Huge News!Announcing our $40M Series B led by Abstract Ventures.Learn More →
websitecategorization
Advanced tools
websitecategorization - npm Package Compare versions
Comparing version 1.0.11 to 1.0.12
| { | ||
| "name": "websitecategorization", | ||
| "version": "1.0.11", | ||
| "version": "1.0.12", | ||
| "homepage": "websitecategorizationapi.com", | ||
@@ -5,0 +5,0 @@ "keywords": [ |
@@ -55,21 +55,40 @@ <a href="https://github.com/explainableaixai/websitecategorizationapi/issues"><img alt="GitHub issues" src="https://img.shields.io/github/issues/explainableaixai/websitecategorizationapi"></a> | ||
| For this reasons, we most often machine learning models for text classifications. | ||
| For this reason, we use machine learning models for text classifications. | ||
| In early period of machine learning, the most common models used for text classification were ranging from simpler ones, like Naive Bayes to more complex ones like Random Forests, Support Vector Machines and Logistic Regression. | ||
| Support Vector Machines are especially good in terms of accuracy and f1 scores achieved, it however has a downside in that the complexity of training a SVM model rapidly increases with number of texts in training dataset. | ||
| Support Vector Machines are especially good in terms of accuracy and f1 scores achieved on text classification tasks, they however have a downside in that the complexity of training a SVM model rapidly increases with number of texts in training dataset. | ||
| In last decade, with the rise of neural networks, more text classification models utilize the deep neural networks for this purpose. Earlier deep neural networks for text classification were often based on LSTM neural net. In recent times there have been other neural network architectures successfuly used for text classification. | ||
| In last decade, with the rise of neural networks, more text classification models are based on the latter. | ||
| Authors in this highly cited paper: [https://arxiv.org/pdf/1803.01271.pdf](https://arxiv.org/pdf/1803.01271.pdf) researched convolutional neural networks for text classification and came to conclusion that even a simple convolutional archi- | ||
| tecture outperforms canonical recurrent networks as the previously mentioned LSTMs across different classification tasks. | ||
| Earlier deep neural networks for text classification were often based on LSTM neural net. In recent times there have been other neural network architectures successfuly used for text classification. | ||
| The NN model in question can be accessed here: [https://github.com/locuslab/TCN](https://github.com/philipperemy/keras-tcn), with keras implementation available at [https://github.com/philipperemy/keras-tcn](https://github.com/philipperemy/keras-tcn). | ||
| Authors in this highly cited paper: [https://arxiv.org/pdf/1803.01271.pdf](https://arxiv.org/pdf/1803.01271.pdf) researched convolutional neural networks for text classification and came to conclusion that even a simple convolutional architecture outperforms canonical recurrent networks such as the previously mentioned LSTMs, across different classification tasks. | ||
| The NN model from the paper can be accessed here: [https://github.com/locuslab/TCN](https://github.com/philipperemy/keras-tcn), with keras implementation available at [https://github.com/philipperemy/keras-tcn](https://github.com/philipperemy/keras-tcn). | ||
| # Feature engineering | ||
| When using texts as input to machine learning models, we need to convert them in a numerical format. This is part of the feature engineering process, which can also include other steps, e.g. lemmatization, removal of stop words, removal of punctuations, etc. | ||
| Once these pre-processing is done, we can use different approaches in converting texts to numerical representation. One of the simplest one is Bag of Words, where we simply count the number of times a word has occured in text. | ||
| A more complex, "count" method is TF-IDF or term frequence-inverse document frequency. In this case we count the number of times a token,word, term has occured in a document but "correct" this for its frequency in the whole corpus. | ||
| In this way, common words like "the" are discounted because they occur commonly in the whole corpus, whereas words that are specific to some document but are not often found elsewhere are not corrected by much of a factor. | ||
| A more advanced form of feature engineering includes using shallow neural nets for representation of texts. One approach from this group is Word2Vec where we represent each word with fixed-dimensional vector. | ||
| Vectors of words are "learned" by training the shallow neural network of Word2Vec on a large corpus of documents with the main idea being that words that are semantically similar should be located near in the hyperspace of words vectors. | ||
| A well known example is that arithmetic operation of vector("King") - vector("Queen") should be a very similar vector to the vector obtained with vector("Man") - vector("Woman"). | ||
| The most well known Word2Vec model is the one trained on Google News corpus and can be accessed at [https://huggingface.co/fse/word2vec-google-news-300](https://huggingface.co/fse/word2vec-google-news-300). | ||
| There also implementation available in many NLP libraries, e.g. in spacy: [https://spacy.io/usage/embeddings-transformers](https://spacy.io/usage/embeddings-transformers). | ||
| # UI Dashboard | ||
| Website categorization service can also be used in form of dashboard UI, as seen here: | ||
| Website categorization service can be used both as API or in form of dashboard UI, as seen here: | ||
@@ -76,0 +95,0 @@ 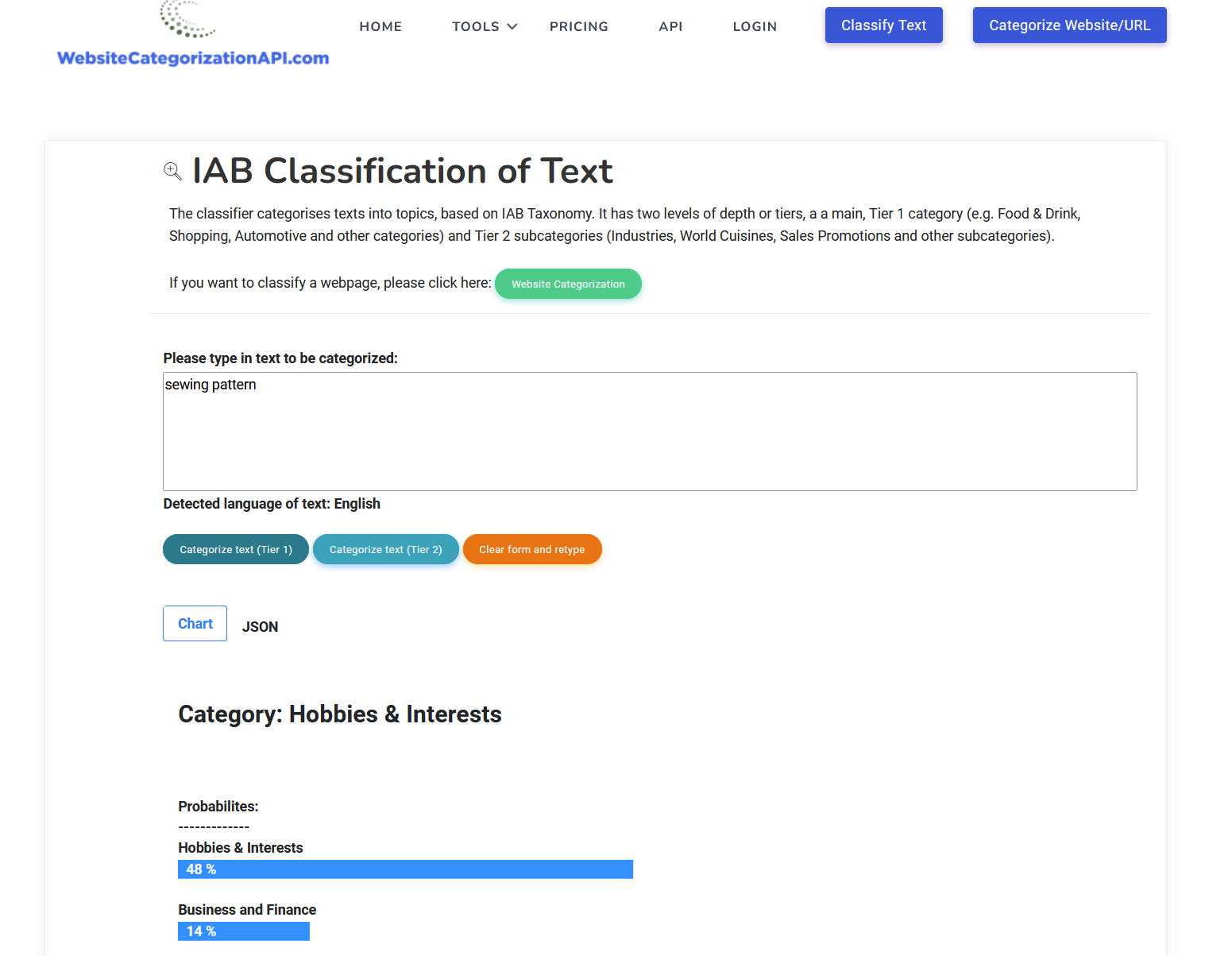 |
No alert changes
Improved metrics
- Total package byte prevSize
- increased by20.7%
11675
- Number of lines in readme file
- increased by7.48%
273
No dependency changes