Product
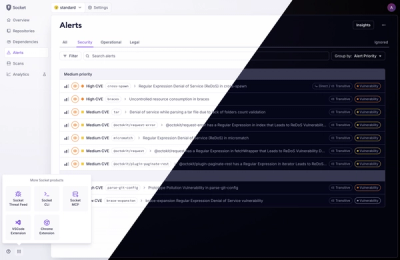
A Fresh Look for the Socket Dashboard
We’ve redesigned the Socket dashboard with simpler navigation, less visual clutter, and a cleaner UI that highlights what really matters.
By André Staltz, Jeppe Hasseriis, Nolan Lawson - Jun 23, 2025
ONNX-YOLO is a Python package for running inference on YOLO-WORLD open-vocabulary object detection models using ONNX runtime.
![]()
![]()
![]()

YOLO-World-ONNX is a Python package that enables running inference on YOLO-WORLD open-vocabulary object detection models using ONNX runtime. It provides a user-friendly interface for performing object detection on images or videos. The package leverages ONNX models to deliver fast inference time, making it suitable for a wide range of object detection applications.
You can install YOLO-World-ONNX using pip:
pip install yolo-world-onnx
Here's an example of how to perform inference using YOLO-World-ONNX:
import cv2 as cv
from yolo_world_onnx import YOLOWORLD
# Load the YOLO model
model_path = "path/to/your/model.onnx"
# Select a device 0 for GPU and for a CPU is cpu
model = YOLOWORLD(model_path, device="0")
# Set the class names
class_names = ["person", "car", "dog", "cat"]
model.set_classes(class_names)
# Retrieve the names
names = model.names
# Load an image
image = cv.imread("path/to/your/image.jpg")
# Perform object detection
boxes, scores, class_ids = model(image, conf=0.35, imgsz=640, iou=0.7)
# Process the results
for box, score, class_id in zip(boxes, scores, class_ids):
x, y, w, h = box
x1, y1 = int(x - w / 2), int(y - h / 2)
x2, y2 = int(x + w / 2), int(y + h / 2)
class_name = names[class_id]
print(f"Detected {class_name} with confidence {score:.2f} at coordinates (x1={x1}, y1={y1}, x2={x2}, y2={y2})")
The model function performs object detection on the input image and returns three values:
boxes: A list of bounding box coordinates for each detected object. Each box is represented as a tuple of four values (x, y, w, h), where:
x and y are the coordinates of the center of the bounding box.w and h are the width and height of the bounding box.scores: A list of confidence scores for each detected object. The confidence score represents the model's confidence in the detection, ranging from 0 to 1.
class_ids: A list of class indices for each detected object. The class index corresponds to the index of the class name in the names list.
The names list contains the class names that were set using the set_classes method. It is used to map the class indices to their corresponding class names.
In the example code, the results are processed by iterating over the boxes, scores, and class_ids lists simultaneously using zip. For each detected object:
(x, y, w, h) are extracted from the box tuple.(x1, y1) and (x2, y2), respectively.names list with the class_id.You can customize the processing of the results based on your specific requirements, such as drawing the bounding boxes on the image, filtering the detections based on confidence scores, or performing further analysis on the detected objects.
Here's an example of performing inference on an image and drawing the results:
import cv2 as cv
from yolo_world_onnx import YOLOWORLD
# Load the YOLO model
model_path = "path/to/your/model.onnx"
# Select a device 0 for GPU and for a CPU is cpu
model = YOLOWORLD(model_path, device="0")
# Set the class names
class_names = ["person", "car", "dog", "cat"]
model.set_classes(class_names)
# Retrieve the names
names = model.names
# Load an image
image = cv.imread("path/to/your/image.jpg")
# Perform object detection
boxes, scores, class_ids = model(image, conf=0.35, imgsz=640, iou=0.7)
# Draw bounding boxes on the image
for box, score, class_id in zip(boxes, scores, class_ids):
x, y, w, h = box
x1, y1 = int(x - w / 2), int(y - h / 2)
x2, y2 = int(x + w / 2), int(y + h / 2)
cv.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
class_name = names[class_id]
cv.putText(image, f"{class_name}: {score:.2f}", (x1, y1 - 10), cv.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# Display the image
cv.imshow("Object Detection", image)
cv.waitKey(0)
cv.destroyAllWindows()
Here's an example of performing inference on a video and drawing the results:
import cv2 as cv
from yolo_world_onnx import YOLOWORLD
# Load the YOLO model
model_path = "path/to/your/model.onnx"
# Select a device 0 for GPU and for a CPU is cpu
model = YOLOWORLD(model_path, device="0")
# Set the class names
class_names = ["person", "car", "dog", "cat"]
model.set_classes(class_names)
# Retrieve the names
names = model.names
# Open a video file or capture from a camera
video_path = "path/to/your/video.mp4"
cap = cv.VideoCapture(video_path)
while True:
# Read a frame from the video
ret, frame = cap.read()
if not ret:
break
# Perform object detection
boxes, scores, class_ids = model(frame, conf=0.35, imgsz=640, iou=0.7)
# Draw bounding boxes on the frame
for box, score, class_id in zip(boxes, scores, class_ids):
x, y, w, h = box
x1, y1 = int(x - w / 2), int(y - h / 2)
x2, y2 = int(x + w / 2), int(y + h / 2)
cv.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
class_name = names[class_id]
cv.putText(frame, f"{class_name}: {score:.2f}", (x1, y1 - 10), cv.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# Display the frame
cv.imshow("Object Detection", frame)
if cv.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv.destroyAllWindows()
| Model Type | mAP | mAP50 | mAP75 | Image Size | Model |
|---|---|---|---|---|---|
| yolov8s-worldv2 | 37.7 | 52.2 | 41.0 | 640 | Download |
| yolov8m-worldv2 | 43.0 | 58.4 | 46.8 | 640 | Download |
| yolov8l-worldv2 | 45.8 | 61.3 | 49.8 | 640 | Download |
| yolov8x-worldv2 | 47.1 | 62.8 | 51.4 | 640 | Download |
YOLO-World-ONNX supports custom ONNX models that are exported in the same format as the models provided in this repository. The code is designed to work dynamically with models of any number of classes. Even if the model is exported on 100 classes and the user specifies only 3 classes to be detected in the run, YOLO-World-ONNX will detect those 3 classes accordingly.
If you want to use a custom model with a different resolution or detect more classes, you can follow the guide on exporting custom models in the ONNX-YOLO-World-Open-Vocabulary-Object-Detection repository.
The original source code for this package is based on the work by Ibai Gorordo in the ONNX-YOLO-World-Open-Vocabulary-Object-Detection repository.
Image reference is Here
This project is licensed under the MIT License. See the LICENSE file for more information.
FAQs
ONNX-YOLO is a Python package for running inference on YOLO-WORLD open-vocabulary object detection models using ONNX runtime.
We found that yolo-world-onnx demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
We’ve redesigned the Socket dashboard with simpler navigation, less visual clutter, and a cleaner UI that highlights what really matters.

Industry Insights
Terry O’Daniel, Head of Security at Amplitude, shares insights on building high-impact security teams, aligning with engineering, and why AI gives defenders a fighting chance.

Security News
MCP spec updated with structured tool output, stronger OAuth 2.1 security, resource indicators, and protocol cleanups for safer, more reliable AI workflows.