
Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
A Pythonic rate limiter for OpenAI, Anthropic, and OpenRouter APIs that provides a high-level chat completion interface with automatic rate limit management.
async/await or synchronous codepip install chat-limiter
Or with uv:
uv add chat-limiter
import asyncio
from chat_limiter import ChatLimiter, Message, MessageRole
async def main():
# Auto-detect provider and use environment variable for API key
async with ChatLimiter.for_model("gpt-4o") as limiter:
response = await limiter.chat_completion(
model="gpt-4o",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
print(response.choices[0].message.content)
# Or provide API key explicitly
async with ChatLimiter.for_model("claude-3-5-sonnet-20241022", api_key="sk-ant-...") as limiter:
response = await limiter.simple_chat(
model="claude-3-5-sonnet-20241022",
prompt="What is Python?",
max_tokens=100
)
print(response)
asyncio.run(main())
Set your API keys as environment variables:
export OPENAI_API_KEY="sk-your-openai-key"
export ANTHROPIC_API_KEY="sk-ant-your-anthropic-key"
export OPENROUTER_API_KEY="sk-or-your-openrouter-key"
The library will automatically detect the provider from the model name and use the appropriate environment variable.
For custom models or when auto-detection fails:
async with ChatLimiter.for_model(
"custom-model-name",
provider="openai", # or "anthropic", "openrouter"
api_key="sk-key"
) as limiter:
response = await limiter.chat_completion(
model="custom-model-name",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
from chat_limiter import ChatLimiter, Message, MessageRole
with ChatLimiter.for_model("gpt-4o") as limiter:
response = limiter.chat_completion_sync(
model="gpt-4o",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
print(response.choices[0].message.content)
# Or use the simple interface
text_response = limiter.simple_chat_sync(
model="gpt-4o",
prompt="What is the capital of France?",
max_tokens=50
)
print(text_response)
import asyncio
from chat_limiter import (
ChatLimiter,
Message,
MessageRole,
ChatCompletionRequest,
process_chat_completion_batch,
create_chat_completion_requests,
BatchConfig
)
async def batch_example():
# Create requests from simple prompts
requests = create_chat_completion_requests(
model="gpt-4o",
prompts=["Hello!", "How are you?", "What is Python?"],
max_tokens=50,
temperature=0.7
)
async with ChatLimiter.for_model("gpt-4o") as limiter:
# Process with custom configuration
config = BatchConfig(
max_concurrent_requests=5,
max_retries_per_item=3,
group_by_model=True
)
results = await process_chat_completion_batch(limiter, requests, config)
# Extract successful responses
for result in results:
if result.success:
response = result.result
print(response.choices[0].message.content)
asyncio.run(batch_example())
The library automatically detects providers based on model names:
gpt-4o, gpt-4o-mini, gpt-3.5-turbo, etc.claude-3-5-sonnet-20241022, claude-3-haiku-20240307, etc.openai/gpt-4o, anthropic/claude-3-sonnet, etc.OpenAI
x-ratelimit-*)Anthropic
anthropic-ratelimit-*)OpenRouter
For advanced users who need direct HTTP access:
from chat_limiter import ChatLimiter, Provider
async with ChatLimiter(
provider=Provider.OPENAI,
api_key="sk-your-key"
) as limiter:
# Direct HTTP requests
response = await limiter.request(
"POST", "/chat/completions",
json={
"model": "gpt-4o",
"messages": [{"role": "user", "content": "Hello!"}]
}
)
result = response.json()
print(result["choices"][0]["message"]["content"])
import httpx
from chat_limiter import ChatLimiter
# Use custom HTTP client
custom_client = httpx.AsyncClient(
timeout=httpx.Timeout(60.0),
headers={"Custom-Header": "value"}
)
async with ChatLimiter.for_model(
"gpt-4o",
http_client=custom_client
) as limiter:
response = await limiter.chat_completion(
model="gpt-4o",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
from chat_limiter import ChatLimiter, ProviderConfig, Provider
# Custom provider configuration
config = ProviderConfig(
provider=Provider.OPENAI,
base_url="https://api.openai.com/v1",
default_request_limit=100,
default_token_limit=50000,
max_retries=5,
base_backoff=2.0,
request_buffer_ratio=0.8 # Use 80% of limits
)
async with ChatLimiter(config=config, api_key="sk-key") as limiter:
response = await limiter.chat_completion(
model="gpt-4o",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
from chat_limiter import ChatLimiter, Message, MessageRole
from tenacity import RetryError
import httpx
async with ChatLimiter.for_model("gpt-4o") as limiter:
try:
response = await limiter.chat_completion(
model="gpt-4o",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
except RetryError as e:
print(f"Request failed after retries: {e}")
except httpx.HTTPStatusError as e:
print(f"HTTP error: {e.response.status_code}")
except httpx.RequestError as e:
print(f"Request error: {e}")
async with ChatLimiter.for_model("gpt-4o") as limiter:
# Make some requests...
await limiter.chat_completion(
model="gpt-4o",
messages=[Message(role=MessageRole.USER, content="Hello!")]
)
# Check current limits and usage
limits = limiter.get_current_limits()
print(f"Requests used: {limits['requests_used']}/{limits['request_limit']}")
print(f"Tokens used: {limits['tokens_used']}/{limits['token_limit']}")
# Reset usage tracking
limiter.reset_usage_tracking()
from chat_limiter import Message, MessageRole
messages = [
Message(role=MessageRole.SYSTEM, content="You are a helpful assistant."),
Message(role=MessageRole.USER, content="Hello!"),
Message(role=MessageRole.ASSISTANT, content="Hi there!"),
Message(role=MessageRole.USER, content="How are you?")
]
response = await limiter.chat_completion(
model="gpt-4o",
messages=messages,
max_tokens=100, # Maximum tokens to generate
temperature=0.7, # Sampling temperature (0-2)
top_p=0.9, # Top-p sampling
stop=["END"], # Stop sequences
stream=False, # Streaming response
frequency_penalty=0.0, # Frequency penalty (-2 to 2)
presence_penalty=0.0, # Presence penalty (-2 to 2)
top_k=40, # Top-k sampling (Anthropic/OpenRouter)
)
from chat_limiter import create_chat_completion_requests, process_chat_completion_batch
# Create requests from prompts
requests = create_chat_completion_requests(
model="gpt-4o",
prompts=["Question 1", "Question 2", "Question 3"],
max_tokens=50
)
async with ChatLimiter.for_model("gpt-4o") as limiter:
results = await process_chat_completion_batch(limiter, requests)
# Process results
for result in results:
if result.success:
print(result.result.choices[0].message.content)
else:
print(f"Error: {result.error}")
from chat_limiter import BatchConfig
config = BatchConfig(
max_concurrent_requests=10, # Concurrent request limit
max_workers=4, # Thread pool size for sync
max_retries_per_item=3, # Retries per failed item
retry_delay=1.0, # Base retry delay
stop_on_first_error=False, # Continue on individual failures
group_by_model=True, # Group requests by model
adaptive_batch_size=True # Adapt batch size to rate limits
)
| Provider | Request Limits | Token Limits | Dynamic Discovery | Special Features |
|---|---|---|---|---|
| OpenAI | ✅ RPM | ✅ TPM | ✅ Headers | Model detection, batch optimization |
| Anthropic | ✅ RPM | ✅ Input/Output TPM | ✅ Headers | Tier handling, system messages |
| OpenRouter | ✅ RPM | ✅ TPM | ✅ Auth endpoint | Multi-model, credit tracking |
The library includes a comprehensive test suite:
# Run tests
uv run pytest
# Run with coverage
uv run pytest --cov=chat_limiter
# Run specific test file
uv run pytest tests/test_high_level_interface.py -v
# Clone the repository
git clone https://github.com/your-repo/chat-limiter.git
cd chat-limiter
# Install dependencies
uv sync --group dev
# Run linting
uv run ruff check src/ tests/
# Run type checking
uv run mypy src/
# Format code
uv run ruff format src/ tests/
Contributions are welcome! Please:
MIT License - see LICENSE file for details.
FAQs
A Pythonic rate limiter for OpenAI, Anthropic, and OpenRouter APIs
We found that chat-limiter demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
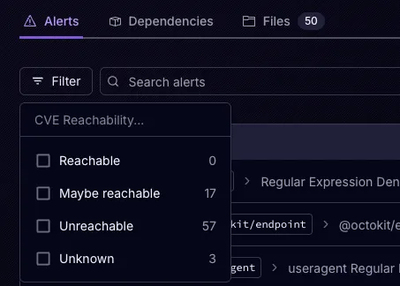
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.