
Product
Announcing Precomputed Reachability Analysis in Socket
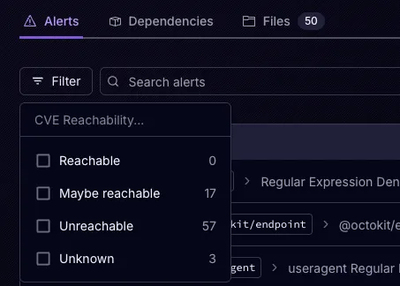
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.
By Martin Torp - Jul 30, 2025
log-distance-measures
Advanced tools
Python package with the implementation of different distance measures between two event logs, from the control-flow, temporal, and queuing perspectives.
![]()
Python package with the implementation of different distance measures between two event logs, from the control-flow, temporal, and workforce perspectives:
Package available in PyPI: https://pypi.org/project/log-distance-measures/. Install it with:
pip install log-distance-measures
import pandas as pd
from log_distance_measures.config import EventLogIDs
# Set event log column ID mapping
event_log_ids = EventLogIDs( # These values are stored in DEFAULT_CSV_IDS
case="case_id",
activity="Activity",
start_time="start_time",
end_time="end_time"
)
# Read and transform time attributes
event_log = pd.read_csv("/path/to/event_log.csv")
event_log[event_log_ids.start_time] = pd.to_datetime(event_log[event_log_ids.start_time], utc=True)
event_log[event_log_ids.end_time] = pd.to_datetime(event_log[event_log_ids.end_time], utc=True)
Distance measure between two event logs with the same number of traces (L1 and L2) comparing the control-flow dimension (see "Camargo M, Dumas M, González-Rojas O. 2021. Discovering generative models from event logs: data-driven simulation vs deep learning. PeerJ Computer Science 7:e577 https://doi.org/10.7717/peerj-cs.577" for a detailed description of a similarity version of this measure).
from log_distance_measures.config import DEFAULT_CSV_IDS
from log_distance_measures.control_flow_log_distance import control_flow_log_distance
# Call passing the event logs, and its column ID mappings
distance = control_flow_log_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
)
Distance measure between two event logs computing the difference in the frequencies of the n-grams observed in the event
logs (being the n-grams of an event log all the groups of n consecutive elements observed in it).
n, get all sequences of n activities (n-gram) observed in each event log (adding artificial
activities to the start and end of each trace to consider these as well, e.g., 0 - 0 - A for a trace starting
with A and an n = 3).A - B - C in the first event log w.r.t. its frequency in the second event log).from log_distance_measures.config import DEFAULT_CSV_IDS
from log_distance_measures.n_gram_distribution import n_gram_distribution_distance
# Call passing the event logs, and its column ID mappings
distance = n_gram_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
n=3 # trigrams
)
Distance measure computing how different the histograms of the timestamps of two event logs are, discretizing the timestamps by absolute hour.
02/05/2022 10:00:00 and 02/05/2022 10:59:59
go to the same bin).from log_distance_measures.absolute_event_distribution import absolute_event_distribution_distance
from log_distance_measures.config import AbsoluteTimestampType, DEFAULT_CSV_IDS, discretize_to_hour
# Call passing the event logs, its column ID mappings, timestamp type, and discretize function
distance = absolute_event_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
discretize_type=AbsoluteTimestampType.BOTH, # Which timestamps to consider (start times and/or end times)
discretize_event=discretize_to_hour # Function to discretize the time of each timestamp (default by hour)
)
This EMD measure can be also used to compare the distribution of the start timestamps (
with AbsoluteHourEmdType.START), or the end timestamps (with AbsoluteHourEmdType.END), instead of both of them.
Furthermore, the binning is performed to hour by default, but it can be customized passing another function discretize the total amount of seconds to its bin.
import math
from log_distance_measures.absolute_event_distribution import absolute_event_distribution_distance
from log_distance_measures.config import AbsoluteTimestampType, DEFAULT_CSV_IDS, discretize_to_day
# EMD of the (END) timestamps distribution where each bin represents a day
distance = absolute_event_distribution_distance(
original_log, DEFAULT_CSV_IDS,
simulated_log, DEFAULT_CSV_IDS,
discretize_type=AbsoluteTimestampType.END,
discretize_event=discretize_to_day
)
# EMD of the timestamps distribution where each bin represents a week
distance = absolute_event_distribution_distance(
original_log, DEFAULT_CSV_IDS,
simulated_log, DEFAULT_CSV_IDS,
discretize_event=lambda seconds: math.floor(seconds / 3600 / 24 / 7)
)
Distance measure computing how different the discretized histograms of the arrival events of two event logs are.
02/05/2022 10:00:00 and 02/05/2022 10:59:59
go to the same bin).from log_distance_measures.case_arrival_distribution import case_arrival_distribution_distance
from log_distance_measures.config import DEFAULT_CSV_IDS, discretize_to_hour
distance = case_arrival_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
discretize_event=discretize_to_hour # Function to discretize each timestamp (default by hour)
)
Distance measure computing how different the histograms of the timestamps of two event logs are, comparing all the instants recorded in the same weekday together, and discretizing them to the hour in the day.
Extra 1: If there are no recorded timestamps for one of the weekdays in both logs, no distance is measured for that day. Extra 2: If there are no recorded timestamps for one of the weekdays in one of the logs, the distance for that day is set to 23 (the maximum distance for two histograms with values from 0 to 23)
from log_distance_measures.circadian_event_distribution import circadian_event_distribution_distance
from log_distance_measures.config import AbsoluteTimestampType, DEFAULT_CSV_IDS
distance = circadian_event_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
discretize_type=AbsoluteTimestampType.BOTH # Consider both start/end timestamps of each activity instance
)
Similar to the Absolute Event Distribution Distance, the Circadian Event Distribution Distance can be also used to
compare the distribution of the start timestamps (with AbsoluteHourEmdType.START), or the end timestamps (
with AbsoluteHourEmdType.END), instead of both of them.
Distance measure computing how different the histograms of the relative (w.r.t. the start of each case) timestamps of two event logs are, discretizing the timestamps by absolute hour.
0 and 3599 go to the same bin).from log_distance_measures.config import AbsoluteTimestampType, DEFAULT_CSV_IDS, discretize_to_hour
from log_distance_measures.relative_event_distribution import relative_event_distribution_distance
# Call passing the event logs, its column ID mappings, timestamp type, and discretize function
distance = relative_event_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
discretize_type=AbsoluteTimestampType.BOTH, # Which timestamps to consider (start times and/or end times)
discretize_event=discretize_to_hour # Function to discretize the time of each timestamp (default by hour)
)
Similar to the Absolute Event Distribution Distance, the Relative Event Distribution Distance can be also used to
compare the distribution of the start timestamps (with AbsoluteHourEmdType.START), or the end timestamps (
with AbsoluteHourEmdType.END), instead of both of them.
Distance measure computing how different the cycle time discretized histograms of two event logs are.
import pandas as pd
from log_distance_measures.config import DEFAULT_CSV_IDS
from log_distance_measures.cycle_time_distribution import cycle_time_distribution_distance
distance = cycle_time_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
bin_size=pd.Timedelta(hours=1) # Bins of 1 hour
)
In situations where the start of the log was sliced at a specific timestamp (reference_point), some cases may be partially included as they were ongoing at time reference_point. We consider their duration from reference_point until their end as their "remaining cycle time". This distance measure computes how different the remaining cycle times of the cases (ongoing at a point reference_point) of two event logs are (as discretized histograms).
import pandas as pd
from log_distance_measures.config import DEFAULT_CSV_IDS
from log_distance_measures.remaining_time_distribution import remaining_time_distribution_distance
distance = remaining_time_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
reference_point=pd.Timestamp("2025-02-20T10:00:00.000+02:00"), # Timestamp considered as reference point
bin_size=pd.Timedelta(hours=1) # Bins of 1 hour
)
Distance measure computing how different the histograms of the number of active resources of two event logs are, comparing the number of active resources of each hour of each weekday.
Extra 1: If there are no recorded active resources for one of the weekdays in both logs, no distance is measured for that day. Extra 2: If there are no recorded active resources for one of the weekdays in one of the logs, the distance for that day is set to 23 (the maximum distance for two histograms with values from 0 to 23)
from log_distance_measures.circadian_workforce_distribution import circadian_workforce_distribution_distance
from log_distance_measures.config import DEFAULT_CSV_IDS
distance = circadian_workforce_distribution_distance(
original_log, DEFAULT_CSV_IDS, # First event log and its column id mappings
simulated_log, DEFAULT_CSV_IDS, # Second event log and its column id mappings
)
FAQs
Python package with the implementation of different distance measures between two event logs, from the control-flow, temporal, and queuing perspectives.
We found that log-distance-measures demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.

Product
Add secure dependency scanning to Claude Desktop with Socket MCP, a one-click extension that keeps your coding conversations safe from malicious packages.