
Product
Announcing Precomputed Reachability Analysis in Socket
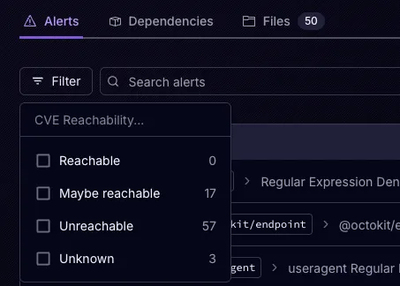
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.
By Martin Torp - Jul 30, 2025
robots-txt-parser
Advanced tools
A lightweight robots.txt parser for Node.js with support for wildcards, caching and promises.
![]()
![]()
A lightweight robots.txt parser for Node.js with support for wildcards, caching and promises.
Via NPM: npm install robots-txt-parser --save.
After installing robots-txt-parser it needs to be required and initialised:
const robotsParser = require('robots-txt-parser');
const robots = robotsParser(
{
userAgent: 'Googlebot', // The default user agent to use when looking for allow/disallow rules, if this agent isn't listed in the active robots.txt, we use *.
allowOnNeutral: false // The value to use when the robots.txt rule's for allow and disallow are balanced on whether a link can be crawled.
});
Example Usage:
const robotsParser = require('robots-txt-parser');
const robots = robotsParser(
{
userAgent: 'Googlebot', // The default user agent to use when looking for allow/disallow rules, if this agent isn't listed in the active robots.txt, we use *.
allowOnNeutral: false, // The value to use when the robots.txt rule's for allow and disallow are balanced on whether a link can be crawled.
},
);
robots.useRobotsFor('http://example.com')
.then(() => {
robots.canCrawlSync('http://example.com/news'); // Returns true if the link can be crawled, false if not.
robots.canCrawl('http://example.com/news', (value) => {
console.log('Crawlable: ', value);
}); // Calls the callback with true if the link is crawlable, false if not.
robots.canCrawl('http://example.com/news') // If no callback is provided, returns a promise which resolves with true if the link is crawlable, false if not.
.then((value) => {
console.log('Crawlable: ', value);
});
});
Below is a condensed form of the documentation, each is a function that can be found on the robotsParser object.
| Method | Parameters | Return |
|---|---|---|
| parseRobots(key, string) | key:String, string:String | None |
| isCached(domain) | domain:String | Boolean for whether robots.txt for url is cached. |
| fetch(url) | url:String | Promise, resolved when robots.txt retrieved. |
| useRobotsFor(url) | url:String | Promise, resolved when robots.txt is fetched. |
| canCrawl(url) | url:String, callback:Func (Opt) | Promise, resolves with Boolean. |
| getSitemaps() | callback:Func (Opt) | Promise if no callback provided, resolves with [String]. |
| getCrawlDelay() | callback:Func (Opt) | Promise if no callback provided, resolves with Number. |
| getCrawlableLinks(links) | links:[String], callback:Func (Opt) | Promise if no callback provided, resolves with [String]. |
| getPreferredHost() | callback:Func (Opt) | Promise if no callback provided, resolves with String. |
| setUserAgent(userAgent) | userAgent:String | None. |
| setAllowOnNeutral(allow) | allow:Boolean | None. |
| clearCache() | None | None. |
robots.parseRobots(key, string)
Parses a string representation of a robots.txt file and cache's it with the given key.
None.
robots.parseRobots('https://example.com',
`
User-agent: *
Allow: /*.php$
Disallow: /
`);
robots.isCached(domain)
A method used to check if a robots.txt has already been fetched and parsed.
Returns true if a robots.txt has already been fetched and cached by the robots-txt-parser.
robots.isCached('https://example.com'); // true or false
robots.isCached('example.com'); // Attempts to check the cache for only http:// and returns true or false.
robots.fetch(url)
Attempts to fetch and parse a robots.txt file located at the url, this method avoids checking the built-in cache and will always attempt to retrieve a fresh copy of the robots.txt.
Returns a Promise which will resolve once the robots.txt has been fetched with the parsed robots.txt.
robots.fetch('https://example.com/robots.txt')
.then((tree) => {
console.log(Object.keys(tree)); // Will log sitemap and any user agents.
});
robots.useRobotsFor(url)
Attempts to download and use the robots.txt at the given url, if the robots.txt has already been downloaded, reads from the cached copy instead.
Returns a promsise that resolves once the URL is fetched and parsed.
robots.useRobotsFor('https://example.com/news')
.then(() => {
// Logic to check if links are crawlable.
});
robots.canCrawl(url, callback)
Tests whether a url can be crawled for the current active robots.txt and user agent. If a robots.txt isn't cached for the domain of the url, it is fetched and parsed before returning a boolean value.
Returns a Promise which will resolve with a boolean value.
robots.canCrawl('https://example.com/news')
.then((crawlable) => {
console.log(crawlable); // Will log a boolean value.
});
robots.getSitemaps(callback)
Returns a list of sitemaps present on the active robots.txt.
Returns a Promise which will resolve with an array of strings.
robots.getSitemaps()
.then((sitemaps) => {
console.log(sitemaps); // Will log an list of strings.
});
robots.getCrawlDelay(callback)
Returns the crawl delay on requests to the current active robots.txt.
Returns a Promise which will resolve with an Integer.
robots.getCrawlDelay()
.then((crawlDelay) => {
console.log(crawlDelay); // Will be an Integer greater than or equal to 0.
});
robots.getCrawlableLinks(links, callback)
Takes an array of links and returns an array of links which are crawlable
for the current active robots.txt.
A Promise that will resolve to contain an Array of all the crawlable links.
robots.getCrawlableLinks([])
.then((links) => {
console.log(links);
});
robots.getPreferredHost(callback)
Returns the preferred host name specified in the active robots.txt's host: directive or null if there isn't one.
An String if the host is defined, undefined otherwise.
robots.getPreferredHost()
.then((host) => {
console.log(host);
});
robots.setUserAgent(userAgent)
Sets the current user agent to use when checking if a link can be crawled.
undefined
robots.setUserAgent('exampleBot'); // When interacting with the robots.txt we now look for records for 'exampleBot'.
robots.setUserAgent('testBot'); // When interacting with the robots.txt we now look for records for 'testBot'.
robots.setAllowOnNeutral(allow)
Sets the canCrawl behaviour to return true or false when the robots.txt rules are balanced on whether a link should be crawled or not.
undefined
robots.setAllowOnNeutral(true); // If the allow/disallow rules are balanced, canCrawl returns true.
robots.setAllowOnNeutral(false); // If the allow/disallow rules are balanced, canCrawl returns false.
robots.clearCache()
The cache can get extremely long over extended crawling, this simple method resets the cache.
None
None
robots.clearCache();
Synchronous variants of the API, will be deprecated in a future version.
robots.canCrawlSync(url)
Tests whether a url can be crawled for the current active robots.txt and user agent. This won't attempt to fetch the robots.txt if it is not cached.
Returns a boolean value depending on whether the url is crawlable. If there is no cached robots.txt for this url, it will always return true.
robots.canCrawlSync('https://example.com/news') // true or false.
robots.getSitemapsSync()
Returns a list of sitemaps present on the active robots.txt.
None
An Array of Strings.
robots.getSitemapsSync(); // Will be an array e.g. ['http://example.com/sitemap1.xml', 'http://example.com/sitemap2.xml'].
robots.getCrawlDelaySync()
Returns the crawl delay on specified in the active robots.txt's for the active user agent
None
An Integer greater than or equal to 0.
robots.getCrawlDelaySync(); // Will be an Integer.
robots.getCrawlableLinksSync(links)
Takes an array of links and returns an array of links which are crawlable
for the current active robots.txt.
An Array of all the links are crawlable.
robots.getCrawlableLinks(['example.com/test/news', 'example.com/test/news/article']); // Will return an array of the links that can be crawled.
robots.getPreferredHostSync()
Returns the preferred host name specified in the active robots.txt's host: directive or undefined if there isn't one.
None
An String if the host is defined, undefined otherwise.
robots.getPreferredHostSync(); // Will be a string if the host directive is defined .
See LICENSE file.
FAQs
A lightweight robots.txt parser for Node.js with support for wildcards, caching and promises.
The npm package robots-txt-parser receives a total of 1,287 weekly downloads. As such, robots-txt-parser popularity was classified as popular.
We found that robots-txt-parser demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.

Product
Add secure dependency scanning to Claude Desktop with Socket MCP, a one-click extension that keeps your coding conversations safe from malicious packages.