Research
/Security News
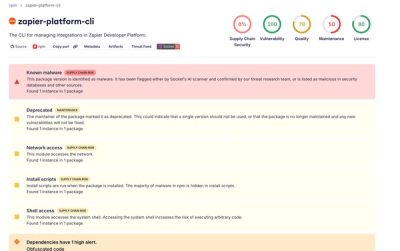
Shai Hulud Strikes Again (v2)
Another wave of Shai-Hulud campaign has hit npm with more than 500 packages and 700+ versions affected.
By Socket Research Team - Nov 24, 2025
confluent-kafka
Advanced tools

confluent-kafka-python provides a high-level Producer, Consumer and AdminClient compatible with all Apache Kafka™ brokers >= v0.8, Confluent Cloud and Confluent Platform.
Recommended for Production: While this client works with any Kafka deployment, it's optimized for and fully supported with Confluent Cloud (fully managed) and Confluent Platform (self-managed), which provide enterprise-grade security, monitoring, and support.
Unlike the basic Apache Kafka Python client, confluent-kafka-python provides:
librdkafka (C library) for maximum throughput and minimal latency, significantly outperforming pure Python implementations.Performance Note: The Apache Kafka Python client (kafka-python) is a pure Python implementation that, while functional, has significant performance limitations for high-throughput production use cases. confluent-kafka-python leverages the same high-performance C library (librdkafka) used by Confluent's other clients, providing enterprise-grade performance and reliability.
librdkafka, the battle-tested C client for Apache Kafka, ensuring maximum throughput, low latency, and stability. The client is supported by Confluent and is trusted in mission-critical production environments.AIOProducer) for seamless integration with modern Python applications using asyncio.For a step-by-step guide on using the client, see Getting Started with Apache Kafka and Python.
Additional examples can be found in the examples directory or the confluentinc/examples GitHub repo, which include demonstrations of:
Also see the Python client docs and the API reference.
Finally, the tests are useful as a reference for example usage.
Use the AsyncIO Producer inside async applications to avoid blocking the event loop.
import asyncio
from confluent_kafka.experimental.aio import AIOProducer
async def main():
p = AIOProducer({"bootstrap.servers": "mybroker"})
try:
# produce() returns a Future; first await the coroutine to get the Future,
# then await the Future to get the delivered Message.
delivery_future = await p.produce("mytopic", value=b"hello")
delivered_msg = await delivery_future
# Optionally flush any remaining buffered messages before shutdown
await p.flush()
finally:
await p.close()
asyncio.run(main())
Notes:
Producer.produce(...) (you can offload to a thread in async apps).For a more detailed example that includes both an async producer and consumer, see
examples/asyncio_example.py.
Architecture: For implementation details and component architecture, see the AIOProducer Architecture Overview.
Producer when your code runs under an event loop (FastAPI/Starlette, aiohttp, Sanic, asyncio workers) and must not block.Producer for scripts, batch jobs, and highest-throughput pipelines where you control threads/processes and can call poll()/flush() directly.Producer; if you need headers, call sync produce() via run_in_executor for that path.The AsyncIO producer and consumer integrate seamlessly with async Schema Registry serializers. See the Schema Registry Integration section below for full details.
from confluent_kafka import Producer
p = Producer({'bootstrap.servers': 'mybroker1,mybroker2'})
def delivery_report(err, msg):
""" Called once for each message produced to indicate delivery result.
Triggered by poll() or flush()."""
if err is not None:
print('Message delivery failed: {}'.format(err))
else:
print('Message delivered to {} [{}]'.format(msg.topic(), msg.partition()))
for data in some_data_source:
# Trigger any available delivery report callbacks from previous produce() calls
p.poll(0)
# Asynchronously produce a message. The delivery report callback will
# be triggered from the call to poll() above, or flush() below, when the
# message has been successfully delivered or failed permanently.
p.produce('mytopic', data.encode('utf-8'), callback=delivery_report)
# Wait for any outstanding messages to be delivered and delivery report
# callbacks to be triggered.
p.flush()
For a discussion on the poll based producer API, refer to the Integrating Apache Kafka With Python Asyncio Web Applications blog post.
This client provides full integration with Schema Registry for schema management and message serialization, and is compatible with both Confluent Platform and Confluent Cloud. Both synchronous and asynchronous clients are available.
Use the synchronous SchemaRegistryClient with the standard Producer and Consumer.
from confluent_kafka import Producer
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroSerializer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
# Configure Schema Registry Client
schema_registry_conf = {'url': 'http://localhost:8081'} # Confluent Platform
# For Confluent Cloud, add: 'basic.auth.user.info': '<sr-api-key>:<sr-api-secret>'
# See: https://docs.confluent.io/cloud/current/sr/index.html
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
# 2. Configure AvroSerializer
avro_serializer = AvroSerializer(schema_registry_client,
user_schema_str,
lambda user, ctx: user.to_dict())
# 3. Configure Producer
producer_conf = {
'bootstrap.servers': 'localhost:9092',
'key.serializer': StringSerializer('utf_8'),
'value.serializer': avro_serializer
}
producer = Producer(producer_conf)
# 4. Produce messages
producer.produce('my-topic', key='user1', value=some_user_object)
producer.flush()
Use the AsyncSchemaRegistryClient and Async serializers with AIOProducer and AIOConsumer. The configuration is the same as the synchronous client.
from confluent_kafka.experimental.aio import AIOProducer
from confluent_kafka.schema_registry import AsyncSchemaRegistryClient
from confluent_kafka.schema_registry._async.avro import AsyncAvroSerializer
# Setup async Schema Registry client and serializer
# (See configuration options in the synchronous example above)
schema_registry_conf = {'url': 'http://localhost:8081'}
schema_client = AsyncSchemaRegistryClient(schema_registry_conf)
serializer = await AsyncAvroSerializer(schema_client, schema_str=avro_schema)
# Use with AsyncIO producer
producer = AIOProducer({"bootstrap.servers": "localhost:9092"})
serialized_value = await serializer(data, SerializationContext("topic", MessageField.VALUE))
delivery_future = await producer.produce("topic", value=serialized_value)
Available async serializers: AsyncAvroSerializer, AsyncJSONSerializer, AsyncProtobufSerializer (and corresponding deserializers).
See also:
examples/asyncio_avro_producer.pyfrom confluent_kafka.schema_registry._async.avro import AsyncAvroSerializer, AsyncAvroDeserializer
from confluent_kafka.schema_registry._async.json_schema import AsyncJSONSerializer, AsyncJSONDeserializer
from confluent_kafka.schema_registry._async.protobuf import AsyncProtobufSerializer, AsyncProtobufDeserializer
Client-Side Field Level Encryption (CSFLE): To use Data Contracts rules (including CSFLE), install the rules extra (see Install section), and refer to the encryption examples in examples/README.md. For CSFLE-specific guidance, see the Confluent Cloud CSFLE documentation.
Note: The async Schema Registry interface mirrors the synchronous client exactly - same configuration options, same calling patterns, no unexpected gotchas or limitations. Simply add await to method calls and use the Async prefixed classes.
basic.auth.user.info (SR API key/secret) is correct and that the Schema Registry URL is for your specific cluster. Ensure you are using an SR API key, not a Kafka API key.subject.name.strategy configuration matches how your schemas are registered in Schema Registry, and that the topic and message field (key/value) pairing is correct.from confluent_kafka import Consumer
c = Consumer({
'bootstrap.servers': 'mybroker',
'group.id': 'mygroup',
'auto.offset.reset': 'earliest'
})
c.subscribe(['mytopic'])
while True:
msg = c.poll(1.0)
if msg is None:
continue
if msg.error():
print("Consumer error: {}".format(msg.error()))
continue
print('Received message: {}'.format(msg.value().decode('utf-8')))
c.close()
Create topics:
from confluent_kafka.admin import AdminClient, NewTopic
a = AdminClient({'bootstrap.servers': 'mybroker'})
new_topics = [NewTopic(topic, num_partitions=3, replication_factor=1) for topic in ["topic1", "topic2"]]
# Note: In a multi-cluster production scenario, it is more typical to use a replication_factor of 3 for durability.
# Call create_topics to asynchronously create topics. A dict
# of <topic,future> is returned.
fs = a.create_topics(new_topics)
# Wait for each operation to finish.
for topic, f in fs.items():
try:
f.result() # The result itself is None
print("Topic {} created".format(topic))
except Exception as e:
print("Failed to create topic {}: {}".format(topic, e))
The Producer, Consumer, and AdminClient are all thread safe.
# Basic installation
pip install confluent-kafka
# With Schema Registry support
pip install "confluent-kafka[avro,schemaregistry]" # Avro
pip install "confluent-kafka[json,schemaregistry]" # JSON Schema
pip install "confluent-kafka[protobuf,schemaregistry]" # Protobuf
# With Data Contract rules (includes CSFLE support)
pip install "confluent-kafka[avro,schemaregistry,rules]"
Note: Pre-built Linux wheels do not include SASL Kerberos/GSSAPI support. For Kerberos, see the source installation instructions in INSTALL.md. To use Schema Registry with the Avro serializer/deserializer:
pip install "confluent-kafka[avro,schemaregistry]"
To use Schema Registry with the JSON serializer/deserializer:
pip install "confluent-kafka[json,schemaregistry]"
To use Schema Registry with the Protobuf serializer/deserializer:
pip install "confluent-kafka[protobuf,schemaregistry]"
When using Data Contract rules (including CSFLE) add the rulesextra, e.g.:
pip install "confluent-kafka[avro,schemaregistry,rules]"
Install from source
For source install, see the Install from source section in INSTALL.md.
The Python client (as well as the underlying C library librdkafka) supports all broker versions >= 0.8. But due to the nature of the Kafka protocol in broker versions 0.8 and 0.9 it is not safe for a client to assume what protocol version is actually supported by the broker, thus you will need to hint the Python client what protocol version it may use. This is done through two configuration settings:
broker.version.fallback=YOUR_BROKER_VERSION (default 0.9.0.1)api.version.request=true|false (default true)When using a Kafka 0.10 broker or later you don't need to do anything
FAQs
Confluent's Python client for Apache Kafka
We found that confluent-kafka demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Another wave of Shai-Hulud campaign has hit npm with more than 500 packages and 700+ versions affected.

Product
Add real-time Socket webhook events to your workflows to automatically receive software supply chain alert changes in real time.
Security News
ENISA has become a CVE Program Root, giving the EU a central authority for coordinating vulnerability reporting, disclosure, and cross-border response.