
Security News
RubyGems Adds Cooldown Feature to Bundler for Newly Published Gems
RubyGems and Bundler 4.0.13 introduced an opt-in cooldown feature that delays newly published gems during dependency resolution.
By Sarah Gooding - Jun 05, 2026
@codexstar/pi-listen
Advanced tools
Voice in + voice out for Pi CLI — hold-to-talk STT (Deepgram or 19 offline models) plus TTS (Kitten Nano, Piper, Kokoro, or Deepgram Aura)
English | 简体中文 | 日本語 | 한국어 | Español | Français | Português | हिन्दी

Hold-to-talk voice input for Pi. Cloud streaming via Deepgram or fully offline with local models.


v7.0.0 — World-class TTS UX — pick models from
/voice-settingsSpeak tab (no more JSON editing), auto-download on selection with progress, voice picker for every backend, first-run onboarding with smart-default recommendation by your system locale, andttsAutoSpeak: truefinally works — auto-speaks the agent's responses with code-block stripping and rate limiting. Diagnostic command/voice-speak-infoshows everything. Resume-on-interrupt downloads. Plus all v6 features (14 local models from 25 MB Kitten Nano up, Deepgram Aura cloud, region-strict language matching, sentence-aware chunking). Full changelog →
Click to watch the demo video
# In a regular terminal (not inside Pi)
pi install npm:@codexstar/pi-listen
pi-listen supports two transcription backends:
| Deepgram (cloud) | Local models (offline) | |
|---|---|---|
| How it works | Live streaming — text appears as you speak | Batch mode — transcribes after you finish recording |
| Setup | API key required | No API key, models auto-download on first use |
| Internet | Required | Not required after model download |
| Latency | Real-time interim results | 2–10 seconds after recording stops |
| Languages | 56+ with live streaming | Depends on model (1–57 languages) |
| Cost | $200 free credit (lasts 6–12 months for most developers) | Free forever |
Run /voice-settings inside Pi to choose your backend and configure everything from one panel.
Sign up at dpgr.am/pi-voice — $200 free credit, no card needed.
export DEEPGRAM_API_KEY="your-key-here" # add to ~/.zshrc or ~/.bashrc
No setup needed — run /voice-settings, switch backend to Local, and select a model. It downloads automatically.
Note: Local models use batch mode — they transcribe after you finish recording, not while you speak. For live streaming as you speak, use Deepgram.
On first launch, pi-listen checks your setup and tells you what's ready:
pi-listen auto-detects your audio tool. No manual install needed if you already have sox or ffmpeg.
| Priority | Tool | Platforms | Install |
|---|---|---|---|
| 1 | SoX (rec) | macOS, Linux, Windows | brew install sox / apt install sox / choco install sox |
| 2 | ffmpeg | macOS, Linux, Windows | brew install ffmpeg / apt install ffmpeg |
| 3 | arecord | Linux only | Pre-installed (ALSA) |
All configuration lives in one place: /voice-settings. Four tabs cover everything you need.
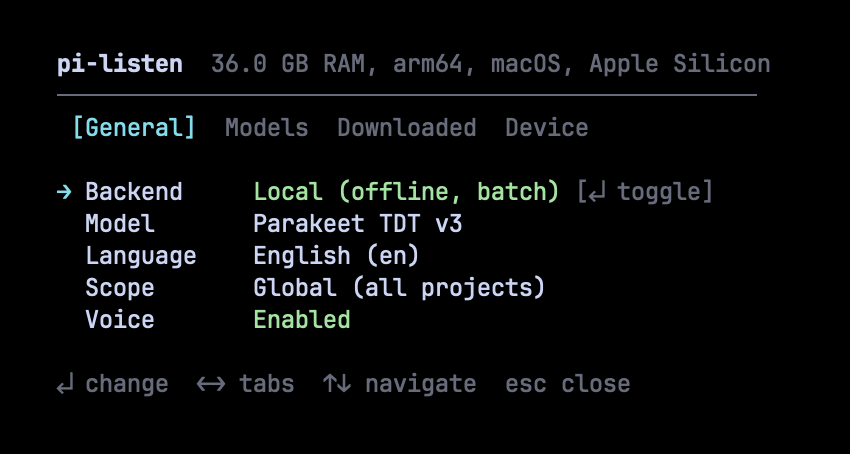
Toggle between Deepgram (cloud, live streaming) and Local (offline, batch mode). Change language, scope, and enable/disable voice — all with keyboard shortcuts.
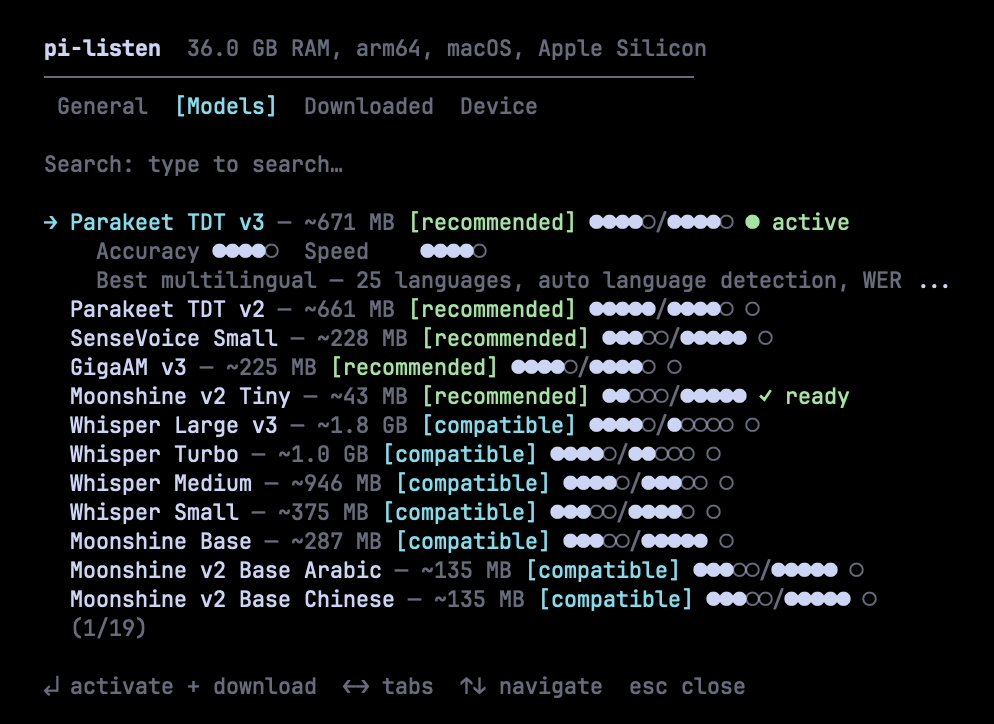
Browse 19 models from Parakeet, Whisper, Moonshine, SenseVoice, and GigaAM. Each model shows accuracy and speed ratings (●●●●○/●●●●○), fitness badges, and download status. Fuzzy search to find models fast. Press Enter to activate and download.
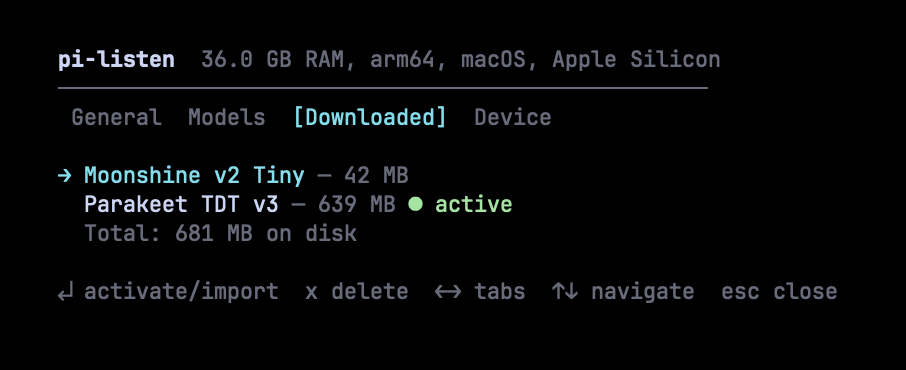
See what's installed, total disk usage, and which model is active. Press Enter to activate, x to delete. Models from Handy are auto-detected and can be imported without re-downloading.
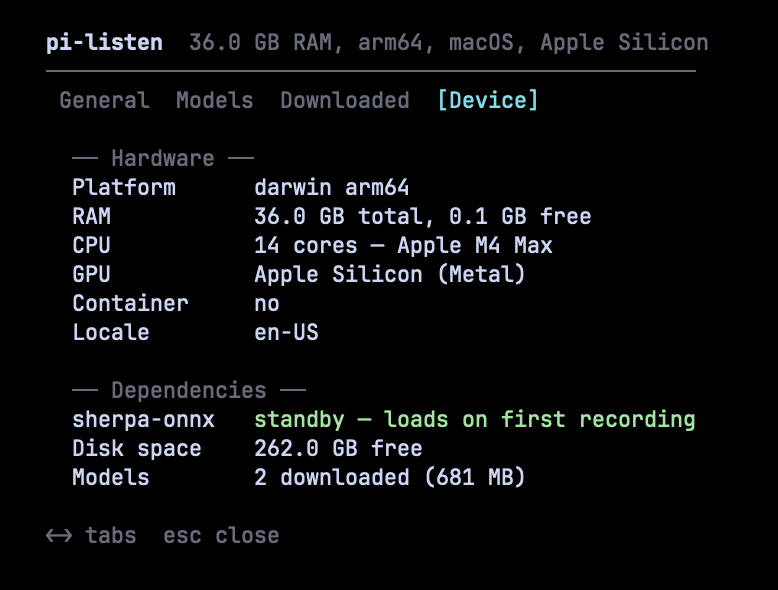
See your hardware profile (RAM, CPU, GPU), dependency status (sherpa-onnx runtime), available disk space, and total downloaded models. Model recommendations are based on this profile.
| Action | Key | Notes |
|---|---|---|
| Record to editor | Hold SPACE (≥1.2s) | Release to finalize. Pre-records during warmup so you don't miss words. |
| Toggle recording | Ctrl+Shift+V | Works in all terminals — press to start, press again to stop. |
| Clear editor | Escape × 2 | Double-tap within 500ms to clear all text. |
| Command | Description |
|---|---|
/voice-settings | Settings panel — backend, models, language, scope, device |
/voice-models | Settings panel (Models tab) |
/voice-speak <text> | Speak text out loud (TTS) |
/voice-speak-test | Speak a sample sentence |
/voice-speak-toggle | Enable / disable TTS |
/voice-autosubmit `[on | off]` |
/voice-speak-models | Browse / install TTS voice models |
/voice-speak-info | Diagnose TTS state |
/voice-help | Keyboard + command reference (or press F1) |
/voice test | Full diagnostics — audio tool, mic, API key |
/voice on / off | Enable or disable voice |
/voice dictate | Continuous dictation (no key hold) |
/voice stop | Stop active recording or dictation |
/voice history | Recent transcriptions |
/voice | Toggle on/off |
While in the settings panel:
| Key | Action |
|---|---|
← → | switch tab |
↑ ↓ | navigate row (skips group headings) |
↵ | select / activate |
esc | back to main / close panel |
type | filter (search) |
bksp | clear last search char |
While an install widget or playback indicator is mounted (no overlay in front):
| Key | Action |
|---|---|
esc | cancel active install (most-recent first), then stop playback |
F1 | open help overlay (always available) |
19 models across 5 families. Sorted by quality — best models first.
| Model | Accuracy | Speed | Size | Languages | Notes |
|---|---|---|---|---|---|
| Parakeet TDT v3 | ●●●●○ | ●●●●○ | 671 MB | 25 (auto-detect) | Best overall. WER 6.3%. |
| Parakeet TDT v2 | ●●●●● | ●●●●○ | 661 MB | English | Best English. WER 6.0%. |
| Whisper Turbo | ●●●●○ | ●●○○○ | 1.0 GB | 57 | Broadest language support. |
| Model | Accuracy | Speed | Size | Languages | Notes |
|---|---|---|---|---|---|
| Moonshine v2 Tiny | ●●○○○ | ●●●●● | 43 MB | English | 34ms latency. Raspberry Pi friendly. |
| Moonshine Base | ●●●○○ | ●●●●● | 287 MB | English | Handles accents well. |
| SenseVoice Small | ●●●○○ | ●●●●● | 228 MB | zh/en/ja/ko/yue | Best for CJK languages. |
| Model | Accuracy | Speed | Size | Languages | Notes |
|---|---|---|---|---|---|
| GigaAM v3 | ●●●●○ | ●●●●○ | 225 MB | Russian | 50% lower WER than Whisper on Russian. |
| Whisper Medium | ●●●●○ | ●●●○○ | 946 MB | 57 | Good accuracy, medium speed. |
| Whisper Large v3 | ●●●●○ | ●○○○○ | 1.8 GB | 57 | Highest Whisper accuracy. Slow on CPU. |
Plus 8 language-specialized Moonshine v2 variants for Japanese, Korean, Arabic, Chinese, Ukrainian, Vietnamese, and Spanish.
Hold SPACE → audio captured to memory buffer
↓
Release SPACE → buffer sent to sherpa-onnx (in-process)
↓
ONNX inference on CPU (2–10 seconds)
↓
Final transcript inserted into editor
Models download automatically on first use. Downloads are resumable, verified after completion, and deduplicated (no double-downloads). The settings panel shows real-time download progress with speed and ETA.
Models from Handy (~/Library/Application Support/com.pais.handy/models/) are auto-detected and can be imported via symlink (zero disk duplication).
| Feature | Description |
|---|---|
| Dual backend | Deepgram (cloud, live streaming) or local models (offline, batch) — switch in settings |
| 19 local models | Parakeet, Whisper, Moonshine, SenseVoice, GigaAM — with accuracy/speed ratings |
| Unified settings panel | One overlay panel for all configuration — /voice-settings |
| Device-aware recommendations | Scores models against your hardware. Only best-in-class models get [recommended]. |
| Enterprise download pipeline | Pre-checks (disk, network, permissions), live progress with speed/ETA, post-verification |
| Handy integration | Auto-detects models from Handy app, imports via symlink |
| Audio fallback chain | Tries sox, ffmpeg, arecord in order |
| Pre-recording | Audio capture starts during warmup — you never miss the first word |
| Tail recording | Keeps recording 1.5s after release so your last word isn't clipped |
| Live streaming | Deepgram Nova 3 WebSocket — interim transcripts as you speak |
| 56+ languages | Deepgram: 56+ with live streaming. Local: up to 57 depending on model. |
| Continuous dictation | /voice dictate for long-form input without holding keys |
| Typing cooldown | Space holds within 400ms of typing are ignored |
| Sound feedback | macOS system sounds for start, stop, and error events |
| Cross-platform | macOS, Windows, Linux — Kitty protocol + non-Kitty fallback |
extensions/voice.ts Main extension — state machine, recording, UI, settings panel
extensions/voice/config.ts Config loading, saving, migration
extensions/voice/onboarding.ts First-run wizard, language picker
extensions/voice/deepgram.ts Deepgram URL builder, API key resolver
extensions/voice/local.ts Model catalog (19 models), in-process transcription
extensions/voice/device.ts Device profiling — RAM, GPU, CPU, container detection
extensions/voice/model-download.ts Download manager — resume, progress, verification, Handy import
extensions/voice/sherpa-engine.ts sherpa-onnx bindings — recognizer lifecycle, inference
extensions/voice/settings-panel.ts Settings panel — Component interface, overlay, 4 tabs
Settings stored in Pi's settings files under the voice key:
| Scope | Path |
|---|---|
| Global | ~/.pi/agent/settings.json |
| Project | <project>/.pi/settings.json |
{
"voice": {
"version": 2,
"enabled": true,
"language": "en",
"backend": "local",
"localModel": "parakeet-v3",
"scope": "global",
"onboarding": { "completed": true, "schemaVersion": 2 }
}
}
DEEPGRAM_API_KEY from your shell is used at runtime and is not copied back
into ~/.pi/agent/settings.json. If you paste a key during onboarding, that is
an explicit save and it still goes to ~/.env.secrets or ~/.zshrc.
Run /voice test inside Pi for full diagnostics.
| Problem | Solution |
|---|---|
| "DEEPGRAM_API_KEY not set" | Get a key → export DEEPGRAM_API_KEY="..." in ~/.zshrc |
| "No audio capture tool found" | brew install sox or brew install ffmpeg |
| Space doesn't activate voice | Run /voice-settings — voice may be disabled |
| Local model not transcribing | Check /voice-settings → Device tab for sherpa-onnx status |
| Download failed | Partial downloads auto-resume on retry. Check disk space in Device tab. |
dyld: Library not loaded: libsimdjson on macOS | Homebrew Node ABI mismatch — run brew reinstall node or switch to version-managed Node (mise, fnm, nvm) |
See SECURITY.md for vulnerability reporting.
MIT © 2026 @baanditeagle
Made by @baanditeagle
Website · 𝕏 Twitter · GitHub · npm · Report a Bug · Pi CLI
FAQs
Voice in + voice out for Pi CLI — hold-to-talk STT (Deepgram or 19 offline models) plus TTS (Kitten Nano, Piper, Kokoro, or Deepgram Aura)
We found that @codexstar/pi-listen demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
RubyGems and Bundler 4.0.13 introduced an opt-in cooldown feature that delays newly published gems during dependency resolution.

Security News
pnpm 11.5 now recognizes npm staged publish approvals in release metadata, preventing those releases from being mistaken for lower-trust package publishes.

Security News
Federal audit finds NIST lacked a plan to clear the NVD backlog, wasted funds on duplicate work, and delayed use of CISA data.