Research
/Security News
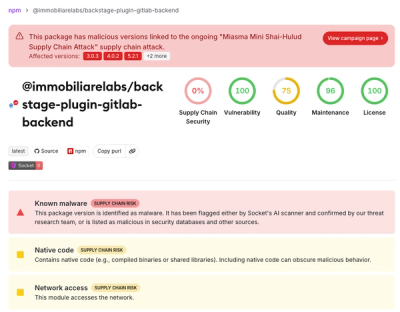
Miasma Mini Shai-Hulud Hits ImmobiliareLabs npm Packages
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.
By Socket Research Team - Jun 26, 2026
@qvac/classification-ggml
Advanced tools
GGML image classification addon for QVAC (MobileNetV3-Small CPU inference)
GGML-powered image classification addon for QVAC. Runs a fine-tuned MobileNetV3-Small 3-class triage CNN on the CPU backend of libggml and exposes a small, stable JavaScript API. Now intended for a specific image triage, but can be easily adapted for other classification tasks.
| Property | Value |
|---|---|
| Model | MobileNetV3-Small (3 classes) |
| Parameters | ~2.5 M |
| Weights | FP16 GGUF, 2.94 MB, bundled in this package |
| Input | JPEG, PNG, or raw RGB bytes |
| Resize target | 224 × 224 (bilinear) |
| Normalization | ImageNet mean/std |
| Backend | libggml CPU (no GPU dependency) |
Package name: @qvac/classification-ggml
Directory: packages/classification-ggml
This addon is published to the @qvac scope and consumed like any other QVAC native addon. When used from the monorepo, npm install resolves @qvac/infer-base and @qvac/logging via the workspace.
const ImageClassifier = require('@qvac/classification-ggml')
const classifier = new ImageClassifier()
await classifier.load()
const imageBuffer = fs.readFileSync('./my-image.jpg')
const result = await classifier.classify(imageBuffer)
// [ { label: 'food', confidence: 0.93 },
// { label: 'other', confidence: 0.05 },
// { label: 'report', confidence: 0.02 } ]
await classifier.unload()
const result = await classifier.classify(rgbBuffer, {
width: 320,
height: 240,
channels: 3,
})
By default classify() returns one entry per class, sorted from most likely to least likely. Pass topK: N to keep only the top N results — for example topK: 1 returns just the single highest-scoring class:
const best = await classifier.classify(buf, { topK: 1 })
| Method | Description |
|---|---|
new ImageClassifier(opts?) | opts = { modelPath?, logger?, nativeLogger? } |
await load() | Initialises the GGML backend and loads weights. Idempotent. |
await classify(buffer, options?) | Runs inference. Returns [{ label, confidence }, …] sorted descending. |
await unload() | Releases native resources. Safe to call again. |
await destroy() | Releases resources and marks the instance as destroyed. |
getState() | Returns { configLoaded, destroyed }. |
See index.d.ts for the full TypeScript surface.
new ImageClassifier(opts?)All constructor options are optional.
| Option | Type | Default | Description |
|---|---|---|---|
modelPath | string | Bundled weights/mobilenetv3_3class_v3_fp16.gguf | Absolute path to an FP16 GGUF file. Override only when pointing at a custom fine-tune produced by the ONNX→GGUF conversion guide. Also overridable via the QVAC_CLASSIFICATION_MODEL_PATH env variable. |
logger | QvacLogger-shaped | null | A sink with optional error / warn / info / debug(msg) methods (compatible with @qvac/logging). Receives JS-side info from a successful load() and error from a failed load(). With nativeLogger: true, also receives forwarded native LogMsg events at info level. Always honoured, regardless of nativeLogger. |
nativeLogger | boolean | false | When true, native C++ QLOG(...) lines from inside the addon's model-loading and graph code are forwarded to logger. Disabled by default because the underlying qvac-lib-inference-addon-cpp logger is a process-wide singleton with a static uv_async_t that is not safe across rapid create/destroy cycles (e.g. in tests). |
await classify(imageInput, options?)| Parameter | Type | Default | Description |
|---|---|---|---|
imageInput (required) | Buffer | Uint8Array | — |
options.topK | number | undefined (all classes) | If set, the returned array is truncated to this many entries (top-K highest confidences). Must be a positive integer. Passing a value ≥ class count is a no-op. |
options.width | number | — | Required for raw RGB input. Integer > 0. The underlying buffer must be exactly width × height × channels bytes; any mismatch throws a structured error. |
options.height | number | — | Required for raw RGB input. Integer > 0. |
options.channels | 3 | — | Required for raw RGB input. Must be exactly 3. Grayscale and RGBA are not supported — decode or drop the alpha channel on the caller side. |
Returns Promise<ClassificationResult[]> where each entry is { label: string; confidence: number }. The array is sorted by confidence descending, confidences are softmax probabilities in [0, 1] summing to ≈ 1, and label comes from the loaded GGUF's mobilenet.class_N metadata (so a future fine-tune can introduce new label strings without a code change).
await load() / await unload() / await destroy()None take arguments. load() is idempotent — calling it twice is a no-op (check getState().configLoaded if you want to verify). unload() safely tears down the native handle and may be called multiple times. destroy() is equivalent to unload() plus a sticky destroyed flag in getState() — useful if your code wants to refuse reuse of a released instance.
{ label: string, confidence: number }.confidence descending.confidence values are softmax probabilities in [0, 1] and sum to ≈ 1.mobilenet.class_0/1/2). For the bundled weights these are food, report, other.Prerequisites: clang (LLVM ≥ 19) with matching libc++-dev, vcpkg, bare ≥ 1.24, bare-make. CI pins the exact LLVM major via the shared setup-llvm action; locally any recent clang works.
cd packages/classification-ggml
npm install
bare-make generate
bare-make build
bare-make install
One-liner: npm install && bare-make generate && bare-make build && bare-make install.
npm run test:integration # brittle + bare JS integration tests (desktop)
npm run test:cpp # GoogleTest C++ unit tests
npm run test:mobile:generate # regenerate test/mobile/integration.auto.cjs
npm run test:mobile:validate # verify mobile test file structure
Integration tests live in test/integration/*.test.js and use the 6 sample images under test/images/ (two images per class).
Mobile tests use the shared qvac-test-addon-mobile framework. The test/mobile/integration.auto.cjs file is auto-generated by scripts/generate-mobile-integration-tests.js from every *.test.js under test/integration/, so adding a new integration test automatically exposes it on mobile too.
Before the mobile harness can be built, run
npm run mobile:copy-prebuilds
to populate test/mobile/testAssets/ (driven by scripts/copy-mobile-test-assets.js). The script (a) fans out the single arm64 prebuild into the per-flavour directories the framework expects under prebuilds/, (b) copies the FP16 GGUF weights with a .gguf.bin suffix so the React Native bundler treats them as a binary asset, and (c) copies every test/images/*.{jpg,jpeg,png} into testAssets/ so the integration tests can resolve them via global.assetPaths on-device. None of these copied files are checked into git. See test/mobile/README.md for the lifecycle note about the shared native logger.
| Platform | CPU | Notes |
|---|---|---|
| Linux x64 | ✅ | |
| Linux arm64 | ✅ | |
| macOS arm64 (Apple) | ✅ | |
| macOS x64 (Intel) | ✅ | |
| Windows x64 | ✅ | |
| Android arm64 | ✅ | c++_shared STL |
| iOS arm64 | ✅ |
All platforms are produced by the shared reusable-prebuilds.yml
matrix and merged into a single prebuilds artifact for downstream
consumption. GPU (Vulkan / Metal / CUDA) is not currently supported.
Depending on the platform, one call to classifier.classify(buffer) takes from a few tens to a couple of hundred milliseconds.
classify() latencystd::thread::hardware_concurrency on every platform. The addon does not expose a tuning knob for this; if a future need arises, raise an issue and we can add one.stb_image_resize2 bilinear pass scale with source pixel count. The 224×224 tensor pass is fixed-cost; a 12 MP phone photo adds real overhead vs. a 640×480 webcam frame.load() already runs a full-pipeline warmup (synthetic-pattern pass through preprocess + GGML compute + output read) before returning, so the GGML compute buffers, weight buffer, and worker thread are fully materialised when the first classify() is dispatched. Even so, the first user-supplied call is typically a few tens of milliseconds slower than the steady-state average.load() once, classify() many times. Tearing down and rebuilding the model for each image is roughly 4–6× slower end-to-end and is never necessary outside of tests.| Component | Size |
|---|---|
| Bundled FP16 weights (mmapped) | 2.94 MB |
| Backend weight buffer (FP16 + folded BN + FP32 classifier) | ≈ 5.5 MB |
| Intermediate activations (compute buffer) | single-digit MB |
| Total resident during inference | ~8–10 MB |
All GGML compute buffers (input tensor, intermediate activations, output) are allocated once at load() time and reused on every classify() call — ggml_backend_tensor_set / _get are the only operations that touch them per request. Per-call C++ allocations are bounded: one input-buffer copy across the bare-runtime boundary, the decoded RGB buffer, the resized 224×224 RGB buffer, the WHCN F32 tensor, and the 3-element softmax + result vectors. Multiple ImageClassifier instances each keep their own compute buffer and worker thread — you pay the ~8 MB once per instance.
FP16 was chosen because it matches FP32 top-1 accuracy on the internal validation set while halving the on-disk footprint (≈3 MB vs ≈6 MB) and giving a measurable inference speed-up on every CPU backend we ship. More aggressive quantizations (Q8_0, Q4_K and below) were evaluated on the same validation set and showed noticeable accuracy degradation, which for a 3-class triage model is not acceptable. If you fine-tune your own MobileNetV3-Small, keep FP16 as the publish format unless you re-run the full validation suite at the lower precision.
The integration suite hooks the shared scripts/test-utils/performance-reporter.js via test/integration/utils.js. Running
npm run test:integration
writes test/results/performance-report.json with one total_time_ms entry per sample image, and in GitHub Actions also emits a Markdown step summary.
See [docs/architecture.md](docs/architecture.md) for the MobileNetV3-Small layer breakdown and graph construction notes, and [docs/data-flow.md](docs/data-flow.md) for the end-to-end request flow.
llama-cpp doesn't support CNN architectures, so this addon bypasses llama.cpp entirely and talks to the stable ggml_* / ggml_backend_* public API.
For this MobileNetV3-Small the GGML CPU backend is, in most configurations, slower per call than the same network running on a mature PyTorch or ONNX Runtime build with their hand-tuned convolution kernels. Because the model is very small (≈2.5 M params, single-digit-millisecond compute on a modern phone), the absolute gap is negligible for a triage workload and is dominated by image decode and JS↔native marshalling. If a substantially larger classifier is ever added on top of this same scaffolding, expect to invest extra effort in graph-level optimisations (operator fusion, matmul tiling, FP16 SIMD kernels, threadpool sizing) before the GGML path is competitive.
If you fine-tune or swap the underlying MobileNetV3 model, follow [docs/onnx-to-gguf-conversion.md](docs/onnx-to-gguf-conversion.md). The graph construction is parameterised by BLOCKS in MobileNetGraph.hpp — only classes and weights change between fine-tunes.
<package>/weights/mobilenetv3_3class_v3_fp16.gguf. Override with new ImageClassifier({ modelPath: '/abs/path.gguf' }) or set the QVAC_CLASSIFICATION_MODEL_PATH env variable.0.001 (see the guarded unit test) — the architecture is unusually sensitive to this constant.stb_image.h: make sure the stb vcpkg port is installed. The vcpkg-configuration.json pins it.libggml-cpu: the prebuild workflow copies all ggml::${_backend} targets into prebuilds/. Re-run bare-make install.Apache-2.0. See [LICENSE](LICENSE) and [NOTICE](NOTICE).
FAQs
GGML image classification addon for QVAC (MobileNetV3-Small CPU inference)
The npm package @qvac/classification-ggml receives a total of 7,757 weekly downloads. As such, @qvac/classification-ggml popularity was classified as popular.
We found that @qvac/classification-ggml demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.

Security News
Rolldown paused Rust React Compiler integration after a 5MB binary size increase raised concerns about shipping React-specific code to all Vite users.

Security News
/Research
Mini Shai-Hulud expands into the Go ecosystem after hitting LeoPlatform npm packages and targeting GitHub Actions workflows.