Sashimi — study the organization and evolution of corpora
A Python module for mixed-methods qualitative studies of large textual or
symbolic corpora, providing applications of statistical models accompanied by
tailored interactive visualizations. It affords the detection of both textual
and metadata structures by employing stochastic block modeling (SBM) from
graph-tool or (currently deprecated) word embedding from gensim.
Statistical models
- Domain-topic models
- Synthesizes document clustering (domain modeling) and topic modeling (term clustering).
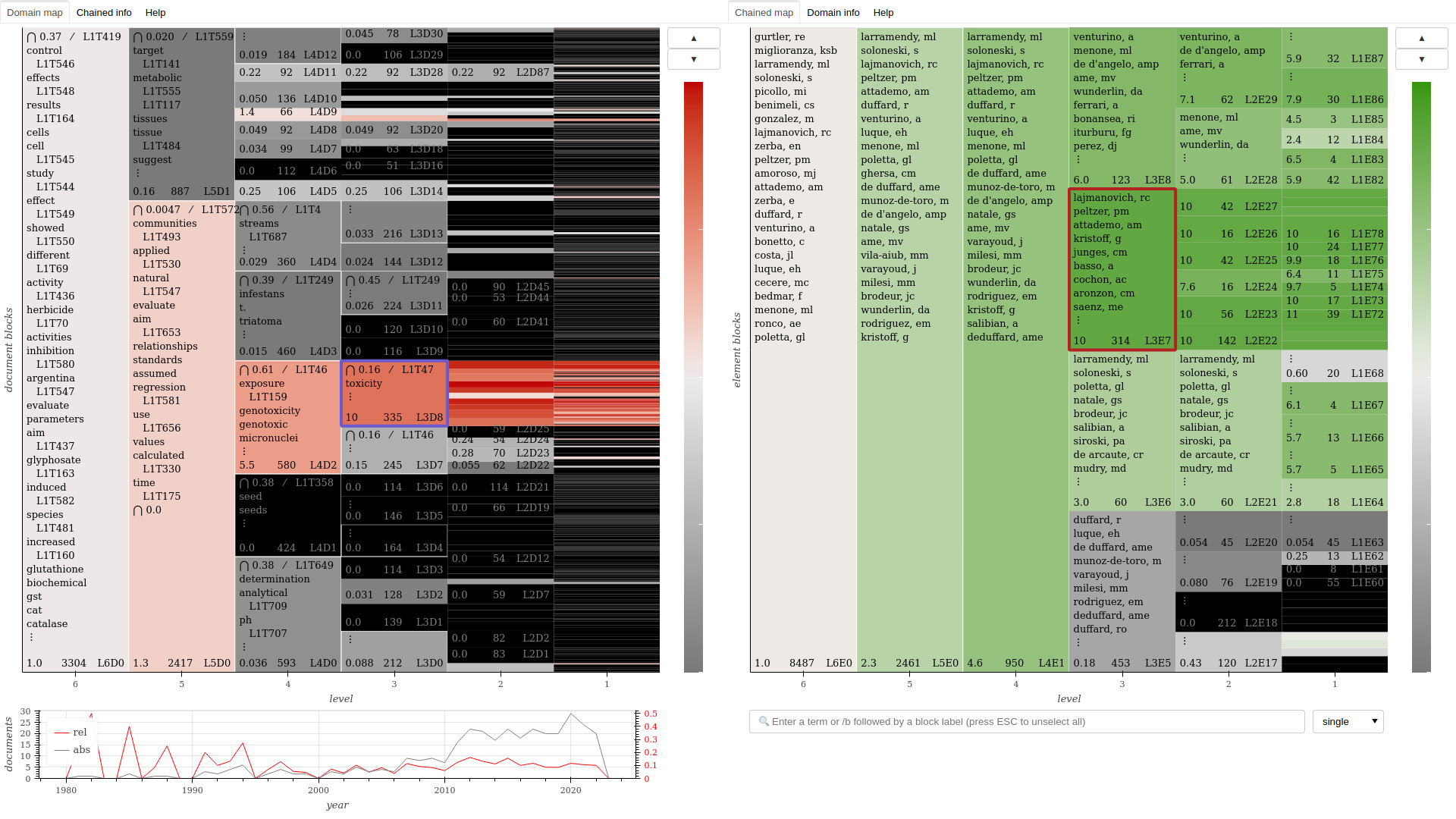
- Domain-chained models
- Extrapolates modeled domains to partition other dimensions of the corpus such as time, people, institutions, categories or places.
Human model-data interfaces
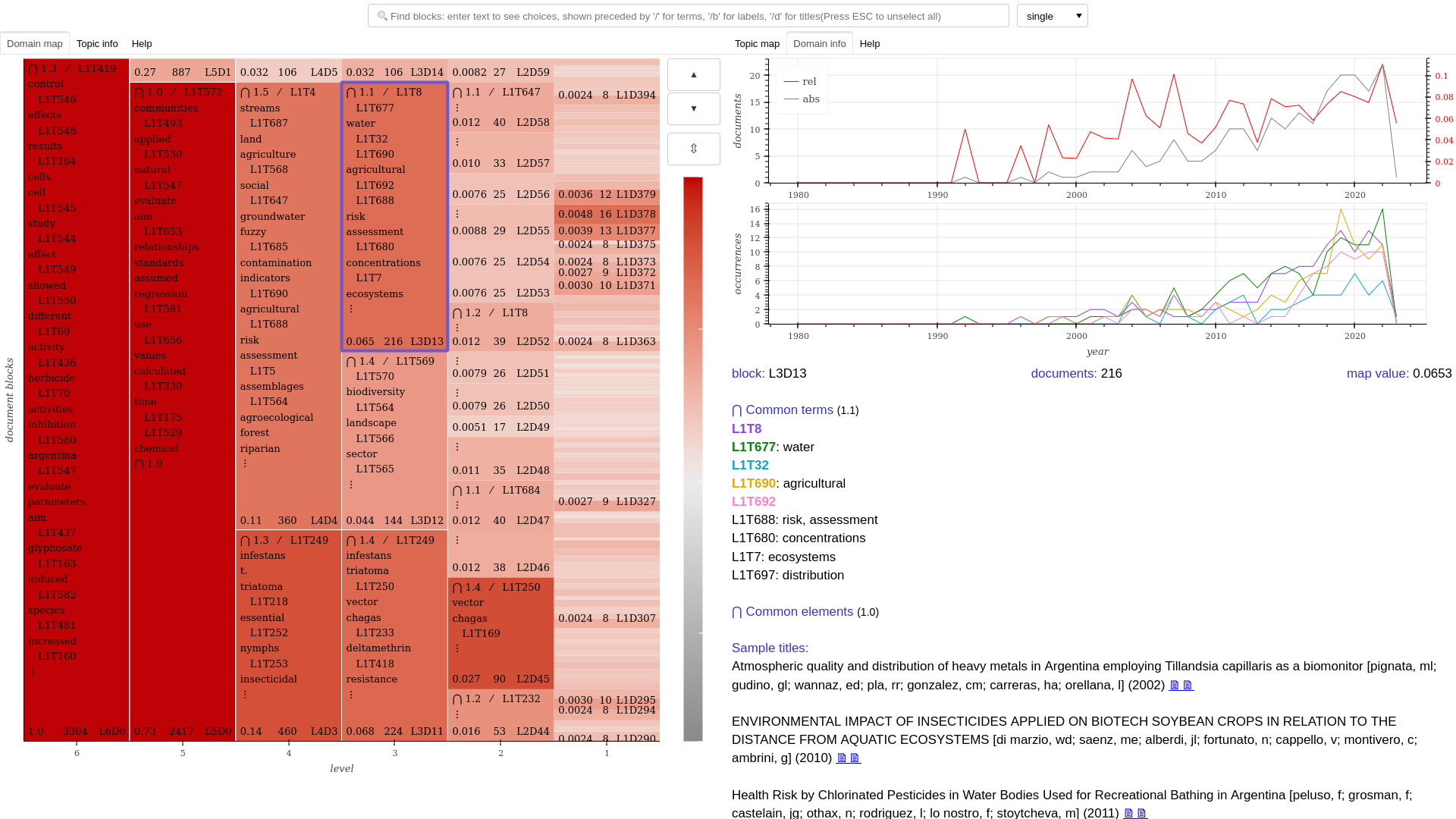
- Domain maps
- An interactive HTML document to explore the corpus and its clusters, enhanced with histograms and a search function.
- Domain tables
- Ideal for systematic annotation of clusters.
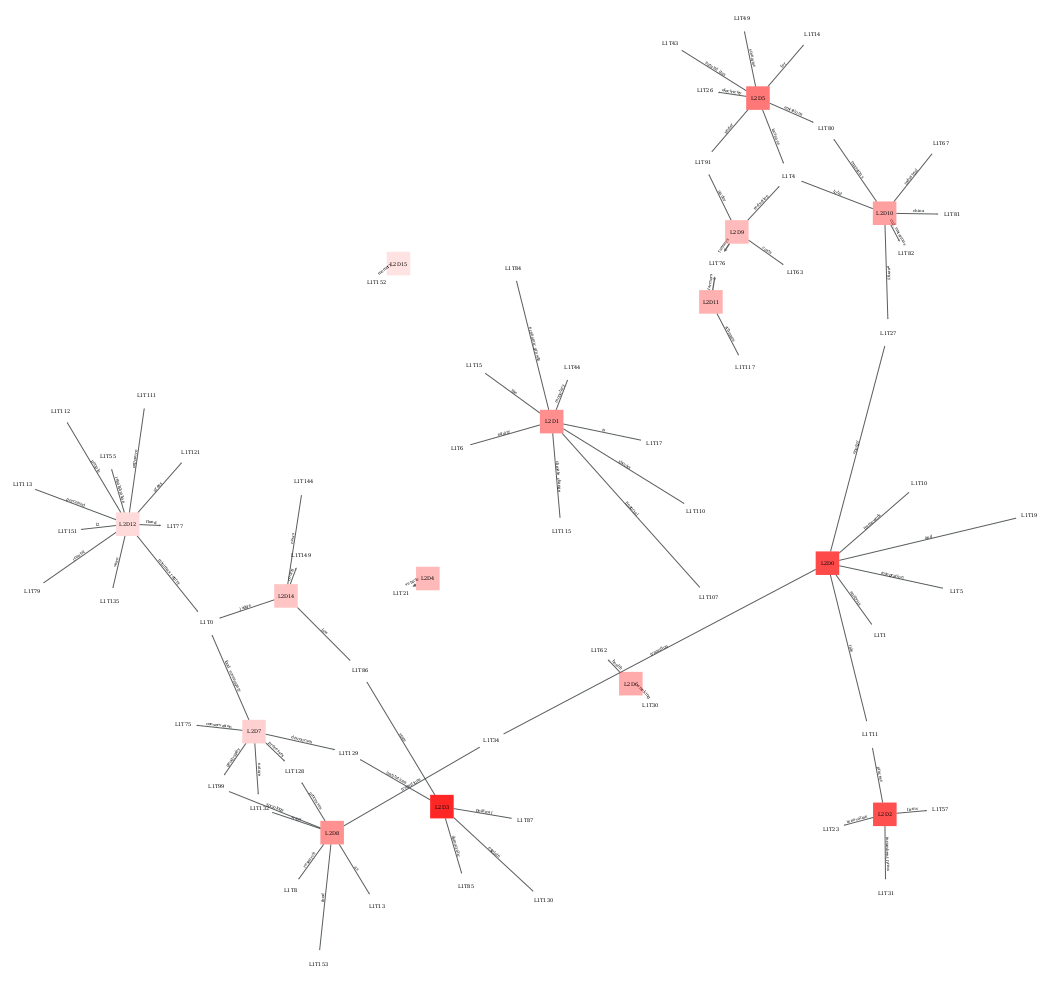
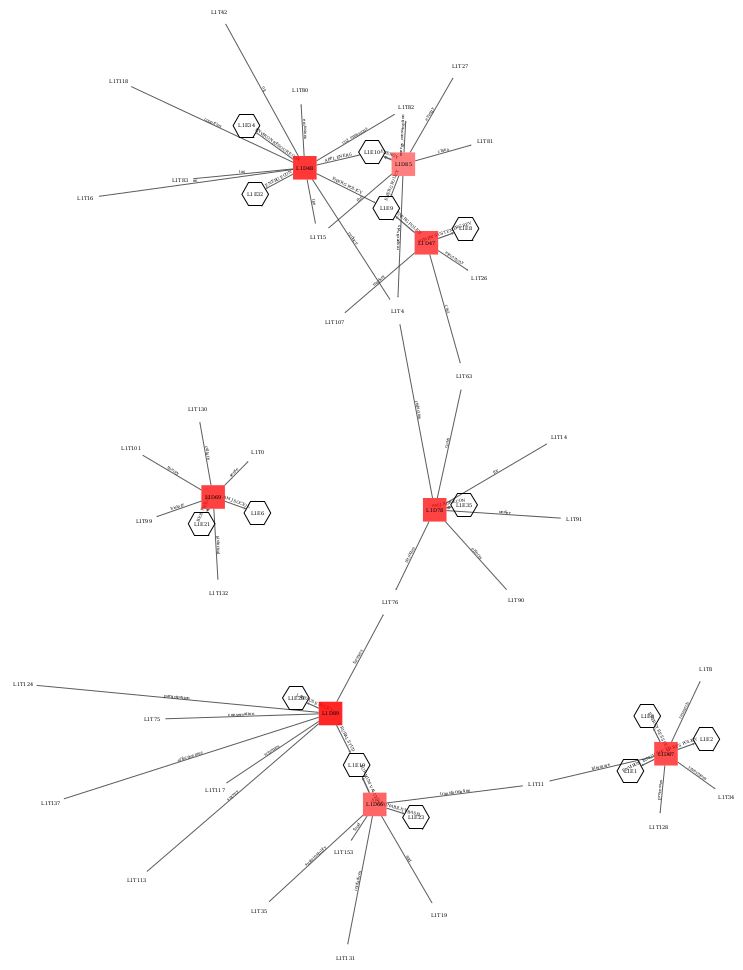
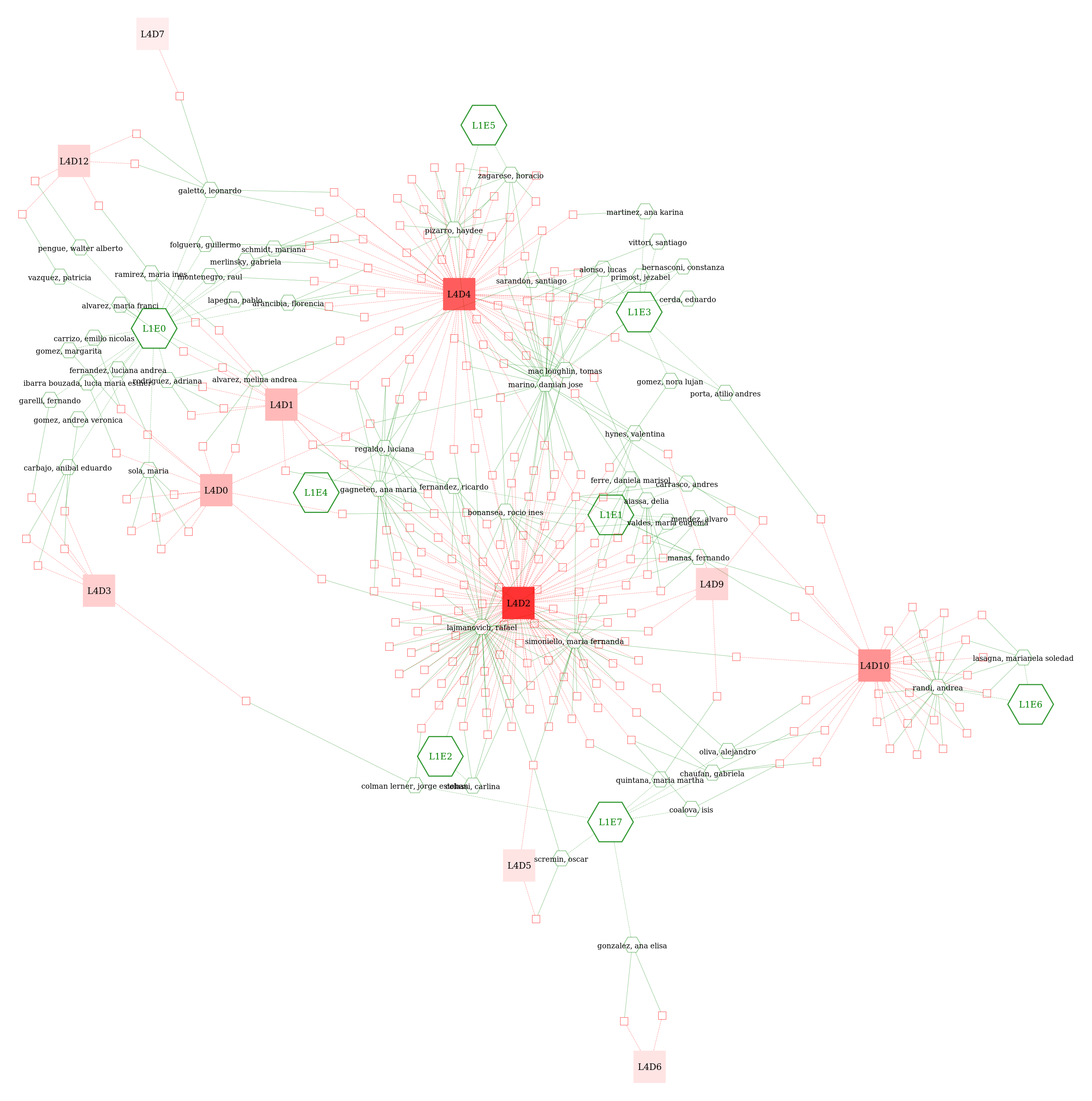
- Domain networks
- To visualize relations between domains, topics and clusters of other dimensions.
- Area rank charts
- Beautiful "bump charts" displaying the evolution of domains.
Eat in: "no code" usage
Much of the functionality of sashimi is available as a suite of methods in the Cortext
Manager web service. See their documentation for
SASHIMI, which may also serve users of the Python module as an introduction to the methodology.
Installation
You must first sharpen your knife install graph-tool by following the installation instructions according to your system.
Then:
pip install sashimi-domains
Dependencies
With the exception of graph-tool, dependencies will be automatically installed by pip.
This project builds mainly on the following others:
- graph-tool (for stochastic block model inference)
- pandas (for tabular data manipulation)
- spacy (for tokenization)
- gensim (for n-gram detection)
- bokeh (for building interactive maps and plots)
- lxml (for building HTML documents)
Basic usage
from sashimi import GraphModels
import pandas as pd
corpus = GraphModels(storage_dir="my_project")
df = pd.read_csv("example_corpus.csv")
corpus.load_data(df, name='example')
print(corpus.data)
corpus.store_data()
Preparing the data
Textual data
For the typical usage with a textual corpus:
corpus.text_sources = ["title", "body"]
text_sources_args = dict(ngrams=3, language="en", stop_words=True)
The language is any valid language for spacy, where None will use the English tokenizer with no stop_words. Our English tokenizer is slightly improved from spacy's original, in order to get ["hot-dog"] out of "hot-dog" (when spacy would split that), ["this", "that"] out of "this/that", and ["citation"] out of "citation[2,3]".
Token data
You may also directly use tokens that you have processed yourself, or from token data such as keywords, categories, or anything really, in addition or in place of textual data.
corpus.token_sources = ["keyword", "category"]
Token data for a document is expected to be in the form of a list, containing strings or lists containing strings: List[str | List[str]]. If your data differs, you must adjust it before processing.
Processing the data
Once token and text sources are set up, you can process them all with:
corpus.process_sources(**text_sources_args)
Working with your corpus
corpus.col_title = "titles"
corpus.col_time = "years"
corpus.col_urls = "urls"
corpus.load_domain_topic_model()
print(corpus.state)
print(corpus.dblocks)
print(corpus.tblocks)
corpus.domain_map()
corpus.domain_network(doc_level=1, ter_level=1)
corpus.domain_network(doc_level=2, ter_level=1)
corpus.domain_network(doc_level=2, ter_level=1, edges="specific")
corpus.domain_network(doc_level=2, ter_level=1, edges="common")
if 3 in corpus.dblocks:
corpus.subxblocks_tables(xbtype="doc", xlevel=3, xb=None, ybtype="ter")
corpus.register_config("my_config.json")
from sashimi import GraphModels
corpus = GraphModels('my_config.json')
corpus.load_domain_topic_model()
corpus.load_domain_topic_model(load=False)
print(corpus.list_blockstates())
corpus.set_chain(prop='metadata_A'}
corpus.load_domain_chained_model()
print(corpus.list_chainedbstates())
corpus.domain_map(chained=True)
corpus.domain_network(doc_level=1, ter_level=None, ext_level=1)
corpus.domain_network(doc_level=1, ter_level=1, ext_level=1)
corpus.domain_network(doc_level=2, ter_level=None, ext_level=1, edges="specific")
corpus.domain_network(doc_level=2, ter_level=1, ext_level=1, edges="common")
if 3 in corpus.dblocks:
corpus.subxblocks_tables(xbtype="doc", xlevel=3, xb=None, ybtype="ext")
Advanced usage
-
Help: the domain map document provides a "Help" tab explaining how to navigate and read it, which is also useful to understand the other interfaces.
-
Filters: Create filtered visualizations to show only a selected group of domains in maps and networks, with Corpus.set_sample() or with the xb_selection parameter to domain_network().
-
Filtered chaining: With Corpus.set_sample(), perform selective chaining, whereby a domain-chained model is fit by considering only a selected group of domains, instead of the entire corpus, in order to understand the local associations of metadata dimensions.
-
Complex chaining: Calls to Corpus.set_chain() may pass in the matcher parameter a path to a .json file containing a dictionary. Nodes of the chained dimension will then correspond to the keys in the dictionary, and links will be established by searching for a key's value, as a regular expression, in the column passed as the first parameter.
-
Better network map: An entirely new network map function with many improvements and new features is under development and can be tried from from sashimi.blocks.better_network_map import network_map. It will eventually replace the current network map.
Development
This module provides four main classes:
class Corpus
Methods to load and preprocess corpora, plus some descriptive statistics.
class GraphModels (user-facing class, inherits Corpus and Blocks)
Methods to fit Stochastic Block Models to corpora through either document-term or document-metadata graphs, yielding domain-topic and domain-chained models, respectively.
class Blocks
Methods to build interactive domain maps, networks, tables, and other interfaces.
class VectorModels [currently deprecated]
Methods to fit word embedding models to corpora and produce reports, statistics and visualizations.



