
Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
![]()
![]()
![]()
Since Python 3.0 map, filter & co (but more accurately even since Python 2 list comprehension), new versions of the language keep appending more and more functional elements, last in date being Generics, Union typing or Pattern Matching.
However although functional programming in its roughest form is possible in Python, it fails in our opinion to keep itself nice and readable.
# Look this awful little chunk of code, how cute it is <3
from functools import reduce
initial_value = ["oh", "look", "an", "array", "to", "process", "!"]
camel_cased = map(lambda chain: str(chain[0].upper()) + chain[1:], initial_value)
only_long_word = filter(lambda x: len(x) > 2, camel_cased)
output = reduce(lambda x, y: x + " " + y, only_long_word)
assert output == "Look Array Process"
This project aims to soften the functional syntax already existing within the language, and go even further by enabling more functional concepts.
Github repository: python-fp
While python provides today some tools from functional languages (such as map, filter, ...), it fails as making its syntax functional-friendly. For example, multiple mapping/filtering requires a lot of intermediate values with few addition to code readability or robustess. Moreover some paradigms are missing to fully benefits from monadic behavior (map/flat_map/filter/foreach/...).
The goal is to :
In order to achieve all of this, we propose a functional API adapted for python, taking into account its strengths and weaknesses to enrich the language without twisting it too much.
Please see the full documentation for more information.
xfp is plublished on PyPI HERE, easy to install with your package manager.
Some demos are provided in the demo folder. Each one is in a separate
subfolder.
For simplicity :
main.py filemain.py with relative importsTo run the demos (here the xlist one):
cd python-fp && pip install .)python -m demo.xiter.mainTo use XFP on a collection, starts with creating a new Xlist :
from xfp import Xlist, Xiter
xlist = Xlist([1, 2, 3])
# or xiter for the lazy iterator version. Functionalities differ a bit however
xiter = Xiter([1, 2, 3])
You can then start applying operations on the list, either through anonymous functions or defined ones.
The preconised style is to write one operation by line using the '()' operator :
from xfp import Xlist
def under_eight(x: int) -> bool:
return x < 8
(
Xlist([1, 2, 3])
.map(lambda x: x * x) # Xlist([1, 4, 9])
.filter(under_eight) # Xlist([1, 4])
.map(lambda x: f"this is a number : {x}") # Xlist(["this is a number : 1", "this is a number : 4"])
.foreach(print) # prints each element of the list, return None
)
Functional behaviors requires proper encapsulation of 'not a value' meaning (for example, None or raise Exception).
Those ecapsulations are modelised in xfp through the Xresult class. It basically encapsulates a union type under two pathways, either LEFT or RIGHT, in a container. Think of this container as a 'list with one element'. Its API is homogene with the collection one.
from xfp import Xresult, XRBranch
r1 = Xresult(1, XRBranch.RIGHT)
r2 = Xresult(3, XRBranch.LEFT)
(
r1
.map_right(lambda x: x + 3) # XRBranch.RIGHT : 4
.flat_map_right(lambda x: r2.map(lambda y: x + y)) # XRBranch.LEFT : 3
.filter_left(lambda x: x > 5) # XRBranch.RIGHT : XresultError(...)
)
You will often have to deal with multiple effects at once. To avoid the vanilla triangle of doom that would cause such dealing, xfp provides a convenient way to handle them altogether.
Let's illustrate it with a mock use case. A table computing and writing from three different sources :
from xfp import Xresult
def load_table(table_name: str) -> Xresult[Exception, DataFrame]:
pass
def write_table(table_name: str, table: DataFrame) -> Xresult[Exception, None]:
pass
def process(t1: DataFrame, t2: DataFrame, t3: DataFrame) -> DataFrame:
pass
# 'Vanilla' xfp processing
load_table('db1.tb1').flat_map(
lambda t1: load_table('db2.tb2').flat_map(
lambda t2:load_table('db3.tb3').flat_map(
lambda t3: write_table('db1.tb4', process(t1, t2, t3))
)
)
)
# Xfp result chaining
Xresult.fors(lambda:
[
write_table('db1.tb4', process(t1, t2, t3))
for t1, t2, t3
in zip(
load_table('db1.tb1'),
load_table('db2.tb2'),
load_table('db3.tb3')
)
])
In functional programming, the operation consisting in transforming the function f in g (see below) is called curryfiction :
fromp xfp import Xlist
def f(i: int, j: str) -> Xlist[str]:
pass
def g(i: int) -> Callable[[str], Xlist[str]]:
def inner(j: str) -> Xlist[str]:
pass
return inner
While the g syntax is often useful (for example to prepare functions to use in a map operation), the writing of such function may be tedious.
XFP comes with a convenient decorator curry to infer the g function from the f one:
from xfp import Xlist, curry
# the effective signature of f becomes def f(i: int) -> Callable[[str], Xlist[str]]
@curry
def f(i: int, j: str) -> Xlist[str]:
return i * j
# notice the usage of only one parameter in f
(
Xlist(["a", "b", "c"])
.flat_map(f(3))
.foreach(print)
)
You can add more semantic to your results by making use of the proxy types Xeither, Xtry, Xopt, respectively indicating "a formal union type", "something that can crash", "the presence or absence of an element".
Those types resolves as an Xresult, but can be used by themselves in pattern matching, and provide tooling revolving around their semantics. Example of Xtry :
from xfp import Xtry, Xresult
def should_raise(x):
if x > 10:
raise Exception("too much")
else:
return x
r1 = Xtry.from_unsafe(lambda: should_raise(15)) # Xtry.Failure(Exception("too much"))
r2 = Xtry.from_unsafe(lambda: should_raise(8)) # Xtry.Success(8)
# a decorator is provided to automatically convert your functions
@Xtry.safed
def safed_function(x):
return should_raise(x)
r3: Xresult[Exception, int] = safed_function(15) # Xtry.Failure(Exception("too much"))
r4: Xresult[Exception, int] = safed_function(8) # Xtry.Success(8)
# Constructors are also available
r5: Xresult[Exception, int] = Xtry.Success(3)
# You can pattern match an expression depending on its pathway
match r3:
case Xtry.Success(value):
print(value)
case Xtry.Failure(exception):
print(f"Something went wrong : {exception}")
uv sync --all-groupsuv run pre-commit install-> uv installs xfp package in editable mode, so that xfp is available as a package in the environment and editable.
Ruff is hooked on pre-commit as linter and formatter.
More here : https://github.com/astral-sh/ruff
More info : https://pre-commit.com/
unit-tests workflow is triggered on every push, regardless of the branch.
Protection rules:
Workflows:
Commits on the main branch triggers:
gh-pages workflow that builds and deploys documentationpypi-publish workflow that builds and publish package to pypi.org (trusted publisher)Protection rules:
git push -f origin <src_branch>:test)Workflows:
Commits on the test branch triggers:
pypi-publish workflow that builds and publish package to test.pypi.org (trusted publisher)FAQs
functional programming library for python
We found that xfp demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
Product
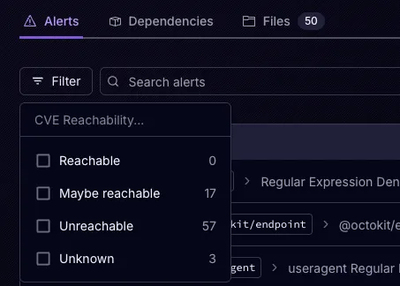
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.