Product
Introducing Webhook Events for Pull Request Scans
Add real-time Socket webhook events to your workflows to automatically receive pull request scan results and security alerts in real time.
By Jeppe Hasseriis - Oct 22, 2025
This is a version of UniDic packaged for use with pip.
Currently it supports 2.3.0, the latest version of UniDic. Note this will take up 1GB on disk after install. If you want a small package, try unidic-lite.
The data for this dictionary is hosted as part of the AWS Open Data Sponsorship Program. You can read the announcement here.
After installing via pip, you need to download the dictionary using the following command:
python -m unidic download
With fugashi or mecab-python3 unidic will be used automatically when installed, though if you want you can manually pass the MeCab arguments:
import fugashi
import unidic
tagger = fugashi.Tagger('-d "{}"'.format(unidic.DICDIR))
# that's it!
This has a few changes from the official UniDic release to make it easier to use.
unk.def has been modified so unknown punctuation won't be marked as a nounSee the extras directory for details on how to replicate the build process.
Here is a list of fields included in this edition of UniDic. For more information see the UniDic FAQ, though not all fields are included. For fields in the UniDic FAQ the name given there is included.
Fields which are not applicable are usually marked with an asterisk (*).
五段-ラ行.連用形-促音便.kana field, not pron.pron for the lemma or orthBase.B1S6SjShS,B1S6S8SjShS.pron.pronBase.lemma field, so many CSV lines can share this value.The modern Japanese UniDic is available under the GPL, LGPL, or BSD license, see here. UniDic is developed by NINJAL, the National Institute for Japanese Language and Linguistics. UniDic is copyrighted by the UniDic Consortium and is distributed here under the terms of the BSD License.
The code in this repository is not written or maintained by NINJAL. The code is available under the MIT or WTFPL License, as you prefer.
FAQs
UniDic packaged for Python
We found that unidic demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Add real-time Socket webhook events to your workflows to automatically receive pull request scan results and security alerts in real time.

Research
The Socket Threat Research Team uncovered malicious NuGet packages typosquatting the popular Nethereum project to steal wallet keys.
Product
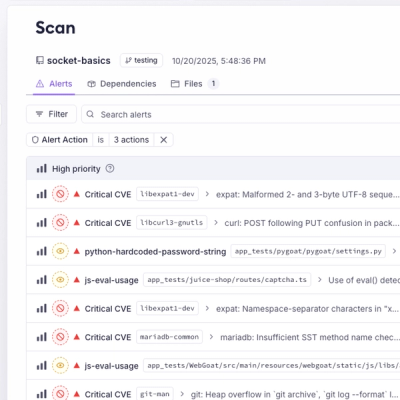
A single platform for static analysis, secrets detection, container scanning, and CVE checks—built on trusted open source tools, ready to run out of the box.