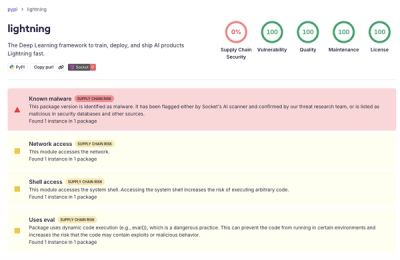
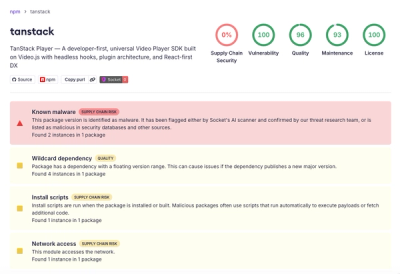
Text Generation
The Hugging Face Text Generation Python library provides a convenient way of interfacing with a
text-generation-inference instance running on
Hugging Face Inference Endpoints or on the Hugging Face Hub.
Get Started
Install
pip install text-generation
Inference API Usage
from text_generation import InferenceAPIClient
client = InferenceAPIClient("bigscience/bloomz")
text = client.generate("Why is the sky blue?").generated_text
print(text)
text = ""
for response in client.generate_stream("Why is the sky blue?"):
if not response.token.special:
text += response.token.text
print(text)
or with the asynchronous client:
from text_generation import InferenceAPIAsyncClient
client = InferenceAPIAsyncClient("bigscience/bloomz")
response = await client.generate("Why is the sky blue?")
print(response.generated_text)
text = ""
async for response in client.generate_stream("Why is the sky blue?"):
if not response.token.special:
text += response.token.text
print(text)
Check all currently deployed models on the Huggingface Inference API with Text Generation support:
from text_generation.inference_api import deployed_models
print(deployed_models())
Hugging Face Inference Endpoint usage
from text_generation import Client
endpoint_url = "https://YOUR_ENDPOINT.endpoints.huggingface.cloud"
client = Client(endpoint_url)
text = client.generate("Why is the sky blue?").generated_text
print(text)
text = ""
for response in client.generate_stream("Why is the sky blue?"):
if not response.token.special:
text += response.token.text
print(text)
or with the asynchronous client:
from text_generation import AsyncClient
endpoint_url = "https://YOUR_ENDPOINT.endpoints.huggingface.cloud"
client = AsyncClient(endpoint_url)
response = await client.generate("Why is the sky blue?")
print(response.generated_text)
text = ""
async for response in client.generate_stream("Why is the sky blue?"):
if not response.token.special:
text += response.token.text
print(text)
Types
class GrammarType(Enum):
Json = "json"
Regex = "regex"
class Grammar:
type: GrammarType
value: Union[str, dict]
class Parameters:
do_sample: bool
max_new_tokens: int
repetition_penalty: Optional[float]
frequency_penalty: Optional[float]
return_full_text: bool
stop: List[str]
seed: Optional[int]
temperature: Optional[float]
top_k: Optional[int]
top_p: Optional[float]
truncate: Optional[int]
typical_p: Optional[float]
best_of: Optional[int]
watermark: bool
details: bool
decoder_input_details: bool
top_n_tokens: Optional[int]
grammar: Optional[Grammar]
class Request:
inputs: str
parameters: Optional[Parameters]
stream: bool
class InputToken:
id: int
text: str
logprob: Optional[float]
class Token:
id: int
text: str
logprob: Optional[float]
special: bool
class FinishReason(Enum):
Length = "length"
EndOfSequenceToken = "eos_token"
StopSequence = "stop_sequence"
class BestOfSequence:
generated_text: str
finish_reason: FinishReason
generated_tokens: int
seed: Optional[int]
prefill: List[InputToken]
tokens: List[Token]
top_tokens: Optional[List[List[Token]]]
class Details:
finish_reason: FinishReason
generated_tokens: int
seed: Optional[int]
prefill: List[InputToken]
tokens: List[Token]
top_tokens: Optional[List[List[Token]]]
best_of_sequences: Optional[List[BestOfSequence]]
class Response:
generated_text: str
details: Details
class StreamDetails:
finish_reason: FinishReason
generated_tokens: int
seed: Optional[int]
class StreamResponse:
token: Token
top_tokens: Optional[List[Token]]
generated_text: Optional[str]
details: Optional[StreamDetails]
class DeployedModel:
model_id: str
sha: str