Product
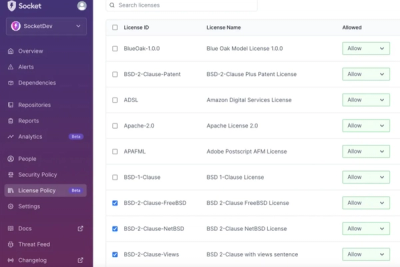
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
LaukvikCSV is a powerful API for reading, writing and querying tabular data stored in the CSV format. In contrast to other API it lets you specify data types for each column using meta data. It automatically detects delimiters so you don't have to worry about delimiters being comma, tab, pipe, semicolon etc. Run powerful queries to filter your data easily with a fluid query language thats type safe. Export your tabular data to CSV, JSON, XML and HTML.
License: Apache 2.0
LaukvikCSV is a powerful API for reading, writing and querying tabular data stored in the CSV format. In contrast to other API it lets you specify data types for each column using meta data. It automatically detects delimiters so you don't have to worry about delimiters being comma, tab, pipe, semicolon etc. Run powerful queries to filter your data easily with a fluid query language thats type safe. Export your tabular data to CSV, JSON, XML and HTML.
<dependency>
<groupId>no.laukvik</groupId>
<artifactId>csv</artifactId>
<version>0.9.6</version>
</dependency>
The easiest way to read a CSV file is to call the default constructor. This method will try to auto detect separator character and encoding.
CSV csv = new CSV( new File("presidents.csv") );
StringColumn president = csv.getColumn("president");
IntegerColumn presidency = csv.getColumn(5);
List<Row> rows = csv.findRows();
for (Row r : rows){
System.out.println( r.get(president) );
System.out.println( r.get(presidency) );
}
Use the appendFile method to combine multiple files.
CSV csv = new CSV(new File("presidents.csv"));
csv.appendFile(getResource("another.csv"));
Creates a new CSV with two presidents and saves it to addresses.csv
CSV csv = new CSV();
StringColumn first = csv.getStringColumn("first");
StringColumn last = csv.getStringColumn("last");
csv.addRow().set( first, "Barack" ).set( last, "Obama" );
csv.addRow().set( first, "Donald" ).set( last, "Trump" );
csv.writeFile( new File("addresses.csv") );
The output of the file addresses.csv will be:
first,last
"Barack","Obama"
"Donald","Trump"
Using the previous example will write to different formats
csv.writeHtml( new File("addresses.html") ); // Write to HTML format
csv.writeJSON( new File("addresses.json") ); // Write to JSON format
csv.writeXML( new File("addresses.xnk") ); // Write to XML format
Example: Displaying all presidents with presidency between 1 and 10
CSV csv = new CSV( new File("presidents.csv") );
StringColumn president = csv.getStringColumn("president");
IntegerColumn presidency = (IntegerColumn) csv.getColumn(5);
Query query = new Query();
query.isBetween(presidency, 1, 10);
List<Row> rows = csv.findRowsByQuery( query );
for (Row r : rows){
System.out.println( r.get(president) + ": " + r.get(presidency) );
}
Creating a CSV with two columns
CSV csv = new CSV();
csv.addStringColumn("President");
csv.addStringColumn("Party");
Reordering columns. The following example moves the column "Party" from index 1 to index 0
csv.moveColumn(1,0);
Removes the first column (President).
csv.removeColumn(0);
Adding a new row with data
CSV csv = new CSV();
StringColumn president = csv.addStringColumn("President");
StringColumn party = csv.addStringColumn("Party");
csv.addRow()
.set(president, "Barack Obama")
.set(party, "Democratic");
Moving a row up or down
csv.moveRow( 1, 2 );
Swapping two rows
csv.swapRows( 1, 2 );
Removing rows
csv.removeRow( 5 );
Removing rows between range
csv.removeRows( 5, 10 );
Finding the index
csv.indexOf( row );
Inserting row at a specific index
CSV csv = new CSV();
StringColumn president = csv.addStringColumn("President");
csv.addRow(0).setString(president, "Barak Obama");
Iterating all rows
CSV csv = new CSV( new File("presidents.csv") );
for (Row row : csv.findRows()){
}
Iterate rows using stream
CSV csv = new CSV( new File("presidents.csv") );
csv.stream();
Finds all rows where the presidency is between 1 and 10
Query query = new Query();
query.isBetween( presidency, 1, 10 ); // Find all rows with value 1 to 10
List<Row> rows = csv.findRowsByQuery( query ); // Returns two rows
Finds all rows above and sorts it descending order
Query query = new Query()
.isBetween( presidency, 1, 10 )
.descending( presidency );
List<Row> rows = csv.findByQuery(query);
A more complicated example that uses different filters
// Build an empty CSV with a few columns
CSV csv = new CSV();
StringColumn president = csv.addStringColumn("President");
StringColumn party = csv.addStringColumn("Party");
IntegerColumn presidency = csv.addIntegerColumn("Presidency");
UrlColumn web = csv.addUrlColumn("web");
DateColumn tookOffice = csv.addDateColumn("Took office", "dd/MM/yyyy");
// Add test values
csv.addRow()
.set( president, "Donald Trump")
.set( presidency, 45)
.set( party, null)
.set( tookOffice, tookOffice.parse("20/01/2017") )
.set( web, new URL("https://en.wikipedia.org/wiki/Donald_Trump"));
csv.addRow()
.set( president, "Barack Obama")
.set( presidency, 44)
.set( party, "Democratic")
.set( tookOffice, tookOffice.parse("20/01/2009") )
.set( web, new URL("http://en.wikipedia.org/wiki/Barack_Obama"));
csv.addRow()
.set( president, "George W. Bush")
.set( presidency, 43)
.set( party, "Republican")
.set( tookOffice, tookOffice.parse("20/01/2001") )
.set( web, new URL("http://en.wikipedia.org/wiki/George_W._Bush"));
csv.addRow()
.set( president, "Bill Clinton")
.set( presidency, 42)
.set( party, "Democratic")
.set( tookOffice, tookOffice.parse("20/01/1993") )
.set( web, new URL("http://en.wikipedia.org/wiki/Bill_Clinton"));
csv.addRow()
.set( president, "George H. W. Bush")
.set( presidency, 41)
.set( party, "Republican")
.set( tookOffice, tookOffice.parse("20/01/1989") )
.set( web, new URL("http://en.wikipedia.org/wiki/George_H._W._Bush"));
csv.addRow()
.set( president, "Ronald Reagan")
.set( presidency, 40)
.set( party, "Republican")
.set( tookOffice, tookOffice.parse("20/01/1981") )
.set( web, new URL("http://en.wikipedia.org/wiki/Ronald_Reagan"));
// Build the query
Query query = new Query()
.isBetween( presidency, 41, 45 )
.isDayOfMonth( tookOffice, 20)
.isWordCount( president, 2, 3, 4)
.isAfter( tookOffice, tookOffice.parse("01/01/1999") )
.isYear( tookOffice, 2009, 2017 )
.isEmpty(party)
.isNotEmpty(web)
.ascending( presidency );
List<Row> rows = csv.findRowsByQuery(query);
// Display the results
for (Row r : rows){
System.out.println( r.get(presidency) + ": " + r.get(president) );
}
Builds a frequency distribution for the president column
CSV csv = new CSV();
StringColumn president = csv.addStringColumn("president");
csv.addRow().set(president, "Barack Obama");
csv.addRow().set(president, "Barack Obama");
csv.addRow().set(president, "Donald Trump");
csv.addRow(); // Add row with no president
csv.addRow().set(president, null); // Add row with president is null
FrequencyDistribution<String> freq = csv.buildFrequencyDistribution(president);
for (String key : freq.getKeys()){
System.out.println(key + ": " + freq.getCount(key));
}
System.out.println("Nulls: " + freq.getNullCount());
The example about will output
Barack Obama: 2
Donald Trump: 1
Nulls: 2
Reusing the previous example will create a set of distinct values like this
Set<String> values = csv.buildDistinctValues( president );
The example about will output
Barack Obama
Donald Trump
FAQs
LaukvikCSV is a powerful API for reading, writing and querying tabular data stored in the CSV format. In contrast to other API it lets you specify data types for each column using meta data. It automatically detects delimiters so you don't have to worry about delimiters being comma, tab, pipe, semicolon etc. Run powerful queries to filter your data easily with a fluid query language thats type safe. Export your tabular data to CSV, JSON, XML and HTML.
We found that no.laukvik:csv demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
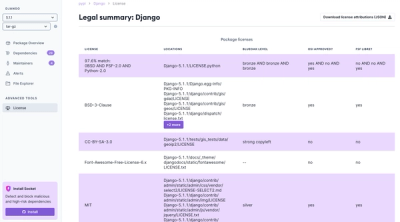
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
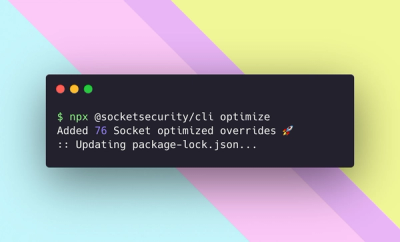
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.