Product
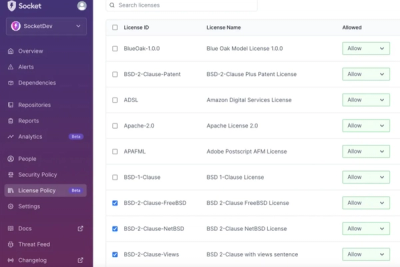
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
This package comes with a set of helpful auto grouping tools.
These tools solve a problem where you have M:N relations between two entities and need to join them together. Their functionality is also helpful when working with SQL views.
SELECT name, surname, job.name as job___name
FROM person
JOIN
works ON works.person_id = person.id
job ON job.id = works.job_id
WHERE
person.id = 2;
For a single person, who has two jobs, DB might output something like this:
| name | surname | job___name |
|---|---|---|
| Jane | Doe | Accountant |
| Jane | Doe | Developer |
Which might be OK when fetching only one person and his jobs. There are use cases, when you need to fetch more and more people. Output will be much larger. This is the place, where auto grouping tools come handy.
This function groups dict keys with same prefix under one dict key. Groups used as group keys are identified by group separator ___.
person = {
"name": "Jane",
"surname": "Doe",
"job___name": "Accountant",
"job___established": 2001
}
ret = auto_group_dict(person)
# Returns in
ret = {
"name": "Jane",
"surname": "Doe",
"job": {
"name": "Accountant",
"established": 2001,
}
}
IMPORTANT: All items which are inside lists are sorted exactly the same as they came from the DB.
Let's say that we have want to retrieve a new person from our DB. Jane Doe now has two jobs: an accountant and a developer.
Database returns two rows as specified above. But in object oriented world, it would be better for us to have it in one dict. This is where auto_group_list comes handy.
SELECT person.name, person.surname, job.name as jobs__name
FROM person
JOIN
works ON works.person_id = person.id
job ON job.id = works.job_id
WHERE
person.id = 2;
Assuming our SQL query returns 2 rows like this:
rows = [
{
"name": "Jane",
"surname": "Doe",
"jobs__name": "Accountant",
},
{
"name": "Jane",
"surname": "Doe",
"jobs__name": "Developer",
}
]
ret = auto_group_list(rows)
# Returns in
ret = {
"name": "Jane",
"surname": "Doe",
"jobs": [
{
"name": "Accountant"
},
{
"name": "Developer"
}
]
}
This is kind of handy, isn't it? But what if we want to omit our WHERE statement? This is where auto_group_list_by_pkeys comes in place.
Is enhanced method based on auto_group_list functionality. It is best to group more lines of more persons as was mentioned in example above.
Lets imagine the situation you select two or more persons from database with their jobs:
SELECT person.name, person.surname, job.name as jobs__name
FROM person
JOIN
works ON works.person_id = person.id
job ON job.id = works.job_id
WHERE
person.id in (2, 3)
ORDER BY person.id;
Assuming our SQL query returns 4 rows like this:
rows = [
{
"name": "Jane",
"surname": "Doe",
"jobs__name": "Accountant",
},
{
"name": "Jane",
"surname": "Doe",
"jobs__name": "Developer",
},
{
"name": "Jonh",
"surname": "Doesnt",
"jobs__name": "Store manager",
},
{
"name": "John",
"surname": "Doesnt",
"jobs__name": "Destroyer",
}
]
ret = auto_group_list_multi(rows)
# Returns in
ret = [
{
"name": "Jane",
"surname": "Doe",
"jobs": [
{
"name": "Accountant"
},
{
"name": "Developer"
}
],
},
{
"name": "John",
"surname": "Doesnt",
"jobs": [
{
"name": "Store manager"
},
{
"name": "Destoyer"
}
],
}
]
How it works? It watchs column values of non-double underscored attributes. If values are changed it groups previous values of double underscored keys into list.
Next and the last useful is handy when you want to for example fetch multiple people from DB, keep m..n relations and have everything grouped nicely. Like so:
SELECT person.id as _id, person.name, person.surname, job.name as jobs__name
FROM person
JOIN
works ON works.person_id = person.id
job ON job.id = works.job_id
WHERE
person.id IN (2, 3);
Our person no. 2 is Jane Doe, who works as an accountant and a developer. Person no. 3 is John Doe, works as an DevOps Engineer and a developer.
Let's say our grouping key is _id.
Our fetched data converted to python might look something like this:
rows = [
{
"_id": 2,
"name": "Jane",
"surname": "Doe",
"jobs__name": "Accountant"
},
{
"_id": 2,
"name": "Jane",
"surname": "Doe",
"jobs__name": "Developer"
},
{
"_id": 3,
"name": "John",
"surname": "Doe",
"jobs__name": "DevOps Engineer"
},
{
"_id": 3,
"name": "John",
"surname": "Doe",
"jobs__name": "Developer"
}
]
Let's make it prettier!
ret = auto_group_list_by_pkeys(("_id",), rows, use_auto_group_dict=True)
# Returns dict with 2 items, grouped by key "_id"
ret = {
"2": {
"_id": 2,
"name": "Jane",
"surname": "Doe",
"jobs": [
{
"name": "Accountant"
},
{
"name": "Developer"
}
]
},
"3": {
"_id": 3,
"name": "John",
"surname": "Doe",
"jobs": [
{
"name": "DevOps Engineer"
},
{
"name": "Developer"
}
]
}
}
Now we have all our cases covered, ready to go.
A few tool functions are avaliable in module tools.
List of avaliable functions:
dicts_into_list: Converts dict of dicts into list structure.sort_list_of_dicts: Sort list of dicts by selected column.dict_pass: Whitelist dictionary attributes.dict_filter: Blacklist dictionary attributes.list_into_dict: Converts list into dict where dict keys are list indexes.dict_swap: Swap dict keys into values and values into keys.map_dict_into_list: Maps dict keys into list positions based on keys_map defined in key map listchunk_list: Iterator which divides list into chunks with specified sizeFAQs
Tools for creating tree structures from flat list of dicts
We found that auto-group demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
Product
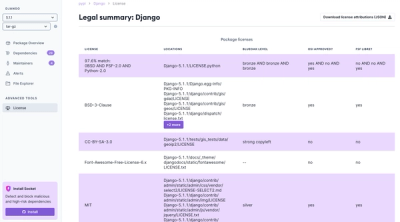
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
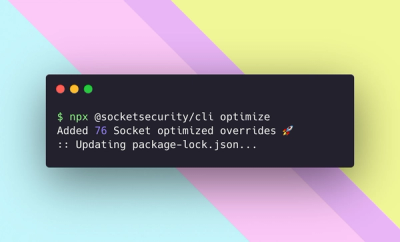
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.