
Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
PDF to HTML or Text conversion using Apache Tika. Also generate PDF thumbnail using Apache PDFBox.





Convert PDF files to HTML, extract text, generate thumbnails, extract images, and extract metadata using Apache Tika and PDFBox
npm install pdf2html
yarn add pdf2html
pnpm add pdf2html
The installation process will automatically download the required Apache Tika and PDFBox JAR files. You'll see a progress indicator during the download.
const pdf2html = require('pdf2html');
const fs = require('fs');
// From file path
const html = await pdf2html.html('path/to/document.pdf');
console.log(html);
// From buffer
const pdfBuffer = fs.readFileSync('path/to/document.pdf');
const html = await pdf2html.html(pdfBuffer);
console.log(html);
// With options
const html = await pdf2html.html(pdfBuffer, {
maxBuffer: 1024 * 1024 * 10, // 10MB buffer
});
// From file path
const text = await pdf2html.text('path/to/document.pdf');
// From buffer
const pdfBuffer = fs.readFileSync('path/to/document.pdf');
const text = await pdf2html.text(pdfBuffer);
console.log(text);
// From file path
const htmlPages = await pdf2html.pages('path/to/document.pdf');
// From buffer
const pdfBuffer = fs.readFileSync('path/to/document.pdf');
const htmlPages = await pdf2html.pages(pdfBuffer);
htmlPages.forEach((page, index) => {
console.log(`Page ${index + 1}:`, page);
});
// Get text for each page
const textPages = await pdf2html.pages(pdfBuffer, {
text: true,
});
// From file path or buffer
const metadata = await pdf2html.meta(pdfBuffer);
console.log(metadata);
// Output: {
// title: 'Document Title',
// author: 'John Doe',
// subject: 'Document Subject',
// keywords: 'pdf, conversion',
// creator: 'Microsoft Word',
// producer: 'Adobe PDF Library',
// creationDate: '2023-01-01T00:00:00Z',
// modificationDate: '2023-01-02T00:00:00Z',
// pages: 10
// }
// From file path
const thumbnailPath = await pdf2html.thumbnail('path/to/document.pdf');
// From buffer
const pdfBuffer = fs.readFileSync('path/to/document.pdf');
const thumbnailPath = await pdf2html.thumbnail(pdfBuffer);
console.log('Thumbnail saved to:', thumbnailPath);
// Custom thumbnail options
const thumbnailPath = await pdf2html.thumbnail(pdfBuffer, {
page: 1, // Page number (default: 1)
imageType: 'png', // 'png' or 'jpg' (default: 'png')
width: 300, // Width in pixels (default: 160)
height: 400, // Height in pixels (default: 226)
});
// From file path
const imagePaths = await pdf2html.extractImages('path/to/document.pdf');
console.log('Extracted images:', imagePaths);
// Output: ['/absolute/path/to/files/image/document1.jpg', '/absolute/path/to/files/image/document2.png', ...]
// From buffer
const pdfBuffer = fs.readFileSync('path/to/document.pdf');
const imagePaths = await pdf2html.extractImages(pdfBuffer);
// With custom output directory
const imagePaths = await pdf2html.extractImages(pdfBuffer, {
outputDirectory: './extracted-images', // Custom output directory
});
// With custom buffer size for large PDFs
const imagePaths = await pdf2html.extractImages('large-document.pdf', {
outputDirectory: './output',
maxBuffer: 1024 * 1024 * 10, // 10MB buffer
});
This package includes TypeScript type definitions out of the box. No need to install @types/pdf2html.
import * as pdf2html from 'pdf2html';
// or
import { html, text, pages, meta, thumbnail, extractImages, PDFMetadata, PDFProcessingError } from 'pdf2html';
async function convertPDF() {
try {
// All methods accept string paths or Buffers
const htmlContent: string = await pdf2html.html('document.pdf');
const textContent: string = await pdf2html.text(Buffer.from(pdfData));
// Full type safety for options
const thumbnailPath = await pdf2html.thumbnail('document.pdf', {
page: 1, // number
imageType: 'png', // 'png' | 'jpg'
width: 300, // number
height: 400, // number
});
// TypeScript knows the shape of metadata
const metadata: PDFMetadata = await pdf2html.meta('document.pdf');
console.log(metadata['pdf:producer']); // string | undefined
console.log(metadata.resourceName); // string | undefined
} catch (error) {
if (error instanceof pdf2html.PDFProcessingError) {
console.error('PDF processing failed:', error.message);
console.error('Exit code:', error.exitCode);
}
}
}
// Input types - all methods accept either file paths or Buffers
type PDFInput = string | Buffer;
// Options interfaces
interface ProcessingOptions {
maxBuffer?: number; // Maximum buffer size in bytes
}
interface PageOptions extends ProcessingOptions {
text?: boolean; // Extract text instead of HTML
}
interface ThumbnailOptions extends ProcessingOptions {
page?: number; // Page number (default: 1)
imageType?: 'png' | 'jpg'; // Image format (default: 'png')
width?: number; // Width in pixels (default: 160)
height?: number; // Height in pixels (default: 226)
}
// Metadata structure with common fields
interface PDFMetadata {
'pdf:PDFVersion'?: string;
'pdf:producer'?: string;
'xmp:CreatorTool'?: string;
'dc:title'?: string;
'dc:creator'?: string;
resourceName?: string;
[key: string]: any; // Allows additional properties
}
// Error class
class PDFProcessingError extends Error {
command?: string; // The command that failed
exitCode?: number; // The process exit code
}
Full IntelliSense support in VS Code and other TypeScript-aware editors:
import { PDFProcessor, utils } from 'pdf2html';
// Using the PDFProcessor class directly
const html = await PDFProcessor.toHTML('document.pdf');
// Using utility classes
const { FileManager, HTMLParser } = utils;
await FileManager.ensureDirectories();
// Type guards
function isPDFProcessingError(error: unknown): error is pdf2html.PDFProcessingError {
return error instanceof pdf2html.PDFProcessingError;
}
// Generic helper with proper typing
async function processPDFSafely<T>(operation: () => Promise<T>, fallback: T): Promise<T> {
try {
return await operation();
} catch (error) {
if (isPDFProcessingError(error)) {
console.error(`PDF operation failed: ${error.message}`);
}
return fallback;
}
}
// Usage
const pages = await processPDFSafely(
() => pdf2html.pages('document.pdf', { text: true }),
[] // fallback to empty array
);
By default, the maximum buffer size is 2MB. For large PDFs, you may need to increase this:
const options = {
maxBuffer: 1024 * 1024 * 50, // 50MB buffer
};
// Apply to any method
await pdf2html.html('large-file.pdf', options);
await pdf2html.text('large-file.pdf', options);
await pdf2html.pages('large-file.pdf', options);
await pdf2html.meta('large-file.pdf', options);
await pdf2html.thumbnail('large-file.pdf', options);
Always wrap your calls in try-catch blocks for proper error handling:
try {
const html = await pdf2html.html('document.pdf');
// Process HTML
} catch (error) {
if (error.code === 'ENOENT') {
console.error('PDF file not found');
} else if (error.message.includes('Java')) {
console.error('Java is not installed or not in PATH');
} else {
console.error('PDF processing failed:', error.message);
}
}
pdf2html.html(input, [options])Converts PDF to HTML format.
string | Buffer - Path to the PDF file or PDF bufferobject (optional)
maxBuffer number - Maximum buffer size in bytes (default: 2MB)Promise<string> - HTML contentpdf2html.text(input, [options])Extracts text from PDF.
string | Buffer - Path to the PDF file or PDF bufferobject (optional)
maxBuffer number - Maximum buffer size in bytesPromise<string> - Extracted textpdf2html.pages(input, [options])Processes PDF page by page.
string | Buffer - Path to the PDF file or PDF bufferobject (optional)
text boolean - Extract text instead of HTML (default: false)maxBuffer number - Maximum buffer size in bytesPromise<string[]> - Array of HTML or text stringspdf2html.meta(input, [options])Extracts PDF metadata.
string | Buffer - Path to the PDF file or PDF bufferobject (optional)
maxBuffer number - Maximum buffer size in bytesPromise<object> - Metadata objectpdf2html.thumbnail(input, [options])Generates a thumbnail image from PDF.
string | Buffer - Path to the PDF file or PDF bufferobject (optional)
page number - Page to thumbnail (default: 1)imageType string - 'png' or 'jpg' (default: 'png')width number - Thumbnail width (default: 160)height number - Thumbnail height (default: 226)maxBuffer number - Maximum buffer size in bytesPromise<string> - Path to generated thumbnailIf automatic download fails (e.g., due to network restrictions), you can manually download the dependencies:
Create the vendor directory:
mkdir -p node_modules/pdf2html/vendor
Download the required JAR files:
cd node_modules/pdf2html/vendor
# Download Apache PDFBox
wget https://archive.apache.org/dist/pdfbox/2.0.34/pdfbox-app-2.0.34.jar
# Download Apache Tika
wget https://archive.apache.org/dist/tika/3.2.0/tika-app-3.2.0.jar
Verify the files are in place:
ls -la node_modules/pdf2html/vendor/
# Should show both JAR files
"Java is not installed"
java is in your system PATHjava -version"File not found" errors
"Buffer size exceeded"
"Download failed during installation"
Enable debug output for troubleshooting:
DEBUG=pdf2html node your-script.js
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
git checkout -b feature/AmazingFeature)git commit -m 'Add some AmazingFeature')git push origin feature/AmazingFeature)This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
Made with ❤️ by the pdf2html community
FAQs
PDF to HTML or Text conversion using Apache Tika. Also generate PDF thumbnail using Apache PDFBox.
The npm package pdf2html receives a total of 8,269 weekly downloads. As such, pdf2html popularity was classified as popular.
We found that pdf2html demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
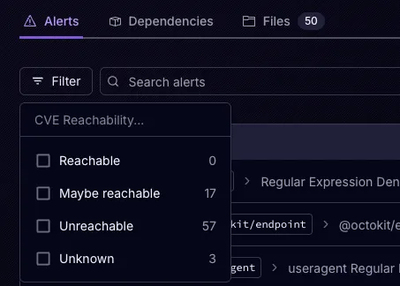
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.