
Product
Introducing Data Exports
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
By Ola Adekola - Apr 23, 2026
onnx-tool
Advanced tools
📄 简体中文 | ✨ New Project: AI-Enhancement-Filter (powered by onnx-tool)


A comprehensive toolkit for analyzing, optimizing, and transforming ONNX models with advanced capabilities for LLMs, diffusion models, and computer vision architectures.
| Domain | Models |
|---|---|
| NLP | BERT, T5, GPT, LLaMa, MPT (TransformerModel) |
| Diffusion | Stable Diffusion (TextEncoder, VAE, UNet) |
| CV | Detic, BEVFormer, SSD300_VGG16, ConvNeXt, Mask R-CNN, Silero VAD |
| Audio | Sovits, LPCNet |
Profile 10 Hugging Face models in under one second. Export ONNX models with llama.cpp-like simplicity (code).
| model name(1k input) | MACs(G) | Parameters(G) | KV Cache(G) |
|---|---|---|---|
| gpt-j-6b | 6277 | 6.05049 | 0.234881 |
| yi-1.5-34B | 35862 | 34.3889 | 0.125829 |
| microsoft/phi-2 | 2948 | 2.77944 | 0.167772 |
| Phi-3-mini-4k | 4083 | 3.82108 | 0.201327 |
| Phi-3-small-8k-instruct | 7912 | 7.80167 | 0.0671089 |
| Phi-3-medium-4k-instruct | 14665 | 13.9602 | 0.104858 |
| Llama3-8B | 8029 | 8.03026 | 0.0671089 |
| Llama-3.1-70B-Japanese-Instruct-2407 | 72888 | 70.5537 | 0.167772 |
| QWen-7B | 7509 | 7.61562 | 0.0293601 |
| Qwen2_72B_Instruct | 74895 | 72.7062 | 0.167772 |
| model_type_4bit_kv16bit | memory_size(GB) | Ultra-155H_TTFT | Ultra-155H_TPOT | Arc-A770_TTFT | Arc-A770_TPOT | H100-PCIe_TTFT | H100-PCIe_TPOT |
|---|---|---|---|---|---|---|---|
| gpt-j-6b | 3.75678 | 1.0947 | 0.041742 | 0.0916882 | 0.00670853 | 0.0164015 | 0.00187839 |
| yi-1.5-34B | 19.3369 | 5.77095 | 0.214854 | 0.45344 | 0.0345302 | 0.0747854 | 0.00966844 |
| microsoft/phi-2 | 1.82485 | 0.58361 | 0.0202761 | 0.0529628 | 0.00325866 | 0.010338 | 0.000912425 |
| Phi-3-mini-4k | 2.49649 | 0.811173 | 0.0277388 | 0.0745356 | 0.00445802 | 0.0147274 | 0.00124825 |
| Phi-3-small-8k-instruct | 4.2913 | 1.38985 | 0.0476811 | 0.117512 | 0.00766303 | 0.0212535 | 0.00214565 |
| Phi-3-medium-4k-instruct | 7.96977 | 2.4463 | 0.088553 | 0.198249 | 0.0142317 | 0.0340576 | 0.00398489 |
| Llama3-8B | 4.35559 | 1.4354 | 0.0483954 | 0.123333 | 0.00777784 | 0.0227182 | 0.00217779 |
| Llama-3.1-70B-Japanese-Instruct-2407 | 39.4303 | 11.3541 | 0.438114 | 0.868475 | 0.0704112 | 0.137901 | 0.0197151 |
| QWen-7B | 4.03576 | 1.34983 | 0.0448417 | 0.11722 | 0.00720671 | 0.0218461 | 0.00201788 |
| Qwen2_72B_Instruct | 40.5309 | 11.6534 | 0.450343 | 0.890816 | 0.0723766 | 0.14132 | 0.0202654 |
💡 Latencies computed from hardware specs – no actual inference required
Intuitive API for model manipulation:
from onnx_tool import Model
model = Model('model.onnx') # Load any ONNX file
graph = model.graph # Access computation graph
node = graph.nodemap['Conv_0'] # Modify operator attributes
tensor = graph.tensormap['weight'] # Edit tensor data/types
model.save_model('modified.onnx') # Persist changes
See comprehensive examples in benchmark/examples.py.
All profiling relies on precise shape inference:



📚 Learn more:
Transform exported ONNX graphs into efficient Compute Graphs by removing shape-calculation overhead:

Use Cases:
Reuses temporary buffers to minimize peak memory usage – critical for LLMs and high-res CV models.
| model | Native Memory Size(MB) | Compressed Memory Size(MB) | Compression Ratio(%) |
|---|---|---|---|
| StableDiffusion(VAE_encoder) | 14,245 | 540 | 3.7 |
| StableDiffusion(VAE_decoder) | 25,417 | 1,140 | 4.48 |
| StableDiffusion(Text_encoder) | 215 | 5 | 2.5 |
| StableDiffusion(UNet) | 36,135 | 2,232 | 6.2 |
| GPT2 | 40 | 2 | 6.9 |
| BERT | 2,170 | 27 | 1.25 |
✅ Typical models achieve >90% activation memory reduction
📌 Implementation:benchmark/compression.py
Essential for deploying large models on memory-constrained devices:
| Quantization Scheme | Size vs FP32 | Example (7B model) |
|---|---|---|
| FP32 (baseline) | 1.00× | 28 GB |
| FP16 | 0.50× | 14 GB |
| INT8 (per-channel) | 0.25× | 7 GB |
| INT4 (block=32, symmetric) – llama.cpp | 0.156× | 4.4 GB |
Supported schemes:
📌 See benchmark/examples.py for implementation examples.
# PyPI (recommended)
pip install onnx-tool
# Latest development version
pip install --upgrade git+https://github.com/ThanatosShinji/onnx-tool.git
Requirements: Python ≥ 3.6
⚠️ Troubleshooting: If ONNX installation fails, try:
pip install onnx==1.8.1 && pip install onnx-tool
Comprehensive profiling of ONNX Model Zoo and SOTA models. Input shapes defined in data/public/config.py.
📥 Download pre-profiled models (with full tensor shapes):
p91k)
|
|
Contributions are welcome! Please open an issue or PR for:
FAQs
A tool for parsing, editing, optimizing, and profiling ONNX models.
We found that onnx-tool demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
Research
/Security News
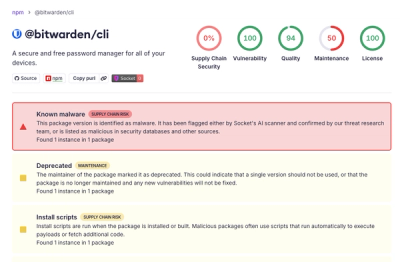
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.

Research
/Security News
Docker and Socket have uncovered malicious Checkmarx KICS images and suspicious code extension releases in a broader supply chain compromise.