftime; intfmonth: similar to qmonth, but for ftime; intfday: similar to qday, but for ftime; intfhour: similar to qhour, but for ftime; intfminute: similar to qminute, but for ftime; intfsecond: similar to qsecond, but for ftime; intnet_url: a variant of raw_url that uses Punycode UTS46 IDNA encoded net_hostname, has all unsafe characters of raw_path and raw_query quoted, and comes without the fragment/hash part; this is the URL that actually gets sent to an HTTP server when you request raw_url; strurl: net_url with fragment/hash part appended; strpretty_net_url: a variant of raw_url that uses UNICODE IDNA hostname without Punycode, minimally quoted mq_path and mq_query, and comes without the fragment/hash part; this is a human-readable version of net_url; strpretty_url: pretty_net_url with fragment/hash part appended; strpretty_net_nurl: a variant of pretty_net_url that uses mq_npath instead of mq_path and mq_nquery instead of mq_query; i.e. this is pretty_net_url with normalized path and query; strpretty_nurl: pretty_net_nurl with fragment/hash part appended; strscheme: scheme part of raw_url; e.g. http, https, etc; strraw_hostname: hostname part of raw_url as it is recorded in the reqres; strnet_hostname: hostname part of raw_url, encoded as Punycode UTS46 IDNA; this is what actually gets sent to the server; ASCII strhostname: net_hostname decoded back into UNICODE; this is the canonical hostname representation for which IDNA-encoding and decoding are bijective; UNICODE strrhostname: hostname with the order of its parts reversed; e.g. "www.example.org" -> "com.example.www"; strport: port part of raw_url; strnetloc: netloc part of raw_url; i.e., in the most general case, <username>:<password>@<hostname>:<port>; strraw_path: raw path part of raw_url as it is recorded is the reqres; e.g. "https://www.example.org" -> "", "https://www.example.org/" -> "/", "https://www.example.org/index.html" -> "/index.html"; strpath_parts: component-wise unquoted "/"-split raw_path; list[str]path: path_parts turned back into a quoted string, i.e. raw_path normalized like browsers do it; strnpath_parts: path_parts with empty components removed and dots and double dots interpreted away; e.g. "https://www.example.org" -> [], "https://www.example.org/" -> [], "https://www.example.org/index.html" -> ["index.html"] , "https://www.example.org/skipped/.//../used/" -> ["used"]; list[str]mq_path: path_parts turned back into a minimally-quoted string; strmq_npath: npath_parts turned back into a minimally-quoted string; strraw_query: query part of raw_url, i.e. everything after the ? character and before the # character; strquery_parts: parsed and component-wise unquoted raw_query; list[tuple[str, str | None]]query: query_parts turned back into a quoted string, i.e. raw_query normalized like browsers do it; strquery_nparts: query_parts with empty query parameters removed; list[tuple[str, str]]mq_query: query_parts turned back into a minimally-quoted string appropriate for use in filenames; strmq_nquery: query_ne_parts turned back into a minimally-quoted string appropriate for use in filenames; stroqm: optional query mark: ? character if query is non-empty, an empty string otherwise; strfragment: fragment (hash) part of the url; strofm: optional fragment mark: # character if fragment is non-empty, an empty string otherwise; strstatus: "I" or "C" for request.complete (I for false , C for true) followed by either "N" when response is None, or str(response.code) followed by "I" or "C" for response.complete; e.g. C200C (all "OK"), CN (request was sent, but it got no response), I200C (partial request with complete "OK" response), C200I (complete request with incomplete response, e.g. if download was interrupted), C404C (complete request with complete "Not Found" response), etc; strrequest_mime: request.body MIME type, note the underscore, this is not a field of request, this is a derived value that depends on request Content-Type header and --sniff* settings; str or Noneresponse_mime: response.body MIME type, note the underscore, this is not a field of response, this is a derived value that depends on response Content-Type header and --sniff* settings; str or Nonefilepath_parts: npath_parts transformed into components usable as an exportable file name; i.e. npath_parts with an optional additional "index" appended, depending on raw_url and response_mime; extension will be stored separately in filepath_ext; e.g. for HTML documents "https://www.example.org/" -> ["index"], "https://www.example.org/test.html" -> ["test"], "https://www.example.org/test" -> ["test", "index"], "https://www.example.org/test.json" -> ["test.json", "index"], but if it has a JSON MIME type then "https://www.example.org/test.json" -> ["test"] (and filepath_ext will be set to ".json"); this is similar to what wget -mpk does, but a bit smarter; list[str]filepath_ext: extension of the last component of filepath_parts for recognized MIME types, ".data" otherwise; str|) the above, for example:
response.body|eb (the default for get and run) will print raw response.body or an empty byte string, if there was no response;response.body|eb|scrub response defaults will take the above value, scrub it using default content scrubbing settings which will censor out all actions and references to page requisites;response.complete will print the value of response.complete or None, if there was no response;response.complete|false will print response.complete or False;net_url|to_ascii|sha256|to_hex will print a hexadecimal representation of the sha256 hash of the URL that was actually sent over the network;net_url|to_ascii|sha256|take_prefix 2|to_hex will print the first 2 bytes (4 characters) of the above;path_parts|take_prefix 3|pp_to_path will print first 3 path components of the URL, minimally quoted to be used as a path;query_ne_parts|take_prefix 3|qsl_to_path|abbrev 128 will print first 3 non-empty query parameters of the URL, abbreviated to 128 characters or less, minimally quoted to be used as a path;raw_url:
https://example.org -> https://example.orghttps://example.org/ -> https://example.org/https://example.org/index.html -> https://example.org/index.htmlhttps://example.org/media -> https://example.org/mediahttps://example.org/media/ -> https://example.org/media/https://example.org/view?one=1&two=2&three=&three=3#fragment -> https://example.org/view?one=1&two=2&three=&three=3#fragmenthttps://königsgäßchen.example.org/index.html -> https://königsgäßchen.example.org/index.htmlhttps://ジャジェメント.ですの.example.org/испытание/is/ -> https://ジャジェメント.ですの.example.org/испытание/is/https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/net_url:
https://example.org, https://example.org/ -> https://example.org/https://example.org/index.html -> https://example.org/index.htmlhttps://example.org/media -> https://example.org/mediahttps://example.org/media/ -> https://example.org/media/https://example.org/view?one=1&two=2&three=&three=3#fragment -> https://example.org/view?one=1&two=2&three=&three=3https://königsgäßchen.example.org/index.html -> https://xn--knigsgchen-b4a3dun.example.org/index.htmlhttps://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/pretty_url:
https://example.org, https://example.org/ -> https://example.org/https://example.org/index.html -> https://example.org/index.htmlhttps://example.org/media -> https://example.org/mediahttps://example.org/media/ -> https://example.org/media/https://example.org/view?one=1&two=2&three=&three=3#fragment -> https://example.org/view?one=1&two=2&three=&three=3#fragmenthttps://königsgäßchen.example.org/index.html -> https://königsgäßchen.example.org/index.htmlhttps://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https://ジャジェメント.ですの.example.org/испытание/is/pretty_nurl:
https://example.org, https://example.org/ -> https://example.org/https://example.org/index.html -> https://example.org/index.htmlhttps://example.org/media -> https://example.org/mediahttps://example.org/media/ -> https://example.org/media/https://example.org/view?one=1&two=2&three=&three=3#fragment -> https://example.org/view?one=1&two=2&three=3#fragmenthttps://königsgäßchen.example.org/index.html -> https://königsgäßchen.example.org/index.htmlhttps://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https://ジャジェメント.ですの.example.org/испытание/is/printing of --expr values:
--not-separated
: print --expr values without separating them with anything, just concatenate them-l, --lf-separated
: print --expr values separated with \n (LF) newline characters; default-z, --zero-separated
: print --expr values separated with \0 (NUL) bytesdefault value of --expr:
--raw-qbody
: set the default value of --expr to request.body|eb; i.e. produce the raw request body--raw-sbody, --no-remap
: set the default value of --expr to response.body|eb; i.e. produce the raw response body; default--remap-id
: set the default value of --expr to response.body|eb|scrub response +all_refs; i.e. scrub response body as follows: remap all URLs with an identity function (which, as a whole, is NOT an identity function, it will transform all relative URLs into absolute ones), censor out all dynamic content (e.g. JavaScript); results will NOT be self-contained--remap-void
: set the default value of --expr to response.body|eb|scrub response -all_refs; i.e. scrub response body as follows: remap all URLs into javascript:void(0) and empty data: URLs, censor out all dynamic content; results will be self-containedSpawn COMMAND with given static ARGuments and NUM additional arguments generated by evaluating given EXPRessions on given PATHs into temporary files.
Algorithm:
NUM given PATHs (--num-args decides the point at which argv get split into ARGs and PATHs);NUM resulting reqres:
EXPR expressions;COMMAND with given ARG arguments and NUM additional arguments that are paths of the files generated in the previous step,The end.
Essentially, this is {__prog__} get into a temporary file for each given PATH, followed by spawning of COMMAND, followed by cleanup when it finishes.
positional arguments:
COMMAND
: command to spawnARG
: static arguments to give to the COMMANDPATH
: input WRR file paths to be mapped into new temporary filesoptions:
-n NUM, --num-args NUM
: number of PATHs; default: 1MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command higher values make the scrub function (which see) censor out more things when -unknown, -styles, or -scripts options are set; in particular, at the moment, with --sniff-paranoid and -scripts most plain text files will be censored out as potential JavaScript:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptexpression evaluation:
-e EXPR, --expr EXPR
: an expression to compute, same expression format and semantics as hoardy-web get --expr (which see); can be specified multiple times; the default depends on --remap-* options belowprinting of --expr values:
--not-separated
: print --expr values without separating them with anything, just concatenate them-l, --lf-separated
: print --expr values separated with \n (LF) newline characters; default-z, --zero-separated
: print --expr values separated with \0 (NUL) bytesdefault value of --expr:
--raw-qbody
: set the default value of --expr to request.body|eb; i.e. produce the raw request body--raw-sbody, --no-remap
: set the default value of --expr to response.body|eb; i.e. produce the raw response body; default--remap-id
: set the default value of --expr to response.body|eb|scrub response +all_refs; i.e. scrub response body as follows: remap all URLs with an identity function (which, as a whole, is NOT an identity function, it will transform all relative URLs into absolute ones), censor out all dynamic content (e.g. JavaScript); results will NOT be self-contained--remap-void
: set the default value of --expr to response.body|eb|scrub response -all_refs; i.e. scrub response body as follows: remap all URLs into javascript:void(0) and empty data: URLs, censor out all dynamic content; results will be self-containedStream lists of results produced by evaluating given EXPRessions on given inputs to stdout.
Algorithm:
PATH:
EXPR expressions on the resulting reqres;FORMAT;The end.
Esentially, this is a generalized {__prog__} get.
options:
-q, --quiet
: don't print end-of-filtering warnings to stderr-u, --unabridged
: print all data in full--abridged
: shorten long strings for brevity, useful when you want to visually scan through batch data dumps; default--format FORMAT
: generate output in:
repr; defaultCBOR (RFC8949)JSON; binary data can't be represented, UNICODE replacement characters will be used*-terminated optionserror handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command higher values make the scrub function (which see) censor out more things when -unknown, -styles, or -scripts options are set; in particular, at the moment, with --sniff-paranoid and -scripts most plain text files will be censored out as potential JavaScript:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptexpression evaluation:
-e EXPR, --expr EXPR
: an expression to compute, same expression format and semantics as hoardy-web get --expr (which see); can be specified multiple times; the default depends on --remap-* options below--format=raw --expr printing:
--not-terminated
: print --format=raw --expr output values without terminating them with anything, just concatenate them-l, --lf-terminated
: print --format=raw --expr output values terminated with \n (LF) newline characters; default-z, --zero-terminated
: print --format=raw --expr output values terminated with \0 (NUL) bytesdefault value of --expr:
--structure
: set the default value of --expr to .; i.e. dump the whole structure; default--raw-qbody
: set the default value of --expr to request.body|eb; i.e. produce the raw request body--raw-sbody, --no-remap
: set the default value of --expr to response.body|eb; i.e. produce the raw response body--remap-id
: set the default value of --expr to response.body|eb|scrub response +all_refs; i.e. scrub response body as follows: remap all URLs with an identity function (which, as a whole, is NOT an identity function, it will transform all relative URLs into absolute ones), censor out all dynamic content (e.g. JavaScript); results will NOT be self-contained--remap-void
: set the default value of --expr to response.body|eb|scrub response -all_refs; i.e. scrub response body as follows: remap all URLs into javascript:void(0) and empty data: URLs, censor out all dynamic content; results will be self-containedPrint paths of inputs matching specified criteria.
Algorithm:
PATH:
The end.
options:
-q, --quiet
: don't print end-of-filtering warnings to stderrerror handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command higher values make the scrub function (which see) censor out more things when -unknown, -styles, or -scripts options are set; in particular, at the moment, with --sniff-paranoid and -scripts most plain text files will be censored out as potential JavaScript:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptfound files printing:
-l, --lf-terminated
: print absolute paths of matching WRR files terminated with \n (LF) newline characters; default-z, --zero-terminated
: print absolute paths of matching WRR files terminated with \0 (NUL) bytesProgrammatically copy/rename/move/hardlink/symlink given input files based on their metadata and/or contents.
Algorithm:
PATH:
OUTPUT_DESTINATION with the new path derived from each reqres' metadata.The end.
Operations that could lead to accidental data loss are not permitted.
E.g. hoardy-web organize --move will not overwrite any files, which is why the default --output contains %(num)d.
options:
--dry-run
: perform a trial run without actually performing any changes-q, --quiet
: don't log computed updates and don't print end-of-filtering warnings to stderrcaching, deferring, and batching:
--seen-number INT
: track at most this many distinct generated --output values; default: 16384;
making this larger improves disk performance at the cost of increased memory consumption;
setting it to zero will force force hoardy-web to constantly re-check existence of --output files and force hoardy-web to execute all IO actions immediately, disregarding --defer-number setting--cache-number INT
: cache stat(2) information about this many files in memory; default: 8192;
making this larger improves performance at the cost of increased memory consumption;
setting this to a too small number will likely force hoardy-web into repeatedly performing lots of stat(2) system calls on the same files;
setting this to a value smaller than --defer-number will not improve memory consumption very much since deferred IO actions also cache information about their own files--defer-number INT
: defer at most this many IO actions; default: 1024;
making this larger improves performance at the cost of increased memory consumption;
setting it to zero will force all IO actions to be applied immediately--batch-number INT
: queue at most this many deferred IO actions to be applied together in a batch; this queue will only be used if all other resource constraints are met; default: 128--max-memory INT
: the caches, the deferred actions queue, and the batch queue, all taken together, must not take more than this much memory in MiB; default: 1024;
making this larger improves performance;
the actual maximum whole-program memory consumption is O(<size of the largest reqres> + <--seen-number> + <sum of lengths of the last --seen-number generated --output paths> + <--cache-number> + <--defer-number> + <--batch-number> + <--max-memory>)--lazy
: sets all of the above options to positive infinity;
most useful when doing hoardy-web organize --symlink --latest --output flat or similar, where the number of distinct generated --output values and the amount of other data hoardy-web needs to keep in memory is small, in which case it will force hoardy-web to compute the desired file system state first and then perform all disk writes in a single batcherror handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default when --no-overwrite--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order; default when --latest--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default when --no-overwrite--walk-reversed
: recursive file system walk is done in reverse lexicographic order; default when --latestinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command this influeences generated file names because filepath_parts and filepath_ext of hoardy-web get --expr (which see) depend on both the original file extension present in the URL and the detected MIME type of its content:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptaction:
--move
: move source files under OUTPUT_DESTINATION; default--copy
: copy source files to files under OUTPUT_DESTINATION--hardlink
: create hardlinks from source files to paths under OUTPUT_DESTINATION--symlink
: create symlinks from source files to paths under OUTPUT_DESTINATIONfile outputs:
-t OUTPUT_DESTINATION, --to OUTPUT_DESTINATION, --organize-to OUTPUT_DESTINATION
: destination directory; when unset each source PATH must be a directory which will be treated as its own OUTPUT_DESTINATION-o OUTPUT_FORMAT, --output OUTPUT_FORMAT
: format describing generated output paths, an alias name or "format:" followed by a custom pythonic %-substitution string:
default : %(syear)d/%(smonth)02d/%(sday)02d/%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(qtime_ms)s_%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(hostname)s_%(num)d; the default
- https://example.org, https://example.org/ -> 1970/01/01/001640000_0_GET_8198_C200C_example.org_0
- https://example.org/index.html -> 1970/01/01/001640000_0_GET_f0dc_C200C_example.org_0
- https://example.org/media -> 1970/01/01/001640000_0_GET_086d_C200C_example.org_0
- https://example.org/media/ -> 1970/01/01/001640000_0_GET_3fbb_C200C_example.org_0
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> 1970/01/01/001640000_0_GET_5658_C200C_example.org_0
- https://königsgäßchen.example.org/index.html -> 1970/01/01/001640000_0_GET_4f11_C200C_königsgäßchen.example.org_0
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> 1970/01/01/001640000_0_GET_c4ae_C200C_ジャジェメント.ですの.example.org_0short : %(syear)d/%(smonth)02d/%(sday)02d/%(stime_ms)d_%(qtime_ms)s_%(num)d
- https://example.org, https://example.org/, https://example.org/index.html, https://example.org/media, https://example.org/media/, https://example.org/view?one=1&two=2&three=&three=3#fragment, https://königsgäßchen.example.org/index.html, https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> 1970/01/01/1000000_0_0surl : %(scheme)s/%(netloc)s/%(mq_npath)s%(oqm)s%(mq_query)s
- https://example.org, https://example.org/ -> https/example.org/
- https://example.org/index.html -> https/example.org/index.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view?one=1&two=2&three=&three=3
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/issurl_msn : %(scheme)s/%(netloc)s/%(mq_npath)s%(oqm)s%(mq_query)s__%(method)s_%(status)s_%(num)d
- https://example.org, https://example.org/ -> https/example.org/__GET_C200C_0
- https://example.org/index.html -> https/example.org/index.html__GET_C200C_0
- https://example.org/media, https://example.org/media/ -> https/example.org/media__GET_C200C_0
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view?one=1&two=2&three=&three=3__GET_C200C_0
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.html__GET_C200C_0
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is__GET_C200C_0surl_mstn : %(scheme)s/%(netloc)s/%(mq_npath)s%(oqm)s%(mq_query)s__%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d
- https://example.org, https://example.org/ -> https/example.org/__GET_C200C_1970-01-01_001640000_0
- https://example.org/index.html -> https/example.org/index.html__GET_C200C_1970-01-01_001640000_0
- https://example.org/media, https://example.org/media/ -> https/example.org/media__GET_C200C_1970-01-01_001640000_0
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view?one=1&two=2&three=&three=3__GET_C200C_1970-01-01_001640000_0
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.html__GET_C200C_1970-01-01_001640000_0
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is__GET_C200C_1970-01-01_001640000_0shupq : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.htm
- https://example.org/index.html -> https/example.org/index.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=&three=3.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.htmshupq_n : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.0.htm
- https://example.org/index.html -> https/example.org/index.0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.0.htmshupq_tn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/example.org/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.1970-01-01_001640000_0.htmshupq_msn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_C200C_0.htm
- https://example.org/index.html -> https/example.org/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_0.htmshupq_mstn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmshupnq : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.htm
- https://example.org/index.html -> https/example.org/index.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.htmshupnq_n : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.0.htm
- https://example.org/index.html -> https/example.org/index.0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.0.htmshupnq_tn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/example.org/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.1970-01-01_001640000_0.htmshupnq_msn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_C200C_0.htm
- https://example.org/index.html -> https/example.org/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_0.htmshupnq_mstn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/example.org/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmshupnq_mhs : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_8198_C200C.htm
- https://example.org/index.html -> https/example.org/index.GET_f0dc_C200C.html
- https://example.org/media -> https/example.org/media/index.GET_086d_C200C.htm
- https://example.org/media/ -> https/example.org/media/index.GET_3fbb_C200C.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.GET_5658_C200C.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_4f11_C200C.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_c4ae_C200C.htmshupnq_mhsn : %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_8198_C200C_0.htm
- https://example.org/index.html -> https/example.org/index.GET_f0dc_C200C_0.html
- https://example.org/media -> https/example.org/media/index.GET_086d_C200C_0.htm
- https://example.org/media/ -> https/example.org/media/index.GET_3fbb_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.GET_5658_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_4f11_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_c4ae_C200C_0.htmshupnq_mhstn: %(scheme)s/%(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/example.org/index.GET_8198_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/example.org/index.GET_f0dc_C200C_1970-01-01_001640000_0.html
- https://example.org/media -> https/example.org/media/index.GET_086d_C200C_1970-01-01_001640000_0.htm
- https://example.org/media/ -> https/example.org/media/index.GET_3fbb_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/example.org/view/index?one=1&two=2&three=3.GET_5658_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/königsgäßchen.example.org/index.GET_4f11_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/ジャジェメント.ですの.example.org/испытание/is/index.GET_c4ae_C200C_1970-01-01_001640000_0.htmsrhupq : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.htm
- https://example.org/index.html -> https/org.example/index.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=&three=3.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.htmsrhupq_n : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.0.htm
- https://example.org/index.html -> https/org.example/index.0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.0.htmsrhupq_tn : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/org.example/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.1970-01-01_001640000_0.htmsrhupq_msn : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_C200C_0.htm
- https://example.org/index.html -> https/org.example/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_0.htmsrhupq_mstn : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/org.example/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmsrhupnq : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.htm
- https://example.org/index.html -> https/org.example/index.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.htmsrhupnq_n : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.0.htm
- https://example.org/index.html -> https/org.example/index.0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.0.htmsrhupnq_tn : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/org.example/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.1970-01-01_001640000_0.htmsrhupnq_msn : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_C200C_0.htm
- https://example.org/index.html -> https/org.example/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_0.htmsrhupnq_mstn: %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/org.example/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> https/org.example/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmsrhupnq_mhs : %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_8198_C200C.htm
- https://example.org/index.html -> https/org.example/index.GET_f0dc_C200C.html
- https://example.org/media -> https/org.example/media/index.GET_086d_C200C.htm
- https://example.org/media/ -> https/org.example/media/index.GET_3fbb_C200C.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.GET_5658_C200C.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_4f11_C200C.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_c4ae_C200C.htmsrhupnq_mhsn: %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_8198_C200C_0.htm
- https://example.org/index.html -> https/org.example/index.GET_f0dc_C200C_0.html
- https://example.org/media -> https/org.example/media/index.GET_086d_C200C_0.htm
- https://example.org/media/ -> https/org.example/media/index.GET_3fbb_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.GET_5658_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_4f11_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_c4ae_C200C_0.htmsrhupnq_mhstn: %(scheme)s/%(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> https/org.example/index.GET_8198_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> https/org.example/index.GET_f0dc_C200C_1970-01-01_001640000_0.html
- https://example.org/media -> https/org.example/media/index.GET_086d_C200C_1970-01-01_001640000_0.htm
- https://example.org/media/ -> https/org.example/media/index.GET_3fbb_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> https/org.example/view/index?one=1&two=2&three=3.GET_5658_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> https/org.example.königsgäßchen/index.GET_4f11_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> https/org.example.ですの.ジャジェメント/испытание/is/index.GET_c4ae_C200C_1970-01-01_001640000_0.htmurl : %(netloc)s/%(mq_npath)s%(oqm)s%(mq_query)s
- https://example.org, https://example.org/ -> example.org/
- https://example.org/index.html -> example.org/index.html
- https://example.org/media, https://example.org/media/ -> example.org/media
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view?one=1&two=2&three=&three=3
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/isurl_msn : %(netloc)s/%(mq_npath)s%(oqm)s%(mq_query)s__%(method)s_%(status)s_%(num)d
- https://example.org, https://example.org/ -> example.org/__GET_C200C_0
- https://example.org/index.html -> example.org/index.html__GET_C200C_0
- https://example.org/media, https://example.org/media/ -> example.org/media__GET_C200C_0
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view?one=1&two=2&three=&three=3__GET_C200C_0
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.html__GET_C200C_0
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is__GET_C200C_0url_mstn : %(netloc)s/%(mq_npath)s%(oqm)s%(mq_query)s__%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d
- https://example.org, https://example.org/ -> example.org/__GET_C200C_1970-01-01_001640000_0
- https://example.org/index.html -> example.org/index.html__GET_C200C_1970-01-01_001640000_0
- https://example.org/media, https://example.org/media/ -> example.org/media__GET_C200C_1970-01-01_001640000_0
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view?one=1&two=2&three=&three=3__GET_C200C_1970-01-01_001640000_0
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.html__GET_C200C_1970-01-01_001640000_0
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is__GET_C200C_1970-01-01_001640000_0hupq : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.htm
- https://example.org/index.html -> example.org/index.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=&three=3.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.htmhupq_n : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.0.htm
- https://example.org/index.html -> example.org/index.0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.0.htmhupq_tn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.1970-01-01_001640000_0.htmhupq_msn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C_0.htm
- https://example.org/index.html -> example.org/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_0.htmhupq_mstn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmhupnq : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.htm
- https://example.org/index.html -> example.org/index.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.htmhupnq_n : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.0.htm
- https://example.org/index.html -> example.org/index.0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.0.htmhupnq_tn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.1970-01-01_001640000_0.htmhupnq_msn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C_0.htm
- https://example.org/index.html -> example.org/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_0.htmhupnq_mstn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmhupnq_mhs : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_8198_C200C.htm
- https://example.org/index.html -> example.org/index.GET_f0dc_C200C.html
- https://example.org/media -> example.org/media/index.GET_086d_C200C.htm
- https://example.org/media/ -> example.org/media/index.GET_3fbb_C200C.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.GET_5658_C200C.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_4f11_C200C.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_c4ae_C200C.htmhupnq_mhsn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_8198_C200C_0.htm
- https://example.org/index.html -> example.org/index.GET_f0dc_C200C_0.html
- https://example.org/media -> example.org/media/index.GET_086d_C200C_0.htm
- https://example.org/media/ -> example.org/media/index.GET_3fbb_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.GET_5658_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_4f11_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_c4ae_C200C_0.htmhupnq_mhstn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_8198_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.GET_f0dc_C200C_1970-01-01_001640000_0.html
- https://example.org/media -> example.org/media/index.GET_086d_C200C_1970-01-01_001640000_0.htm
- https://example.org/media/ -> example.org/media/index.GET_3fbb_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view/index?one=1&two=2&three=3.GET_5658_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_4f11_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание/is/index.GET_c4ae_C200C_1970-01-01_001640000_0.htmrhupq : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.htm
- https://example.org/index.html -> org.example/index.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=&three=3.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.htmrhupq_n : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.0.htm
- https://example.org/index.html -> org.example/index.0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.0.htmrhupq_tn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> org.example/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.1970-01-01_001640000_0.htmrhupq_msn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_C200C_0.htm
- https://example.org/index.html -> org.example/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_0.htmrhupq_mstn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_query|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> org.example/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmrhupnq : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.htm
- https://example.org/index.html -> org.example/index.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.htmrhupnq_n : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.0.htm
- https://example.org/index.html -> org.example/index.0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.0.htmrhupnq_tn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> org.example/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.1970-01-01_001640000_0.htmrhupnq_msn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_C200C_0.htm
- https://example.org/index.html -> org.example/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_0.htmrhupnq_mstn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> org.example/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> org.example/media/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_C200C_1970-01-01_001640000_0.htmrhupnq_mhs : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 120)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_8198_C200C.htm
- https://example.org/index.html -> org.example/index.GET_f0dc_C200C.html
- https://example.org/media -> org.example/media/index.GET_086d_C200C.htm
- https://example.org/media/ -> org.example/media/index.GET_3fbb_C200C.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.GET_5658_C200C.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_4f11_C200C.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_c4ae_C200C.htmrhupnq_mhsn : %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_8198_C200C_0.htm
- https://example.org/index.html -> org.example/index.GET_f0dc_C200C_0.html
- https://example.org/media -> org.example/media/index.GET_086d_C200C_0.htm
- https://example.org/media/ -> org.example/media/index.GET_3fbb_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.GET_5658_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_4f11_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_c4ae_C200C_0.htmrhupnq_mhstn: %(rhostname)s/%(filepath_parts|abbrev_each 120|pp_to_path)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> org.example/index.GET_8198_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> org.example/index.GET_f0dc_C200C_1970-01-01_001640000_0.html
- https://example.org/media -> org.example/media/index.GET_086d_C200C_1970-01-01_001640000_0.htm
- https://example.org/media/ -> org.example/media/index.GET_3fbb_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> org.example/view/index?one=1&two=2&three=3.GET_5658_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> org.example.königsgäßchen/index.GET_4f11_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> org.example.ですの.ジャジェメント/испытание/is/index.GET_c4ae_C200C_1970-01-01_001640000_0.htmflat : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.htm
- https://example.org/index.html -> example.org/index.html
- https://example.org/media, https://example.org/media/ -> example.org/media__index.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.htmflat_n : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.0.htm
- https://example.org/index.html -> example.org/index.0.html
- https://example.org/media, https://example.org/media/ -> example.org/media__index.0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.0.htmflat_tn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media__index.1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.1970-01-01_001640000_0.htmflat_ms : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C.htm
- https://example.org/index.html -> example.org/index.GET_C200C.html
- https://example.org/media, https://example.org/media/ -> example.org/media__index.GET_C200C.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.GET_C200C.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.GET_C200C.htmflat_msn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C_0.htm
- https://example.org/index.html -> example.org/index.GET_C200C_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media__index.GET_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.GET_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.GET_C200C_0.htmflat_mstn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://example.org/media, https://example.org/media/ -> example.org/media__index.GET_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.GET_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.GET_C200C_1970-01-01_001640000_0.htmflat_mhs : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_8198_C200C.htm
- https://example.org/index.html -> example.org/index.GET_f0dc_C200C.html
- https://example.org/media -> example.org/media__index.GET_086d_C200C.htm
- https://example.org/media/ -> example.org/media__index.GET_3fbb_C200C.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.GET_5658_C200C.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_4f11_C200C.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.GET_c4ae_C200C.htmflat_mhsn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_8198_C200C_0.htm
- https://example.org/index.html -> example.org/index.GET_f0dc_C200C_0.html
- https://example.org/media -> example.org/media__index.GET_086d_C200C_0.htm
- https://example.org/media/ -> example.org/media__index.GET_3fbb_C200C_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.GET_5658_C200C_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_4f11_C200C_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.GET_c4ae_C200C_0.htmflat_mhstn : %(hostname)s/%(filepath_parts|abbrev_each 120|pp_to_path|replace / __|abbrev 120)s%(oqm)s%(mq_nquery|abbrev 100)s.%(method)s_%(net_url|to_ascii|sha256|take_prefix 2|to_hex)s_%(status)s_%(syear)d-%(smonth)02d-%(sday)02d_%(shour)02d%(sminute)02d%(ssecond)02d%(stime_msq)03d_%(num)d%(filepath_ext)s
- https://example.org, https://example.org/ -> example.org/index.GET_8198_C200C_1970-01-01_001640000_0.htm
- https://example.org/index.html -> example.org/index.GET_f0dc_C200C_1970-01-01_001640000_0.html
- https://example.org/media -> example.org/media__index.GET_086d_C200C_1970-01-01_001640000_0.htm
- https://example.org/media/ -> example.org/media__index.GET_3fbb_C200C_1970-01-01_001640000_0.htm
- https://example.org/view?one=1&two=2&three=&three=3#fragment -> example.org/view__index?one=1&two=2&three=3.GET_5658_C200C_1970-01-01_001640000_0.htm
- https://königsgäßchen.example.org/index.html -> königsgäßchen.example.org/index.GET_4f11_C200C_1970-01-01_001640000_0.html
- https://ジャジェメント.ですの.example.org/испытание/is/, https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ -> ジャジェメント.ですの.example.org/испытание__is__index.GET_c4ae_C200C_1970-01-01_001640000_0.htmhoardy-web get --expr (which see);num: number of times the resulting output path was encountered before; adding this parameter to your --output format will ensure all generated file names will be uniquenew --outputs printing:
--no-print
: don't print anything; default-l, --lf-terminated
: print absolute paths of newly produced or replaced files terminated with \n (LF) newline characters-z, --zero-terminated
: print absolute paths of newly produced or replaced files terminated with \0 (NUL) bytesupdates to --outputs:
--no-overwrite
: disallow overwrites and replacements of any existing files under OUTPUT_DESTINATION, i.e. only ever create new files under OUTPUT_DESTINATION, producing errors instead of attempting any other updates; default;
--output targets that are broken symlinks will be considered to be non-existent and will be replaced;
when the operation's source is binary-eqivalent to the --output target, the operation will be permitted, but the disk write will be reduced to a noop, i.e. the results will be deduplicated;
the dirname of a source file and the --to target directories can be the same, in that case the source file will be renamed to use new --output name, though renames that attempt to swap files will still fail--latest
: replace files under OUTPUT_DESTINATION with their latest version;
this is only allowed in combination with --symlink at the moment;
for each source PATH file, the destination --output file will be replaced with a symlink to the source if and only if stime_ms of the source reqres is newer than stime_ms of the reqres stored at the destination fileUse specified parser to parse data in each INPUT PATH into (a sequence of) reqres and then generate and place their WRR dumps into separate WRR files under OUTPUT_DESTINATION with paths derived from their metadata.
In short, this is hoardy-web organize --copy for INPUT files that use different files formats.
{wrrb,bundle,mitmproxy,mitmdump}
wrrb (bundle)
: convert WRR bundles into separate WRR filesmitmproxy (mitmdump)
: convert mitmproxy stream dumps (files produced by mitmdump) into WRR filesParse each INPUT PATH as a WRR bundle (an optionally compressed sequence of WRR dumps) and then generate and place their WRR dumps into separate WRR files under OUTPUT_DESTINATION with paths derived from their metadata.
options:
--dry-run
: perform a trial run without actually performing any changes-q, --quiet
: don't log computed updates and don't print end-of-filtering warnings to stderrcaching, deferring, and batching:
--seen-number INT
: track at most this many distinct generated --output values; default: 16384;
making this larger improves disk performance at the cost of increased memory consumption;
setting it to zero will force force hoardy-web to constantly re-check existence of --output files and force hoardy-web to execute all IO actions immediately, disregarding --defer-number setting--cache-number INT
: cache stat(2) information about this many files in memory; default: 8192;
making this larger improves performance at the cost of increased memory consumption;
setting this to a too small number will likely force hoardy-web into repeatedly performing lots of stat(2) system calls on the same files;
setting this to a value smaller than --defer-number will not improve memory consumption very much since deferred IO actions also cache information about their own files--defer-number INT
: defer at most this many IO actions; default: 0;
making this larger improves performance at the cost of increased memory consumption;
setting it to zero will force all IO actions to be applied immediately--batch-number INT
: queue at most this many deferred IO actions to be applied together in a batch; this queue will only be used if all other resource constraints are met; default: 1024--max-memory INT
: the caches, the deferred actions queue, and the batch queue, all taken together, must not take more than this much memory in MiB; default: 1024;
making this larger improves performance;
the actual maximum whole-program memory consumption is O(<size of the largest reqres> + <--seen-number> + <sum of lengths of the last --seen-number generated --output paths> + <--cache-number> + <--defer-number> + <--batch-number> + <--max-memory>)--lazy
: sets all of the above options to positive infinity;
most useful when doing hoardy-web organize --symlink --latest --output flat or similar, where the number of distinct generated --output values and the amount of other data hoardy-web needs to keep in memory is small, in which case it will force hoardy-web to compute the desired file system state first and then perform all disk writes in a single batcherror handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command this influeences generated file names because filepath_parts and filepath_ext of hoardy-web get --expr (which see) depend on both the original file extension present in the URL and the detected MIME type of its content:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptfile outputs:
-t OUTPUT_DESTINATION, --to OUTPUT_DESTINATION, --import-to OUTPUT_DESTINATION
: destination directory; required-o OUTPUT_FORMAT, --output OUTPUT_FORMAT
: format describing generated output paths, an alias name or "format:" followed by a custom pythonic %-substitution string; same expression format as hoardy-web organize --output (which see); default: defaultnew --outputs printing:
--no-print
: don't print anything; default-l, --lf-terminated
: print absolute paths of newly produced or replaced files terminated with \n (LF) newline characters-z, --zero-terminated
: print absolute paths of newly produced or replaced files terminated with \0 (NUL) bytesupdates to --outputs:
--no-overwrite
: disallow overwrites and replacements of any existing files under OUTPUT_DESTINATION, i.e. only ever create new files under OUTPUT_DESTINATION, producing errors instead of attempting any other updates; default--overwrite-dangerously
: permit overwrites to files under OUTPUT_DESTINATION;
DANGEROUS! not recommended, importing to a new OUTPUT_DESTINATION with the default --no-overwrite and then rsyncing some of the files over to the old OUTPUT_DESTINATION is a safer way to do thisParse each INPUT PATH as mitmproxy stream dump (by using mitmproxy's own parser) into a sequence of reqres and then generate and place their WRR dumps into separate WRR files under OUTPUT_DESTINATION with paths derived from their metadata.
options:
--dry-run
: perform a trial run without actually performing any changes-q, --quiet
: don't log computed updates and don't print end-of-filtering warnings to stderrcaching, deferring, and batching:
--seen-number INT
: track at most this many distinct generated --output values; default: 16384;
making this larger improves disk performance at the cost of increased memory consumption;
setting it to zero will force force hoardy-web to constantly re-check existence of --output files and force hoardy-web to execute all IO actions immediately, disregarding --defer-number setting--cache-number INT
: cache stat(2) information about this many files in memory; default: 8192;
making this larger improves performance at the cost of increased memory consumption;
setting this to a too small number will likely force hoardy-web into repeatedly performing lots of stat(2) system calls on the same files;
setting this to a value smaller than --defer-number will not improve memory consumption very much since deferred IO actions also cache information about their own files--defer-number INT
: defer at most this many IO actions; default: 0;
making this larger improves performance at the cost of increased memory consumption;
setting it to zero will force all IO actions to be applied immediately--batch-number INT
: queue at most this many deferred IO actions to be applied together in a batch; this queue will only be used if all other resource constraints are met; default: 1024--max-memory INT
: the caches, the deferred actions queue, and the batch queue, all taken together, must not take more than this much memory in MiB; default: 1024;
making this larger improves performance;
the actual maximum whole-program memory consumption is O(<size of the largest reqres> + <--seen-number> + <sum of lengths of the last --seen-number generated --output paths> + <--cache-number> + <--defer-number> + <--batch-number> + <--max-memory>)--lazy
: sets all of the above options to positive infinity;
most useful when doing hoardy-web organize --symlink --latest --output flat or similar, where the number of distinct generated --output values and the amount of other data hoardy-web needs to keep in memory is small, in which case it will force hoardy-web to compute the desired file system state first and then perform all disk writes in a single batcherror handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command this influeences generated file names because filepath_parts and filepath_ext of hoardy-web get --expr (which see) depend on both the original file extension present in the URL and the detected MIME type of its content:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptfile outputs:
-t OUTPUT_DESTINATION, --to OUTPUT_DESTINATION, --import-to OUTPUT_DESTINATION
: destination directory; required-o OUTPUT_FORMAT, --output OUTPUT_FORMAT
: format describing generated output paths, an alias name or "format:" followed by a custom pythonic %-substitution string; same expression format as hoardy-web organize --output (which see); default: defaultnew --outputs printing:
--no-print
: don't print anything; default-l, --lf-terminated
: print absolute paths of newly produced or replaced files terminated with \n (LF) newline characters-z, --zero-terminated
: print absolute paths of newly produced or replaced files terminated with \0 (NUL) bytesupdates to --outputs:
--no-overwrite
: disallow overwrites and replacements of any existing files under OUTPUT_DESTINATION, i.e. only ever create new files under OUTPUT_DESTINATION, producing errors instead of attempting any other updates; default--overwrite-dangerously
: permit overwrites to files under OUTPUT_DESTINATION;
DANGEROUS! not recommended, importing to a new OUTPUT_DESTINATION with the default --no-overwrite and then rsyncing some of the files over to the old OUTPUT_DESTINATION is a safer way to do thisGenerate a local offline static website mirror from given intuts, producing results similar to those of wget -mpk.
Algorithm:
PATH:
--latest and this input is older than the already indexed one);EXPR expressions on the reqres (which, by default, takes its response body and rewrites all links to point to locally mirrored files);DEPTH, queue those documents for mirroring too,EXPRs into a separate file under OUTPUT_DESTINATION with its path derived from reqres' metadata.The end.
Essentially, this is a combination of hoardy-web organize --copy followed by in-place hoardy-web get which has the advanced URL remapping capabilities of (*|/|&)(jumps|actions|reqs) options available in its scrub function.
options:
--dry-run
: perform a trial run without actually performing any changes-q, --quiet
: don't log computed updates and don't print end-of-filtering warnings to stderrcaching:
--max-memory INT
: the caches, all taken together, must not take more than this much memory in MiB; default: 1024;
making this larger improves performance;
the actual maximum whole-program memory consumption is O(<size of the largest reqres> + <numer of indexed files> + <sum of lengths of all their --output paths> + <--max-memory>)error handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line arguments--boring PATH
: low-priority input PATH; boring PATHs will be processed after all PATHs specified as positional command-line arguments and those given via --stdin0 and will not be queued as roots even when no --root-* options are specifiedPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command this influeences generated file names because filepath_parts and filepath_ext of hoardy-web get --expr (which see) depend on both the original file extension present in the URL and the detected MIME type of its content; also, higher values make the scrub function (which see) censor out more things when -unknown, -styles, or -scripts options are set; in particular, at the moment, with --sniff-paranoid and -scripts most plain text files will be censored out as potential JavaScript:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptdefault input filters:
--ignore-some-inputs
: initialize input filters to --status-re ".(200|30[012378])C"; this matches complete 200 OK and 300 Multiple Choices responses and various redirects; default--index-all-inputs
: do not set any input filters by default; if you set this option, you should also probably set at least --status-re ".*C" --not-status-re ".206.", unless you want hoardy-web mirror processing partially downloaded datadefault root filters:
--skip-some-indexed
: initialize root filters to --root-status-re ".[23]00C"; this matches complete 200 OK and 300 Multiple Choices responses; default--queue-all-indexed
: do not set any root filters by default; hoardy-web mirror will follow redirects when remapping links, but, at the moment, attempting to render redirects produces empty files; thus, if you set this option, you should also set --not-status-re ".30[12378]." or similarexpression evaluation:
-e EXPR, --expr EXPR
: an expression to compute, same expression format and semantics as hoardy-web get --expr (which see); can be specified multiple times; the default depends on --remap-* options belowrendering of --expr values:
--not-separated
: render --expr values into outputs without separating them with anything, just concatenate them--lf-separated
: render --expr values into outputs separated with \n (LF) newline characters; default--zero-separated
: render --expr values into outputs separated with \0 (NUL) bytesdefault value of --expr:
--raw-qbody
: set the default value of --expr to request.body|eb; i.e. produce the raw request body
--raw-sbody, --no-remap
: set the default value of --expr to response.body|eb; i.e. produce the raw response body
--remap-id
: set the default value of --expr to response.body|eb|scrub response +all_refs; i.e. scrub response body as follows: remap all URLs with an identity function (which, as a whole, is NOT an identity function, it will transform all relative URLs into absolute ones), censor out all dynamic content (e.g. JavaScript); results will NOT be self-contained
--remap-void
: set the default value of --expr to response.body|eb|scrub response -all_refs; i.e. scrub response body as follows: remap all URLs into javascript:void(0) and empty data: URLs, censor out all dynamic content; results will be self-contained
--remap-open, -k, --convert-links
: set the default value of --expr to response.body|eb|scrub response *all_refs; i.e. scrub response body as follows: remap all URLs present in input PATHs and reachable from --root-*s in no more that --depth steps to their corresponding --output paths, remap all other URLs like --remap-id does, censor out all dynamic content; results almost certainly will NOT be self-contained
--remap-closed
: set the default value of --expr to response.body|eb|scrub response /all_refs; i.e. scrub response body as follows: remap all URLs present in input PATHs and reachable from --root-*s in no more that --depth steps to their corresponding --output paths, remap all other URLs like --remap-void does, censor out all dynamic content; results will be self-contained
--remap-semi
: set the default value of --expr to response.body|eb|scrub response *jumps,/actions,/reqs; i.e. scrub response body as follows: remap all jump links like --remap-open does, remap action links and references to page requisites like --remap-closed does, censor out all dynamic content; this is a better version of --remap-open which keeps the mirrors self-contained with respect to page requisites, i.e. generated pages can be opened in a web browser without it trying to access the Internet, but all navigations to missing and unreachable URLs will still point to the original URLs; results will be semi-self-contained
--remap-all
: set the default value of --expr to response.body|eb|scrub response &all_refs; i.e. scrub response body as follows: remap all links and references like --remap-closed does, except, instead of voiding missing and unreachable URLs, replace them with fallback URLs whenever possble, censor out all dynamic content; results will be self-contained; default
hoardy-web mirror uses --output paths of trivial GET <URL> -> 200 OK as fallbacks for &(jumps|actions|reqs) options of scrub.
This will remap links pointing to missing and unreachable URLs to missing files.
However, for simple --output formats (like the default hupq), those files can later be generated by running hoardy-web mirror with WRR files containing those missing or unreachable URLs as inputs.
I.e. this behaviour allows you to add new data to an already existing mirror without regenerating old files that reference newly added URLs.
I.e. this allows hoardy-web mirror to be used incrementally.
Note however, that using fallbacks when the --output format depends on anything but the URL itself (e.g. if it mentions timestamps) will produce a mirror with unrecoverably broken links.
link conversions:
--relative
: when remapping URLs to local files, produce links and references with relative URLs (relative to the --output files under OUTPUT_DESTINATION); default when --copy or --hardlink--absolute
: when remapping URLs to local files, produce links and references with absolute URLs; default when --symlinkmirror what:
--oldest
: for each URL, mirror its oldest available version--oldest-hybrid
: for each URL, mirror its oldest available version, except, for each URL that is a requisite resource, mirror a version that is time-closest to the referencing document; i.e., this will make each mirrored page refer to requisites (images, media, CSS, fonts, etc) that were archived around the time the page itself was archived, even if those requisite resources changed in time; this produces results that are as close to the original web page as possible at the cost of much more memory to mirror--nearest INTERVAL_DATE
: for each URL, mirror an available version that is closest to the given INTERVAL_DATE value; the INTERVAL_DATE is parsed as a time interval the middle point of which is taken as target value; e.g., 2024 becomes 2024-07-02 00:00:00 (which is the exact middle point of that year), 2024-12-31 becomes 2024-12-31 12:00:00, 2024-12-31 12 -> 2024-12-31 12:30:00, 2024-12-31 12:00 -> 2024-12-31 12:00:30, 2024-12-31 12:00:01 -> 2024-12-31 12:00:01.5, etc--nearest-hybrid INTERVAL_DATE
: for each URL, mirror an available version that is closest to the given INTERVAL_DATE value; the INTERVAL_DATE format and semantics is the same as above, except, for each URL that is a requisite resource, mirror a version that is time-closest to the referencing document; see --oldest-hybrid above for more info--latest
: for each URL, mirror its latest available version; default--latest-hybrid
: for each URL, mirror its latest available version, except, for each URL that is a requisite resource, mirror a version that is time-closest to the referencing document; see --oldest-hybrid above for more info--all
: mirror all available versions of all available URLs; this is likely to take a lot of time and eat a lot of memory!file outputs:
-t OUTPUT_DESTINATION, --to OUTPUT_DESTINATION, --mirror-to OUTPUT_DESTINATION
: destination directory; required-o OUTPUT_FORMAT, --output OUTPUT_FORMAT
: format describing generated output paths, an alias name or "format:" followed by a custom pythonic %-substitution string; same expression format as hoardy-web organize --output (which see); default: hupq_nnew --outputs printing:
--no-print
: don't print anything; default-l, --lf-terminated
: print absolute paths of newly produced or replaced files terminated with \n (LF) newline characters-z, --zero-terminated
: print absolute paths of newly produced or replaced files terminated with \0 (NUL) bytesupdates to --outputs:
--no-overwrite
: disallow overwrites and replacements of any existing files under OUTPUT_DESTINATION, i.e. only ever create new files under OUTPUT_DESTINATION, producing errors instead of attempting any other updates; default;
repeated mirrors of the same targets with the same parameters (which, therefore, will produce the same --output data) are allowed and will be reduced to noops;
however, trying to overwrite existing files under OUTPUT_DESTINATION with any new data will produce errors;
this allows reusing the OUTPUT_DESTINATION between unrelated mirrors and between mirrors that produce the same data on disk in their common parts--skip-existing, --partial
: skip rendering of targets which have a corresponding file under OUTPUT_DESTINATION, use the contents of such files instead;
using this together with --depth is likely to produce a partially broken result, since skipping of a document will also skip all of the things it references;
on the other hand, this is quite useful when growing a partial mirror generated with --remap-all--overwrite-dangerously
: mirror all targets while permitting overwriting of old --output files under OUTPUT_DESTINATION;
DANGEROUS! not recommended, mirroring to a new OUTPUT_DESTINATION with the default --no-overwrite and then rsyncing some of the files over to the old OUTPUT_DESTINATION is a safer way to do thiscontent-addressed file output mode:
--copy
: do not use content-addressed outputs, simply write rendered output data to files under OUTPUT_DESTINATION--hardlink
: write rendered output data to files under CONTENT_DESTINATION, then hardlink them to paths under OUTPUT_DESTINATION; default--symlink
: write rendered output data to files under CONTENT_DESTINATION, then symlink them to paths under OUTPUT_DESTINATIONcontent-addressed file output settings:
--content-to CONTENT_DESTINATION
: content-addressed destination directory; if not specified, reuses OUTPUT_DESTINATION--content-output CONTENT_FORMAT
: format describing generated content-addressed output paths, an alias name or "format:" followed by a custom pythonic %-substitution string:
default : _content/sha256/%(content_sha256|take_prefix 1|to_hex)s/%(content_sha256|to_hex)s%(filepath_ext)s; the defaulthoardy-web get --expr (which see);content: rendered contentcontent_sha256: alias for content|sha256recursion root filters; if none are specified, then all URLs available from input PATHs will be treated as roots (except for those given via --boring); can be specified multiple times in arbitrary combinations; the resulting logical expression that will be checked is all_of(before) and all_of(not_before) and all_of(after) and all_of(not_after) and any_of(protocol) and not any_of(not_protcol) and any_of(request_method) and not any_of(not_request_method) ... and any_of(grep) and not any_of(not_grep) and all_of(and_grep) and not all_of(not_and_grep) and all_of(ands) and any_of(ors):
--root-before DATE
: take reqres as a root when its stime is smaller than this; the DATE can be specified either as a number of seconds since UNIX epoch using @<number> format where <number> can be a floating point, or using one of the following formats:YYYY-mm-DD HH:MM:SS[.NN*] (+|-)HHMM, YYYY-mm-DD HH:MM:SS[.NN*], YYYY-mm-DD HH:MM:SS, YYYY-mm-DD HH:MM, YYYY-mm-DD, YYYY-mm, YYYY; if no (+|-)HHMM part is specified, the DATE is assumed to be in local time; if other parts are unspecified they are inherited from <year>-01-01 00:00:00.0--root-not-before DATE
: take reqres as a root when its stime is larger or equal than this; the DATE format is the same as above--root-after DATE
: take reqres as a root when its stime is larger than this; the DATE format is the same as above--root-not-after DATE
: take reqres as a root when its stime is smaller or equal than this; the DATE format is the same as above--root-protocol PROTOCOL
: take reqres as a root when one of the given PROTOCOL option arguments is equal to its protocol (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--root-protocol-prefix PROTOCOL_PREFIX
: take reqres as a root when one of the given PROTOCOL_PREFIX option arguments is a prefix of its protocol (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--root-protocol-re PROTOCOL_RE
: take reqres as a root when one of the given PROTOCOL_RE regular expressions matches its protocol (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--root-not-protocol NOT_PROTOCOL
: take reqres as a root when none of the given NOT_PROTOCOL option arguments are equal to its protocol (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--root-not-protocol-prefix NOT_PROTOCOL_PREFIX
: take reqres as a root when none of the given NOT_PROTOCOL_PREFIX option arguments are a prefix of its protocol (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--root-not-protocol-re NOT_PROTOCOL_RE
: take reqres as a root when none of the given NOT_PROTOCOL_RE regular expressions match its protocol (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a blacklisted element rule--root-request-method REQUEST_METHOD, --root-method REQUEST_METHOD
: take reqres as a root when one of the given REQUEST_METHOD option arguments is equal to its request.method (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--root-request-method-prefix REQUEST_METHOD_PREFIX, --root-method-prefix REQUEST_METHOD_PREFIX
: take reqres as a root when one of the given REQUEST_METHOD_PREFIX option arguments is a prefix of its request.method (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--root-request-method-re REQUEST_METHOD_RE, --root-method-re REQUEST_METHOD_RE
: take reqres as a root when one of the given REQUEST_METHOD_RE regular expressions matches its request.method (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--root-not-request-method NOT_REQUEST_METHOD, --root-not-method NOT_REQUEST_METHOD
: take reqres as a root when none of the given NOT_REQUEST_METHOD option arguments are equal to its request.method (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--root-not-request-method-prefix NOT_REQUEST_METHOD_PREFIX
: take reqres as a root when none of the given NOT_REQUEST_METHOD_PREFIX option arguments are a prefix of its request.method (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--root-not-request-method-re NOT_REQUEST_METHOD_RE
: take reqres as a root when none of the given NOT_REQUEST_METHOD_RE regular expressions match its request.method (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a blacklisted element rule--root-status STATUS
: take reqres as a root when one of the given STATUS option arguments is equal to its status (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--root-status-prefix STATUS_PREFIX
: take reqres as a root when one of the given STATUS_PREFIX option arguments is a prefix of its status (of hoardy-web get --expr, which see); in short, this option defines a whitelisted element rule--root-status-re STATUS_RE
: take reqres as a root when one of the given STATUS_RE regular expressions matches its status (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--root-not-status NOT_STATUS
: take reqres as a root when none of the given NOT_STATUS option arguments are equal to its status (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--root-not-status-prefix NOT_STATUS_PREFIX
: take reqres as a root when none of the given NOT_STATUS_PREFIX option arguments are a prefix of its status (of hoardy-web get --expr, which see); in short, this option defines a blacklisted element rule--root-not-status-re NOT_STATUS_RE
: take reqres as a root when none of the given NOT_STATUS_RE regular expressions match its status (of hoardy-web get --expr, which see); this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a blacklisted element rule--root-url URL
: take reqres as a root when one of the given URL option arguments is equal to its net_url (of hoardy-web get --expr, which see); Punycode UTS46 IDNAs, plain UNICODE IDNAs, percent-encoded URL components, and UNICODE URL components in arbitrary mixes and combinations are allowed; e.g. https://xn--hck7aa9d8fj9i.ですの.example.org/исп%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/ will be silently normalized into its Punycode UTS46 and percent-encoded version of https://xn--hck7aa9d8fj9i.xn--88j1aw.example.org/%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5/is/, which will then be matched against; in short, this option defines a whitelisted element rule--root-url-prefix URL_PREFIX, --root URL_PREFIX, -r URL_PREFIX
: take reqres as a root when one of the given URL_PREFIX option arguments is a prefix of its net_url (of hoardy-web get --expr, which see); similarly to the previous option, arbitrary mixes of URL encodinds are allowed; in short, this option defines a whitelisted element rule--root-url-re URL_RE
: take reqres as a root when one of the given URL_RE regular expressions matches its net_url or pretty_net_url (of hoardy-web get --expr, which see); only Punycode UTS46 IDNAs with percent-encoded URL components or plain UNICODE IDNAs with UNICODE URL components are allowed; regular expressions that use mixes of differently encoded parts will fail to match properly; this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--root-not-url NOT_URL
: take reqres as a root when none of the given NOT_URL option arguments are equal to its net_url (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-not-url-prefix NOT_URL_PREFIX
: take reqres as a root when none of the given NOT_URL_PREFIX option arguments are a prefix of its net_url (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-not-url-re NOT_URL_RE
: take reqres as a root when none of the given NOT_URL_RE regular expressions match its net_url or pretty_net_url (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-request-headers-or-grep OR_PATTERN, --root-request-headers-grep OR_PATTERN
: take reqres as a root when at least one of the given OR_PATTERN option arguments is a substring of at least one of the elements of the list containing all request.headers (of hoardy-web get --expr, which see); each HTTP header of *.headers is matched as a single <header_name>: <header_value> value; at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--root-request-headers-or-grep-re OR_PATTERN_RE, --root-request-headers-grep-re OR_PATTERN_RE
: take reqres as a root when at least one of the given OR_PATTERN_RE regular expressions matches a substring of at least one of the elements of the above list; matching caveats are the same as above; in short, this option defines a whitelisted element rule--root-not-request-headers-or-grep NOT_OR_PATTERN, --root-not-request-headers-grep NOT_OR_PATTERN
: take reqres as a root when none of the given NOT_OR_PATTERN option arguments are substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-not-request-headers-or-grep-re NOT_OR_PATTERN_RE, --root-not-request-headers-grep-re NOT_OR_PATTERN_RE
: take reqres as a root when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-request-headers-and-grep AND_PATTERN
: take reqres as a root when each of the given AND_PATTERN option arguments is a substring of some element of the above list; matching caveats are the same as above--root-request-headers-and-grep-re AND_PATTERN_RE
: take reqres as a root when each of the given AND_PATTERN_RE regular expressions matches a substring of some element of the above list; matching caveats are the same as above--root-not-request-headers-and-grep NOT_AND_PATTERN
: take reqres as a root when one or more of the given NOT_AND_PATTERN option arguments is not a substring of the elements of the above list; matching caveats are the same as above--root-not-request-headers-and-grep-re NOT_AND_PATTERN_RE
: take reqres as a root when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of the elements of the above list; matching caveats are the same as above--root-request-body-or-grep OR_PATTERN, --root-request-body-grep OR_PATTERN
: take reqres as a root when at least one of the given OR_PATTERN option arguments is a substring of request.body (of hoardy-web get --expr, which see); at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--root-request-body-or-grep-re OR_PATTERN_RE, --root-request-body-grep-re OR_PATTERN_RE
: take reqres as a root when at least one of the given OR_PATTERN_RE regular expressions matches a substring of request.body; matching caveats are the same as above; in short, this option defines a whitelisted element rule--root-not-request-body-or-grep NOT_OR_PATTERN, --root-not-request-body-grep NOT_OR_PATTERN
: take reqres as a root when none of the given NOT_OR_PATTERN option arguments are substrings of request.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-not-request-body-or-grep-re NOT_OR_PATTERN_RE, --root-not-request-body-grep-re NOT_OR_PATTERN_RE
: take reqres as a root when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of request.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-request-body-and-grep AND_PATTERN
: take reqres as a root when each of the given AND_PATTERN option arguments is a substring of request.body; matching caveats are the same as above--root-request-body-and-grep-re AND_PATTERN_RE
: take reqres as a root when each of the given AND_PATTERN_RE regular expressions matches a substring of request.body; matching caveats are the same as above--root-not-request-body-and-grep NOT_AND_PATTERN
: take reqres as a root when one or more of the given NOT_AND_PATTERN option arguments is not a substring of request.body; matching caveats are the same as above--root-not-request-body-and-grep-re NOT_AND_PATTERN_RE
: take reqres as a root when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of request.body; matching caveats are the same as above--root-request-mime REQUEST_MIME
: take reqres as a root when one of the given REQUEST_MIME option arguments is equal to its request_mime (of hoardy-web get --expr, which see); both canonical and non-canonical MIME types are allowed; e.g., giving application/x-grip or application/gzip will produce the same predicate; in short, this option defines a whitelisted element rule--root-request-mime-prefix REQUEST_MIME_PREFIX
: take reqres as a root when one of the given REQUEST_MIME_PREFIX option arguments is a prefix of its request_mime (of hoardy-web get --expr, which see); given prefixes will only ever be matched against canonicalized MIME types; in short, this option defines a whitelisted element rule--root-request-mime-re REQUEST_MIME_RE
: take reqres as a root when one of the given REQUEST_MIME_RE regular expressions matches its request_mime (of hoardy-web get --expr, which see); given regular expressions will only ever be matched against canonicalized MIME types; this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--root-not-request-mime NOT_REQUEST_MIME
: take reqres as a root when none of the given NOT_REQUEST_MIME option arguments are equal to its request_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-not-request-mime-prefix NOT_REQUEST_MIME_PREFIX
: take reqres as a root when none of the given NOT_REQUEST_MIME_PREFIX option arguments are a prefix of its request_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-not-request-mime-re NOT_REQUEST_MIME_RE
: take reqres as a root when none of the given NOT_REQUEST_MIME_RE regular expressions match its request_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-response-headers-or-grep OR_PATTERN, --root-response-headers-grep OR_PATTERN
: take reqres as a root when at least one of the given OR_PATTERN option arguments is a substring of at least one of the elements of the list containing all response.headers (of hoardy-web get --expr, which see); each HTTP header of *.headers is matched as a single <header_name>: <header_value> value; at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--root-response-headers-or-grep-re OR_PATTERN_RE, --root-response-headers-grep-re OR_PATTERN_RE
: take reqres as a root when at least one of the given OR_PATTERN_RE regular expressions matches a substring of at least one of the elements of the above list; matching caveats are the same as above; in short, this option defines a whitelisted element rule--root-not-response-headers-or-grep NOT_OR_PATTERN, --root-not-response-headers-grep NOT_OR_PATTERN
: take reqres as a root when none of the given NOT_OR_PATTERN option arguments are substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-not-response-headers-or-grep-re NOT_OR_PATTERN_RE, --root-not-response-headers-grep-re NOT_OR_PATTERN_RE
: take reqres as a root when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-response-headers-and-grep AND_PATTERN
: take reqres as a root when each of the given AND_PATTERN option arguments is a substring of some element of the above list; matching caveats are the same as above--root-response-headers-and-grep-re AND_PATTERN_RE
: take reqres as a root when each of the given AND_PATTERN_RE regular expressions matches a substring of some element of the above list; matching caveats are the same as above--root-not-response-headers-and-grep NOT_AND_PATTERN
: take reqres as a root when one or more of the given NOT_AND_PATTERN option arguments is not a substring of the elements of the above list; matching caveats are the same as above--root-not-response-headers-and-grep-re NOT_AND_PATTERN_RE
: take reqres as a root when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of the elements of the above list; matching caveats are the same as above--root-response-body-or-grep OR_PATTERN, --root-response-body-grep OR_PATTERN
: take reqres as a root when at least one of the given OR_PATTERN option arguments is a substring of response.body (of hoardy-web get --expr, which see); at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--root-response-body-or-grep-re OR_PATTERN_RE, --root-response-body-grep-re OR_PATTERN_RE
: take reqres as a root when at least one of the given OR_PATTERN_RE regular expressions matches a substring of response.body; matching caveats are the same as above; in short, this option defines a whitelisted element rule--root-not-response-body-or-grep NOT_OR_PATTERN, --root-not-response-body-grep NOT_OR_PATTERN
: take reqres as a root when none of the given NOT_OR_PATTERN option arguments are substrings of response.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-not-response-body-or-grep-re NOT_OR_PATTERN_RE, --root-not-response-body-grep-re NOT_OR_PATTERN_RE
: take reqres as a root when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of response.body; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-response-body-and-grep AND_PATTERN
: take reqres as a root when each of the given AND_PATTERN option arguments is a substring of response.body; matching caveats are the same as above--root-response-body-and-grep-re AND_PATTERN_RE
: take reqres as a root when each of the given AND_PATTERN_RE regular expressions matches a substring of response.body; matching caveats are the same as above--root-not-response-body-and-grep NOT_AND_PATTERN
: take reqres as a root when one or more of the given NOT_AND_PATTERN option arguments is not a substring of response.body; matching caveats are the same as above--root-not-response-body-and-grep-re NOT_AND_PATTERN_RE
: take reqres as a root when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of response.body; matching caveats are the same as above--root-response-mime RESPONSE_MIME
: take reqres as a root when one of the given RESPONSE_MIME option arguments is equal to its response_mime (of hoardy-web get --expr, which see); both canonical and non-canonical MIME types are allowed; e.g., giving application/x-grip or application/gzip will produce the same predicate; in short, this option defines a whitelisted element rule--root-response-mime-prefix RESPONSE_MIME_PREFIX
: take reqres as a root when one of the given RESPONSE_MIME_PREFIX option arguments is a prefix of its response_mime (of hoardy-web get --expr, which see); given prefixes will only ever be matched against canonicalized MIME types; in short, this option defines a whitelisted element rule--root-response-mime-re RESPONSE_MIME_RE
: take reqres as a root when one of the given RESPONSE_MIME_RE regular expressions matches its response_mime (of hoardy-web get --expr, which see); given regular expressions will only ever be matched against canonicalized MIME types; this option matches the given regular expression against the whole input value; to match against any part of the input value, use .*<re>.* or ^.*<re>.*$; in short, this option defines a whitelisted element rule--root-not-response-mime NOT_RESPONSE_MIME
: take reqres as a root when none of the given NOT_RESPONSE_MIME option arguments are equal to its response_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-not-response-mime-prefix NOT_RESPONSE_MIME_PREFIX
: take reqres as a root when none of the given NOT_RESPONSE_MIME_PREFIX option arguments are a prefix of its response_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-not-response-mime-re NOT_RESPONSE_MIME_RE
: take reqres as a root when none of the given NOT_RESPONSE_MIME_RE regular expressions match its response_mime (of hoardy-web get --expr, which see); option argument format and caveats are idential to the not-less option above; in short, this option defines a blacklisted element rule--root-or-grep OR_PATTERN, --root-grep OR_PATTERN
: take reqres as a root when at least one of the given OR_PATTERN option arguments is a substring of at least one of the elements of the list containing raw_url, url, pretty_url, all request.headers, request.body, all response.headers, and response.body (of hoardy-web get --expr, which see); each HTTP header of *.headers is matched as a single <header_name>: <header_value> value; at the moment, binary values are matched against given option arguments by encoding the latter into UTF-8 first, which means that *.headers and *.body values that use encodings other than UTF-8 are not guaranteed to match properly; in short, this option defines a whitelisted element rule--root-or-grep-re OR_PATTERN_RE, --root-grep-re OR_PATTERN_RE
: take reqres as a root when at least one of the given OR_PATTERN_RE regular expressions matches a substring of at least one of the elements of the above list; matching caveats are the same as above; in short, this option defines a whitelisted element rule--root-not-or-grep NOT_OR_PATTERN, --root-not-grep NOT_OR_PATTERN
: take reqres as a root when none of the given NOT_OR_PATTERN option arguments are substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-not-or-grep-re NOT_OR_PATTERN_RE, --root-not-grep-re NOT_OR_PATTERN_RE
: take reqres as a root when none of the given NOT_OR_PATTERN_RE regular expressions match any substrings of any of the elements of the above list; matching caveats are the same as above; in short, this option defines a blacklisted element rule--root-and-grep AND_PATTERN
: take reqres as a root when each of the given AND_PATTERN option arguments is a substring of some element of the above list; matching caveats are the same as above--root-and-grep-re AND_PATTERN_RE
: take reqres as a root when each of the given AND_PATTERN_RE regular expressions matches a substring of some element of the above list; matching caveats are the same as above--root-not-and-grep NOT_AND_PATTERN
: take reqres as a root when one or more of the given NOT_AND_PATTERN option arguments is not a substring of the elements of the above list; matching caveats are the same as above--root-not-and-grep-re NOT_AND_PATTERN_RE
: take reqres as a root when one or more of the given NOT_AND_PATTERN_RE regular expressions fails to match any substrings of the elements of the above list; matching caveats are the same as above--root-and EXPR
: take reqres as a root when all of the given expressions of the same format as hoardy-web get --expr (which see) evaluate to true--root-or EXPR
: take reqres as a root when some of the given expressions of the same format as hoardy-web get --expr (which see) evaluate to truerecursion depth:
-d DEPTH, --depth DEPTH
: maximum recursion depth level; the default is 0, which means "--root-* documents and their requisite resources only"; setting this to 1 will also mirror one level of documents referenced via jump and action links, if those are being remapped to local files with --remap-*; higher values will mean even more recursionRun an archiving server and/or serve given input files for replay over HTTP.
Algorithm:
PATH:
GET /web/<selector>/<url>;selector ends with *:
selector as a time interval;url as glob pattern;url has indexed visits, respond with data most closely matching the given selector;url contains *, interpret it as a glob pattern;url;Not Found page with a list of similar URLs and visits matching the pattern.The end.
options:
-q, --quiet
: don't don't print end-of-filtering warnings, don't print optional informational messages, and don't log HTTP requests to stderrcaching:
--max-memory INT
: the caches, all taken together, must not take more than this much memory in MiB; default: 1024;
making this larger improves performance;
the actual maximum whole-program memory consumption is O(<size of the largest reqres> + <numer of indexed files> + <sum of lengths of all their --output paths> + <--max-memory>)error handling:
--errors {fail,skip,ignore}
: when an error occurs:
fail: report failure and stop the execution; defaultskip: report failure but skip the reqres that produced it from the output and continueignore: skip, but don't report the failurepath ordering:
--paths-given-order
: argv and --stdin0 PATHs are processed in the order they are given; default--paths-sorted
: argv and --stdin0 PATHs are processed in lexicographic order--paths-reversed
: argv and --stdin0 PATHs are processed in reverse lexicographic order--walk-fs-order
: recursive file system walk is done in the order readdir(2) gives results--walk-sorted
: recursive file system walk is done in lexicographic order; default--walk-reversed
: recursive file system walk is done in reverse lexicographic orderinput loading:
--load-any
: for each given input PATH, decide which loader to use based on its file extension; default--load-wrr
: load all inputs using the single-WRR per-file loader--load-wrrb
: load all inputs using the WRR bundle loader, this will load separate WRR files as single-WRR bundles too--load-mitmproxy
: load inputs using the mitmproxy dump loader--stdin0
: read zero-terminated PATHs from stdin, these will be processed after PATHs specified as command-line argumentsPATH
: inputs, can be a mix of files and directories (which will be traversed recursively)MIME type sniffing; this controls the use of the mimesniff algorithm; for this sub-command higher values make the scrub function (which see) censor out more things when -unknown, -styles, or -scripts options are set; in particular, at the moment, with --sniff-paranoid and -scripts most plain text files will be censored out as potential JavaScript:
--sniff-default
: run mimesniff when the spec says it should be run; i.e. trust Content-Type HTTP headers most of the time; default--sniff-force
: run mimesniff regardless of what Content-Type and X-Content-Type-Options HTTP headers say; i.e. for each reqres, run mimesniff algorithm on the Content-Type HTTP header and the actual contents of (request|response).body (depending on the first argument of scrub) to determine what the body actually contains, then interpret the data as intersection of what Content-Type and mimesniff claim it to be; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain--sniff-paranoid
: do what --sniff-force does, but interpret the results in the most paranoid way possible; e.g. if Content-Type says text/plain but mimesniff says text/plain or text/javascript, interpret it as text/plain or text/javascript; which, for instance, will then make scrub with -scripts censor it out, since it can be interpreted as a scriptdefault input filters:
--ignore-some-inputs
: initialize input filters to --status-re ".(200|30[012378])C"; this matches complete 200 OK and 300 Multiple Choices responses and various redirects; default--index-all-inputs
: do not set any input filters by default; if you set this option, you should also probably set at least --status-re ".*C" --not-status-re ".206.", unless you want hoardy-web mirror processing partially downloaded dataHTTP server options:
--host HOST
: listen on what host/IP; default: 127.0.0.1--port PORT
: listen on what port; default: 3210--debug-bottle
: run with bottle's debugging enabledexpression evaluation:
-e EXPR, --expr EXPR
: an expression to compute, same expression format and semantics as hoardy-web get --expr (which see); can be specified multiple times; the default depends on --remap-* options belowrendering of --expr values:
--not-separated
: render --expr values into outputs without separating them with anything, just concatenate them--lf-separated
: render --expr values into outputs separated with \n (LF) newline characters; default--zero-separated
: render --expr values into outputs separated with \0 (NUL) bytesdefault value of --expr:
--raw-qbody
: set the default value of --expr to request.body|eb; i.e. produce the raw request body--raw-sbody, --no-remap
: set the default value of --expr to response.body|eb; i.e. produce the raw response body--remap-id
: set the default value of --expr to response.body|eb|scrub response +all_refs,-inline_headers; i.e. scrub response body as follows: remap all URLs with an identity function (which, as a whole, is NOT an identity function, it will transform all relative URLs into absolute ones), censor out all dynamic content (e.g. JavaScript); results will NOT be self-contained--remap-void
: set the default value of --expr to response.body|eb|scrub response -all_refs,-inline_headers; i.e. scrub response body as follows: remap all URLs into javascript:void(0) and empty data: URLs, censor out all dynamic content; results will be self-contained--remap-semi
: set the default value of --expr to response.body|eb|scrub response *jumps,/actions,/reqs,-inline_headers; i.e. scrub response body as follows: keeps all jump links pointing to unarchived URLs as-is, remap all other links and references to their replay URLs, censor out all dynamic content; results will be self-contained--remap-all
: set the default value of --expr to response.body|eb|scrub response &all_refs,-inline_headers; i.e. scrub response body as follows: remap all links and references to their replay URLs, even when they are not available in the index, censor out all dynamic content; results will be self-contained; defaultbuckets:
--default-bucket NAME, --default-profile NAME
: default bucket name to use when a client does not specify any; default: default--ignore-buckets, --ignore-profiles
: ignore bucket names specified by clients and always use --default-bucket insteadfile output options:
--compress
: compress new archivals before dumping them to disk; default--no-compress, --uncompressed
: dump new archivals to disk without compressionfile outputs:
-t ARCHIVE_DESTINATION, --to ARCHIVE_DESTINATION, --archive-to ARCHIVE_DESTINATION
: archiving destination directory; if left unset, which is the default, then archiving server support will be disabled-i, --implicit
: prepend ARCHIVE_DESTINATION to the list of input PATHs-o OUTPUT_FORMAT, --output OUTPUT_FORMAT
: format describing generated output paths, an alias name or "format:" followed by a custom pythonic %-substitution string; same expression format as hoardy-web organize --output (which see); default: defaultnew --outputs printing:
--no-print
: don't print anything; default-l, --lf-terminated
: print absolute paths of newly produced or replaced files terminated with \n (LF) newline characters-z, --zero-terminated
: print absolute paths of newly produced or replaced files terminated with \0 (NUL) bytesreplay what:
--no-replay
: disable replay functionality, makes this into an archive-only server, like hoardy-web-sas is--oldest
: for each URL, index and replay only the oldest visit; if --to is set, archiving a new visit for a URL will keep the indexed and replayable version as-is--nearest INTERVAL_DATE
: for each URL, index and replay only the visit closest to the given INTERVAL_DATE value; if --to is set, archiving a new visit for a URL will replace the indexed and replayable version if INTERVAL_DATE is in the future and keep it as-is otherwise; the INTERVAL_DATE is parsed as a time interval the middle point of which is taken as target value; e.g., 2024 becomes 2024-07-02 00:00:00 (which is the exact middle point of that year), 2024-12-31 becomes 2024-12-31 12:00:00, 2024-12-31 12 -> 2024-12-31 12:30:00, 2024-12-31 12:00 -> 2024-12-31 12:00:30, 2024-12-31 12:00:01 -> 2024-12-31 12:00:01.5, etc--latest
: {fiar} the latest visit; if --to is set, archiving a new visit for a URL will replace the indexed and replayable version with a new one--all
: index and replay all visits to all available URLs; if --to is given, archiving a new visit for a URL will update the index and make the new visit available for replay; defaultreplay how:
--web
: replay HTTP responses as close as possible to their original captures; default--mirror
: replay HTTP responses like hoardy-web mirror does; setting this option will disable replay of all HTTP headers except for Location and enable inline_headers option in scrub calls used in default EXPRs, similar to hoardy-web mirror; i.e., enabling this option will, essentially, turn this sub-command into an on-demand hoardy-web mirror which you can query with curl or some suchPretty-print all reqres in ../simple_server/pwebarc-dump using an abridged (for ease of reading and rendering) verbose textual representation:
hoardy-web pprint ../simple_server/pwebarc-dump
Pipe raw response body from a given WRR file to stdout:
hoardy-web get ../simple_server/pwebarc-dump/path/to/file.wrr
Pipe response body scrubbed of dynamic content from a given WRR file to stdout:
hoardy-web get -e "response.body|eb|scrub response defaults" ../simple_server/pwebarc-dump/path/to/file.wrr
Get first 2 bytes (4 characters) of a hex digest of sha256 hash computed on the URL without the fragment/hash part:
hoardy-web get -e "net_url|to_ascii|sha256|take_prefix 2|to_hex" ../simple_server/pwebarc-dump/path/to/file.wrr
Pipe response body from a given WRR file to stdout, but less efficiently, by generating a temporary file and giving it to cat:
hoardy-web run cat ../simple_server/pwebarc-dump/path/to/file.wrr
Thus hoardy-web run can be used to do almost anything you want, e.g.
hoardy-web run less ../simple_server/pwebarc-dump/path/to/file.wrr
hoardy-web run -- sort -R ../simple_server/pwebarc-dump/path/to/file.wrr
hoardy-web run -n 2 -- diff -u ../simple_server/pwebarc-dump/path/to/file-v1.wrr ../simple_server/pwebarc-dump/path/to/file-v2.wrr
List paths of all WRR files from ../simple_server/pwebarc-dump that contain complete 200 OK responses with text/html bodies larger than 1K:
hoardy-web find --status-re .200C --response-mime text/html --and "response.body|len|> 1024" ../simple_server/pwebarc-dump
Rename all WRR files in ../simple_server/pwebarc-dump/default according to their metadata using --output default (see the hoardy-web organize section for its definition, the default format is designed to be human-readable while causing almost no collisions, thus making num substitution parameter to almost always stay equal to 0, making things nice and deterministic):
hoardy-web organize ../simple_server/pwebarc-dump/default
alternatively, just show what would be done
hoardy-web organize --dry-run ../simple_server/pwebarc-dump/default
Pretty-print all reqres in ../simple_server/pwebarc-dump by dumping their whole structure into an abridged Pythonic Object Representation (repr):
hoardy-web stream --expr . ../simple_server/pwebarc-dump
hoardy-web stream -e . ../simple_server/pwebarc-dump
Pretty-print all reqres in ../simple_server/pwebarc-dump using the unabridged verbose textual representation:
hoardy-web pprint --unabridged ../simple_server/pwebarc-dump
hoardy-web pprint -u ../simple_server/pwebarc-dump
Pretty-print all reqres in ../simple_server/pwebarc-dump by dumping their whole structure into the unabridged Pythonic Object Representation (repr) format:
hoardy-web stream --unabridged --expr . ../simple_server/pwebarc-dump
hoardy-web stream -ue . ../simple_server/pwebarc-dump
Produce a JSON list of [<file path>, <time it finished loading in seconds since UNIX epoch>, <URL>] tuples (one per reqres) and pipe it into jq for indented and colored output:
hoardy-web stream --format=json -ue fs_path -e finished_at -e request.url ../simple_server/pwebarc-dump | jq .
Similarly, but produce a CBOR output:
hoardy-web stream --format=cbor -ue fs_path -e finished_at -e request.url ../simple_server/pwebarc-dump | less
Concatenate all response bodies of all the requests in ../simple_server/pwebarc-dump:
hoardy-web stream --format=raw --not-terminated -ue "response.body|eb" ../simple_server/pwebarc-dump | less
Print all unique visited URLs, one per line:
hoardy-web stream --format=raw --lf-terminated -ue request.url ../simple_server/pwebarc-dump | sort | uniq
Same idea, but using NUL bytes, with some post-processing, and two URLs per line:
hoardy-web stream --format=raw --zero-terminated -ue request.url ../simple_server/pwebarc-dump | sort -z | uniq -z | xargs -0 -n2 echo
Trying to use response bodies produced by hoardy-web stream --format=json is likely to result garbled data as JSON can't represent raw sequences of bytes, thus binary data will have to be encoded into UNICODE using replacement characters:
hoardy-web stream --format=json -ue . ../simple_server/pwebarc-dump/path/to/file.wrr | jq .
The most generic solution to this is to use --format=cbor instead, which would produce a verbose CBOR representation equivalent to the one used by --format=json but with binary data preserved as-is:
hoardy-web stream --format=cbor -ue . ../simple_server/pwebarc-dump/path/to/file.wrr | less
Or you could just dump raw response bodies separately:
hoardy-web stream --format=raw -ue response.body ../simple_server/pwebarc-dump/path/to/file.wrr | less
hoardy-web get ../simple_server/pwebarc-dump/path/to/file.wrr | less
./test-cli.sh [--help] [--wine] [--all|--subset NUM] [--long|--short NUM] PATH [PATH ...]Sanity check and test hoardy-web command-line interface.
Run tests on each of given WRR bundles:
./test-cli.sh ~/Downloads/Hoardy-Web-export-*.wrrb
Run tests on all WRR files in a given directory:
./test-cli.sh ~/hoardy-web/latest/archiveofourown.org
Run tests on a random subset of WRR files in a given directory:
./test-cli.sh --subset 100 ~/hoardy-web/raw
Run tests on each of given WRR bundles, except run long tests on a small subset of each:
./test-cli.sh --short 16 ~/Downloads/Hoardy-Web-export-*.wrrb
Make --stdin0 input and test on it, as if it was a WRR bundle:
hoardy-web find -z ~/hoardy-web/latest/archiveofourown.org ~/hoardy-web/latest/example.org > ./bunch.wrrtest
./test-cli.sh ./bunch.wrrtest
FAQs
Inspect, search, organize, programmatically extract values and generate static website mirrors from, archive, view, and replay `HTTP` archives/dumps in `WRR` ("Web Request+Response", produced by the `Hoardy-Web` Web Extension browser add-on) and `mitmproxy` (`mitmdump`) file formats.
We found that hoardy-web demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The latest Opengrep releases add Apex scanning, precision rule tuning, and performance gains for open source static code analysis.

Security News
npm now supports Trusted Publishing with OIDC, enabling secure package publishing directly from CI/CD workflows without relying on long-lived tokens.

Research
/Security News
A RubyGems malware campaign used 60 malicious packages posing as automation tools to steal credentials from social media and marketing tool users.