
Security News
The Changelog Podcast: Practical Steps to Stay Safe on npm
Learn the essential steps every developer should take to stay secure on npm and reduce exposure to supply chain attacks.
By Sarah Gooding - Oct 31, 2025

![]()

$ pip install attacut
Remarks: Windows users need to install PyTorch before the command above. Please consult PyTorch.org for more details.
$ attacut-cli -h
AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai
Usage:
attacut-cli <src> [--dest=<dest>] [--model=<model>]
attacut-cli [-v | --version]
attacut-cli [-h | --help]
Arguments:
<src> Path to input text file to be tokenized
Options:
-h --help Show this screen.
--model=<model> Model to be used [default: attacut-sc].
--dest=<dest> If not specified, it'll be <src>-tokenized-by-<model>.txt
-v --version Show version
from attacut import tokenize, Tokenizer
# tokenize `txt` using our best model `attacut-sc`
words = tokenize(txt)
# alternatively, an AttaCut tokenizer might be instantiated directly, allowing
# one to specify whether to use `attacut-sc` or `attacut-c`.
atta = Tokenizer(model="attacut-sc")
words = atta.tokenize(txt)
Belows are brief summaries. More details can be found on our benchmarking page.
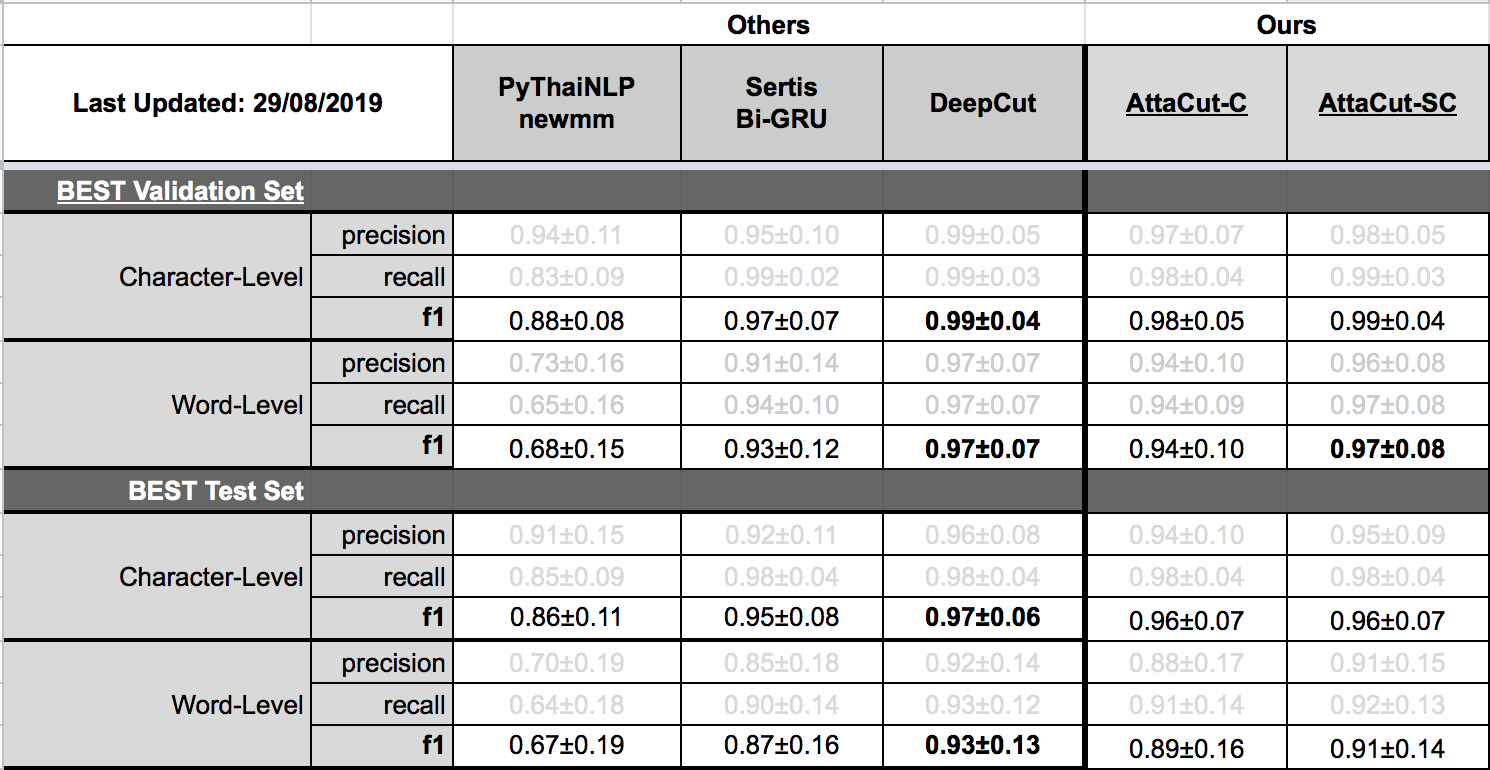
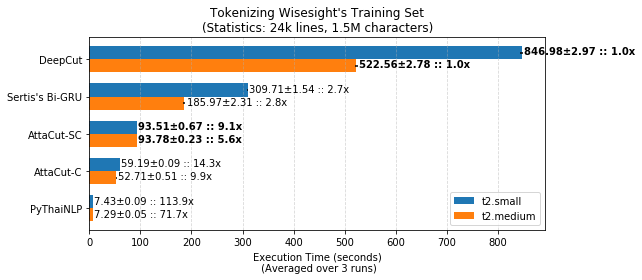
Please refer to our retraining page
This repository was initially done by Pattarawat Chormai, while interning at Dr. Attapol Thamrongrattanarit's NLP Lab, Chulalongkorn University, Bangkok, Thailand. Many people have involed in this project. Complete list of names can be found on Acknowledgement.
FAQs
Fast and Reasonably Accurate Word Tokenizer for Thai
We found that attacut demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
Learn the essential steps every developer should take to stay secure on npm and reduce exposure to supply chain attacks.

Security News
Experts push back on new claims about AI-driven ransomware, warning that hype and sponsored research are distorting how the threat is understood.

Security News
Ruby's creator Matz assumes control of RubyGems and Bundler repositories while former maintainers agree to step back and transfer all rights to end the dispute.