Product
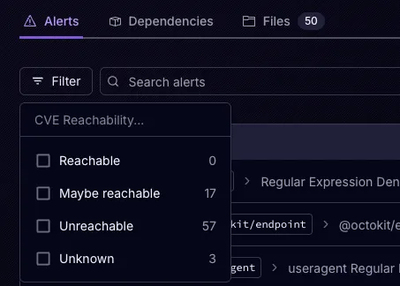
Announcing Precomputed Reachability Analysis in Socket
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.
By Martin Torp - Jul 30, 2025
Python library to work with the Visual Wake Words Dataset, comparable to pycococools for the COCO dataset.
pyvww.utils.VisualWakeWords inherits from pycocotools.coco.COCO and can be used in an similar fashion.
pyvww.pytorch.VisualWakeWordsClassification is a pytorch Dataset which can be used like any
image classification dataset.
The code is implemented in Python 3.7 and can be installed with pip:
pip install pyvww
The Visual Wake Words Dataset is derived from the publicly available COCO dataset.
To download the COCO dataset use the script download_coco.sh
bash scripts/download_mscoco.sh path-to-COCO-dataset year
Where year is an optional argument that can be either 2014 (default) or 2017.
The Visual Wake Words Dataset evaluates the accuracy on the minival image ids, and for training uses the remaining 115k images of the COCO training/validation dataset.
To create COCO annotation files that converts the 2014 or 2017 split to the minival split use:
scripts/create_coco_train_minival_split.py
TRAIN_ANNOTATIONS_FILE="path-to-mscoco-dataset/annotations/instances_train2014.json"
VAL_ANNOTATIONS_FILE="path-to-mscoco-dataset/annotations/instances_val2014.json"
DIR="path-to-mscoco-dataset/annotations/"
python scripts/create_coco_train_minival_split.py \
--train_annotations_file="${TRAIN_ANNOTATIONS_FILE}" \
--val_annotations_file="${VAL_ANNOTATIONS_FILE}" \
--output_dir="${DIR}"
(2014 can be replaced by 2017 if you downloaded the 2017 dataset)
The process of creating the Visual Wake Words dataset from COCO dataset is as follows. Each image is assigned a label 1 or 0. The label 1 is assigned as long as it has at least one bounding box corresponding to the object of interest (e.g. person) with the box area greater than a certain threshold (e.g. 0.5% of the image area).
To generate the new annotations, use the script scripts/create_visualwakewords_annotations.py.
MAXITRAIN_ANNOTATIONS_FILE="path-to-mscoco-dataset/annotations/instances_maxitrain.json"
MINIVAL_ANNOTATIONS_FILE="path-to-mscoco-dataset/annotations/instances_minival.json"
VWW_OUTPUT_DIR="new-path-to-visualwakewords-dataset/annotations/"
python scripts/create_visualwakewords_annotations.py \
--train_annotations_file="${MAXITRAIN_ANNOTATIONS_FILE}" \
--val_annotations_file="${MINIVAL_ANNOTATIONS_FILE}" \
--output_dir="${VWW_OUTPUT_DIR}" \
--threshold=0.005 \
--foreground_class='person'
The generated annotations follow the COCO Data format.
{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
info{
"year" : int,
"version" : str,
"description" : str,
"url" : str,
}
image{
"id" : int,
"width" : int,
"height" : int,
"file_name" : str,
"license" : int,
"flickr_url" : str,
"coco_url" : str,
"date_captured" : datetime,
}
license{
"id" : int,
"name" : str,
"url" : str,
}
annotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
The pyvww.pytorch.VisualWakeWordsClassification can be used in pytorch like any other pytorch image classification
dataset such as MNIST or ImageNet.
import torch
import pyvww
train_dataset = pyvww.pytorch.VisualWakeWordsClassification(root="path-to-mscoco-dataset/all",
annFile=".../visualwakewords/annotations/instances_train.json")
FAQs
Python API to work with the Visual Wake Words Dataset.
We found that pyvww demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.

Product
Add secure dependency scanning to Claude Desktop with Socket MCP, a one-click extension that keeps your coding conversations safe from malicious packages.