Product
Introducing Webhook Events for Pull Request Scans
Add real-time Socket webhook events to your workflows to automatically receive pull request scan results and security alerts in real time.
By Jeppe Hasseriis - Oct 22, 2025
sib-clustering
Advanced tools
![]()
This project provides an efficient implementation of the text clustering algorithm "sequential Information Bottleneck" (sIB), introduced by Slonim, Friedman and Tishby (2002). The project is packaged as a python library with a cython-wrapped C++ extension for the partition optimization code. A pure python implementation is included as well. The implementation is documented here.
pip install sib-clustering
The main class in this library is SIB, which implements the clustering interface of SciKit Learn, providing methods such as fit(), fit_transform(), fit_predict(), etc.
The sample code below clusters the 18.8K documents of the 20-News-Groups dataset into 20 clusters:
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.datasets import fetch_20newsgroups
from sklearn import metrics
from sib import SIB
# read the dataset
dataset = fetch_20newsgroups(subset='all', categories=None,
shuffle=True, random_state=256)
gold_labels = dataset.target
n_clusters = np.unique(gold_labels).shape[0]
# create count vectors using the 10K most frequent words
vectorizer = CountVectorizer(max_features=10000)
X = vectorizer.fit_transform(dataset.data)
# SIB initialization and clustering; parameters:
# perform 10 random initializations (n_init=10); the best one is returned.
# up to 15 optimization iterations in each initialization (max_iter=15)
# use all cores in the running machine for parallel execution (n_jobs=-1)
sib = SIB(n_clusters=n_clusters, random_state=128, n_init=10,
n_jobs=-1, max_iter=15, verbose=True)
sib.fit(X)
# report standard clustering metrics
print("Homogeneity: %0.3f" % metrics.homogeneity_score(gold_labels, sib.labels_))
print("Completeness: %0.3f" % metrics.completeness_score(gold_labels, sib.labels_))
print("V-measure: %0.3f" % metrics.v_measure_score(gold_labels, sib.labels_))
print("Adjusted Rand-Index: %.3f" % metrics.adjusted_rand_score(gold_labels, sib.labels_))
Expected result:
sIB information stats on best partition:
I(T;Y) = 0.5685, H(T) = 4.1987
I(T;Y)/I(X;Y) = 0.1468
H(T)/H(X) = 0.2956
Homogeneity: 0.616
Completeness: 0.633
V-measure: 0.624
Adjusted Rand-Index: 0.507
See the Examples directory for more illustrations and a comparison against K-Means.
Copyright IBM Corporation 2020
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
If you would like to see the detailed LICENSE click here.
Algorithm and pseudo-code: Slonim, Friedman and Tishby (2002)
First python implementation: Daniel Hershcovich
Optimization work: Assaf Toledo and Elad Venezian
Development and maintenance: Assaf Toledo
If you have any questions or issues you can create a new issue here.
N. Slonim, N. Friedman, and N. Tishby (2002). Unsupervised Document Classification using Sequential Information Maximization. SIGIR 2002. https://dl.acm.org/doi/abs/10.1145/564376.564401
FAQs
sequential Information Bottleneck
We found that sib-clustering demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Add real-time Socket webhook events to your workflows to automatically receive pull request scan results and security alerts in real time.

Research
The Socket Threat Research Team uncovered malicious NuGet packages typosquatting the popular Nethereum project to steal wallet keys.
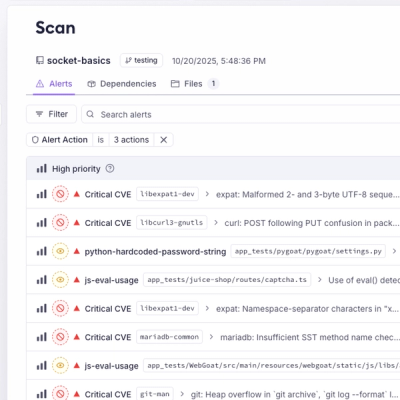
Product
A single platform for static analysis, secrets detection, container scanning, and CVE checks—built on trusted open source tools, ready to run out of the box.