Product
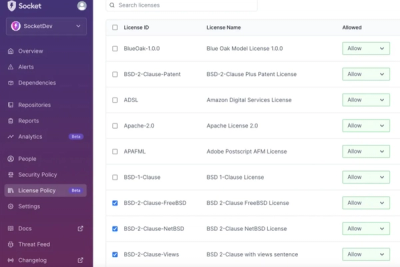
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
Python package for compressing floating-point PyTorch tensors. Accepts 1D float32 tensors on CPU or GPU for compression. Returns 1D float32 tensors on GPU for decompression. Works best for arrays larger than 32K floats.
Provides a fast (GPU-accelerated) compression algorithm to speed up the transmission of PyTorch model parameters, gradients, and other network data while training machine learning models.
This library has a guaranteed maximum error bound for the decompressed data.
Please read the src/cuszplus_f32.cu file for details on the compression algorithm, which is a fairly simple CUDA kernel used to prepare data for further compression on CPU using Zstd's fastest compression mode.
Released under BSD 3-Clause License for unrestricted use in commercial and open-source software.
Add the cuda_float_compress package to your Python environment.
# Install the `cuda_float_compress` package from PyPI
pip install -U cuda_float_compress
Then you can use it like this in your Python code:
import torch
import cuda_float_compress
import numpy as np
gpu_device = torch.device("cuda:0")
# Generate some random data
mean = 0
std = 1
num_floats = 32 * 1024
original_data = torch.tensor(np.random.normal(mean, std, num_floats), dtype=torch.float32).to(gpu_device)
# Compress the data, specifying the maximum error bound
error_bound = 0.0001
compressed_data = cuda_float_compress.cuszplus_compress(original_data, error_bound)
# --- Send the data over the network here ---
# Decompress the data
decompressed_data = cuda_float_compress.cuszplus_decompress(compressed_data, gpu_device)
These instructions require you have installed Conda.
git clone https://github.com/catid/cuda_float_compress
cd cuda_float_compress
git submodule update --init --recursive
conda create -n cfc python=3.10 -y && conda activate cfc
# Install dependencies. Right now this is just torch and numpy.
pip install -r requirements.txt
pip install .
After installing the package, you can run the example script (from the root directory of the project).
conda activate cfc
python examples/basic_example.py
# Install torchvision to test the model_compress_example.py script
pip install torchvision
python examples/model_compress_example.py
This is the result of running the examples/model_compress_example.py script on a consumer gaming PC with an Intel i9-12900K CPU and NVIDIA GeForce RTX 4090 (24GB) with CUDA 12.4:
(cfc) ➜ cuda_float_compress git:(main) ✗ python examples/model_compress_example.py
/home/catid/mambaforge/envs/cfc/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/catid/mambaforge/envs/cfc/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=RegNet_Y_32GF_Weights.IMAGENET1K_V1`. You can also use `weights=RegNet_Y_32GF_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
original_params.shape: torch.Size([145046770])
compressed_params = torch.Size([144257393]) torch.uint8 cpu
stem.0.weight = torch.Size([32, 3, 3, 3]) torch.float32 cuda:0
MSE: 3.46646800153394e-09 Max Error: 0.00010001659393310547
stem.1.weight = torch.Size([32]) torch.float32 cuda:0
MSE: 3.1061571093005114e-09 Max Error: 9.965896606445312e-05
...
trunk_output.block4.block4-0.f.c.1.bias = torch.Size([3712]) torch.float32 cuda:0
MSE: 3.3526341702838636e-09 Max Error: 9.996816515922546e-05
trunk_output.block4.block4-0.f.c.1.running_mean = torch.Size([3712]) torch.float32 cuda:0
MSE: 0.0 Max Error: 0.0
trunk_output.block4.block4-0.f.c.1.running_var = torch.Size([3712]) torch.float32 cuda:0
MSE: 0.0 Max Error: 0.0
fc.weight = torch.Size([1000, 3712]) torch.float32 cuda:0
MSE: 3.333001874494812e-09 Max Error: 0.00010001659393310547
fc.bias = torch.Size([1000]) torch.float32 cuda:0
MSE: 3.3378397823469186e-09 Max Error: 9.982381016016006e-05
Overall Compression Ratio: 4.02
Time to compress params: 0.40 s
Time to decompress params: 0.32 s
Terminology:
Original_i - Decompressed_i values.Mean{ (Original_i - Decompressed_i)^2 }On this 145M parameter model, it achieves a 4:1 compression ratio, matching the performance of 8-bit quantization with guaranteed accuracy of 0.0001 per parameter.
It seems to take about 0.5 seconds per 150M parameters to compress, and a little faster to decompress. So about 1.5GBPS.
If the data to compress has other features like low-rank structure, then applying SVD (Singular Value Decomposition) to the data before compression can be helpful. An example of using SVD for compression is here. This Python package does not implement SVD, but it is compatible with it.
Some quantization approaches, such as the one described here, accumulate the error in transmitted parameters and add the error back into the next communication round to compensate for the quantization error. This Python package does not implement this idea, but it is compatible with it.
If your network link is faster than 10Gbps, then it may not be an improvement over just sending the file uncompressed since it compresses at about 12 Gbps. So, it's well-suited for most kinds of Internet transfers, but maybe less useful to send data between servers that are connected via 100G+ InfiniBand or some other supercomputer-class switched network. I'm personally planning to use this for distributed training on the Internet, so it's a better option for me than a faster CUDA-only approach that gets a worse compression ratio.
Currently it only works for float32 tensors. I'd like to add support for FP16 once I start actually using this in my training scripts. Also it would make sense to add functionality to compress PyTorch model parameters of other types too like UINT64. For more general use-cases it would make sense to add a CPU version of the algorithm (one is provided in the cpu_compress_test/ folder).
I was inspired to work on this project by trying to fix bugs in the cuSZp project to use it for distributed ML training. Thanks for sharing your work!
Based on the Facebook Zstd project: https://github.com/facebook/zstd
Uses pybind11 for PyTorch tensor features: https://github.com/pybind/pybind11
FAQs
A PyTorch CUDA extension for floating-point compression
We found that cuda-float-compress demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
Product
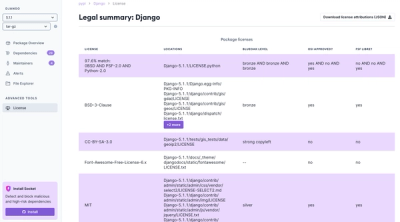
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
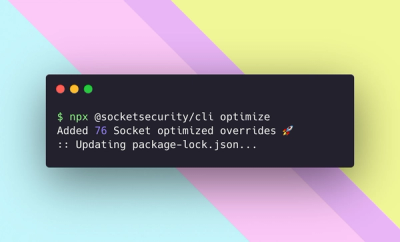
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.