Product
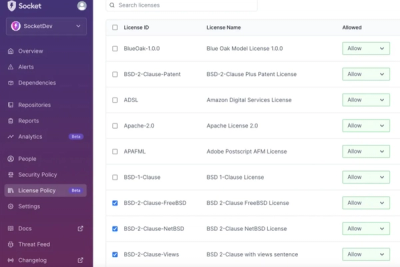
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024



![]()
Anonymize df is a package that helps you quickly and easily generate realistic fake data from a Pandas DataFrame.
You can install anonymizedf using pip:
pip install anonymizedf
This will also try downloading the tableau hyper api and pandas packages if you don't have them already.
If you don't want to use pip you can also download this repository and execute:
python setup.py install
import pandas as pd
from anonymizedf.anonymizedf import anonymize
# Import the data
df = pd.read_csv("https://query.data.world/s/shcktxndtu3ojonm46tb5udlz7sp3e")
# Prepare the data to be anonymized
an = anonymize(df)
# Select what data you want to anonymize and your preferred style
# Example 1 - just updates df
an.fake_names("Customer Name")
an.fake_ids("Customer ID")
an.fake_whole_numbers("Loyalty Reward Points")
an.fake_categories("Segment")
an.fake_dates("Date")
an.fake_decimal_numbers("Fraction")
# Example 2 - method chaining
fake_df = (
an
.fake_names("Customer Name", chaining=True)
.fake_ids("Customer ID", chaining=True)
.fake_whole_numbers("Loyalty Reward Points", chaining=True)
.fake_categories("Segment", chaining=True)
.fake_dates("Date", chaining=True)
.fake_decimal_numbers("Fraction", chaining=True)
.show_data_frame()
)
# Example 3 - multiple assignments
fake_df = an.fake_names("Customer Name")
fake_df = an.fake_ids("Customer ID")
fake_df = an.fake_whole_numbers("Loyalty Reward Points")
fake_df = an.fake_categories("Segment")
fake_df = an.fake_dates("Date")
fake_df = an.fake_decimal_numbers("Fraction")
fake_df.to_csv("fake_customers.csv", index=False)
# One thing to note is that you can't directly pass in a list of columns.
# If you want to apply the same function to multiple columns there are many ways to do that.
# Example 4 - for multiple columns
for column in column_list:
an.fake_categories(column)
| Customer ID | Customer Name | Loyalty Reward Points | Segment | Date | Fraction | Fake_Customer Name | Fake_Customer ID | Fake_Loyalty Reward Points | Fake_Segment | Fake_Date | Fake_Fraction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AA-10315 | Alex Avila | 76 | Consumer | 01/01/2000 | 7.6 | Christian Metcalfe-Reid | YEJP71011502726136 | 558 | Segment 1 | 1978-11-09 | 29.96 |
| 1 | AA-10375 | Allen Armold | 369 | Consumer | 02/01/2000 | 36.9 | Helen Taylor | XWOB83170110594048 | 286 | Segment 1 | 1989-12-29 | 72.50 |
| 2 | AA-10480 | Andrew Allen | 162 | Consumer | 03/01/2000 | 16.2 | Joanne Price | VVCJ28547588747677 | 742 | Segment 1 | 1982-09-23 | 79.77 |
| 3 | AA-10645 | Anna Andreadi | 803 | Consumer | 04/01/2000 | 80.3 | Rhys Jones | OXCI12190813836802 | 206 | Segment 1 | 2000-10-14 | 7.15 |
| 4 | AB-10015 | Aaron Bergman | 935 | Consumer | 05/01/2000 | 93.5 | Nigel Baldwin-Cook | JOXS05799252235987 | 914 | Segment 1 | 2018-01-30 | 40.66 |
FAQs
a convenient way to anonymize your data for analytics
We found that anonymizedf demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
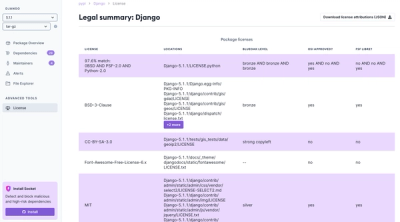
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
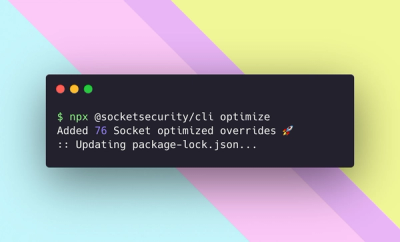
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.