Product
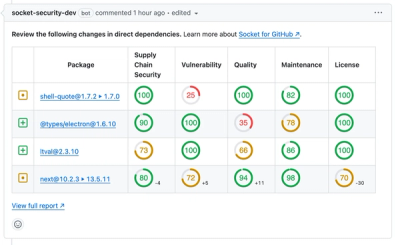
A New Design for GitHub PR Comments
We redesigned our GitHub PR comments to deliver clear, actionable security insights without adding noise to your workflow.
By André Staltz - Apr 10, 2025

![]()
![]()
![]()
![]()
![]()
Democritus functions[1] for working with Python strings.
[1] Democritus functions are simple, effective, modular, well-tested, and well-documented Python functions.
We use d8s (pronounced "dee-eights") as an abbreviation for democritus (you can read more about this here).
pip install d8s-strings
You import the library like:
from d8s_strings import *
Once imported, you can use any of the functions listed below.
def string_chars_at_start(string: str, chars: Iterable) -> Iterable[str]:
"""."""
def string_chars_at_start_len(string: str, chars: Iterable) -> int:
"""."""
def a10n(string: str) -> str:
"""."""
def string_remove_index(string: str, index: int) -> str:
"""Remove the item from the string at the given index."""
def string_replace_index(string: str, index: int, replacement: str) -> str:
"""Replace the character in the string at the given index with the replacement."""
def string_remove_before(string: str, stop_string: str):
"""Remove everything from the start of the given string until the stop_string."""
def string_remove_after(string: str, start_string: str):
"""Remove everything after the start_string to the end of the given string."""
def string_is_palindrome(string: str) -> bool:
"""Return whether or not the given string is a palindrome."""
def string_reverse(string: str) -> str:
"""Reverse the given string."""
def indefinite_article(word):
"""Return the word with the appropriate indefinite article."""
def is_plural(possible_plural: str) -> bool:
"""Return whether or not the possible_plural is plural."""
def pluralize(word: str) -> str:
"""Make the word plural."""
def is_singular(possible_singular: str) -> bool:
"""Return whether or not the possible_singular is singular."""
def singularize(word: str) -> str:
"""Make the word singular."""
def cardinalize(word: str, count: int) -> str:
"""Return the appropriate form of the given word for the count."""
def ordinalize(number: int) -> str:
"""Return the appropriate form for the ordinal form of the given number."""
def string_forms(text):
"""Return multiple forms for the given text."""
def string_left_pad(string, length: int, *, padding_characters=' '):
"""Pad the given string with the given padding_characters such that the length of the resulting string is equal to the `length` argument. Adapted from the javascript code here: https://www.theregister.co.uk/2016/03/23/npm_left_pad_chaos/."""
def string_to_bool(string: str) -> bool:
"""."""
def text_examples(n=10):
"""Create n example texts."""
def string_has_multiple_consecutive_spaces(string):
"""Return True if the given string has multiple, consecutive spaces."""
def character_examples(n=10):
"""Create n example characters."""
def text_abbreviate(text):
"""Abbreviate the given text."""
def text_input_is_yes(message):
"""Get yes/no input from the user and return `True` if the input is yes and `False` if the input is no."""
def text_input_is_no(message):
"""Get yes/no input from the user and return `True` if the input is no and `False` if the input is yes."""
def string_is_yes(string):
"""Check if a string is some form of `y` or `yes`."""
def string_is_no(string):
"""Check if a string is some form of `n` or `no`."""
def xor(message, key):
"""."""
def text_join(join_character, *args):
"""Join all of the arguments around the given join_character."""
def string_insert(existing_string, new_string, index):
"""Insert the new_string into the existing_string at the given index."""
def base64_encode(input_string):
"""Base64 encode the string."""
def base64_decode(input_string):
"""Base64 decode the string."""
def string_sequence_matcher(string_a, string_b):
"""Create a difflib.SequenceMatcher for the given string."""
def strings_diff(string_a, string_b):
"""Return the diff of the two strings."""
def string_add_to_start_of_each_line(string: str, string_to_add_to_each_line: str):
"""Add the given string_to_add_to_each_line to the beginning of each line in the string."""
def string_get_closes_matches(word, possible_matches, maximum_matches=3, cutoff=0.6):
"""Return the words from the list of possible matches that are closest to the given word."""
def strings_similarity(a: str, b: str):
"""Return the ratio of similarity between the two strings."""
def strings_matching_blocks(a: str, b: str):
"""Return the matching blocks in the given strings."""
def strings_longest_matching_block(a: str, b: str):
"""Return the longest matching block in the string."""
def strings_diff_opcodes(a: str, b: str):
"""Return the opcodes representing the differences/similarities between two strings."""
def string_common_prefix(a: str, b: str) -> str:
"""Returns the common prefix string from left to right between a and b."""
def string_common_suffix(a: str, b: str):
"""Returns the common suffix string from left to right between a and b."""
def characters(input_string):
"""Return all of the characters in the given string."""
def hex_to_string(hex_string):
"""Convert the given hex string to ascii."""
def string_to_hex(ascii_string: str, seperator='') -> str:
"""Convert the given ascii string to hex."""
def character_to_unicode_number(character):
"""Convert the given character to its Unicode number. This is the same as the `ord` function in python."""
def unicode_number_to_character(unicode_number):
"""Convert the given unicode_number to it's unicode character form. This is the same as the `chr` function in python."""
def hamming_distance(string_1, string_2, as_percent=False):
"""Return the number of positions at which corresponding symbols in string_1 and string_2 are different (this is known as the Hamming Distance). See https://en.wikipedia.org/wiki/Hamming_distance."""
def from_char_code(integer_list):
"""."""
def text_ascii_characters(text: str) -> Tuple[str]:
"""."""
def text_non_ascii_characters(text: str) -> Tuple[str]:
"""."""
def letter_as_number(letter):
"""."""
def letter_frequency(letter, text):
"""Find the frequency of the given letter in the given text."""
def string_entropy(text, ignore_case=False):
"""Find the shannon entropy of the text. Inspired by the algorithm here https://web.archive.org/web/20160320142455/https://deadhacker.com/2007/05/13/finding-entropy-in-binary-files/. You can see more here: https://en.wikipedia.org/wiki/Entropy_(information_theory)"""
def substrings(iterable):
"""Find all substrings in the given string."""
def string_remove_non_alphabetic_characters(string: str):
"""."""
def string_remove_non_numeric_characters(string: str):
"""."""
def string_remove_non_alpha_numeric_characters(string: str):
"""."""
def string_remove(regex_pattern, input_string, **kwargs):
"""Remove the regex_pattern from the input_string."""
def string_remove_unicode(string: str):
"""Remove all Unicode characters from the given string."""
def string_remove_numbers(input_string: str, replacement: str = ' '):
"""Remove all numbers from the input_strings."""
def string_remove_from_start(input_string, string_to_remove):
"""Remove the string_to_remove from the start of the input_string."""
def string_remove_from_end(input_string, string_to_remove):
"""Remove the string_to_remove from the end of the input_string."""
def string_as_numbers(input_string: str):
"""."""
def string_in_iterable_fuzzy(input_string, iterable):
"""Find if the given input_string is in one of the strings in an iterable."""
def string_find_between(input_string: str, start_string: str, end_string: str, *args):
"""Find the string in the input_string that is between the start_string and the end_string."""
def switch(a, b, text):
"""Switch a and b in the text."""
def string_encode_as_bytes(input_string, encoding='utf-8', **kwargs):
"""."""
def bytes_decode_as_string(bytes_text, encoding='utf-8', **kwargs):
"""."""
def string_shorten(input_string, length, suffix='...'):
"""Shorten the given input_string to the given length."""
def string_split_without_empty(input_string, split_char):
"""Split a input_string on split_char and remove empty entries."""
def string_has_index(string: str, index: Union[str, int]) -> bool:
"""."""
def string_split_on_uppercase(input_string: str, include_uppercase_characters=False, split_acronyms=True):
"""Split the input_string on uppercase characters. If split_acronyms is False, the function will not split consecutive uppercase letters."""
def string_split_on_lowercase(input_string, include_lowercase_characters=False):
"""Split the string on lowercase characters."""
def string_split_multiple(string, *splitting_characters):
"""Split a string up based on multiple splitting_characters."""
def string_reverse_case(input_string):
"""Make lowercase characters uppercased and visa-versa."""
def text_vowels(text):
"""Return all of the vowels in the text."""
def text_vowel_count(text):
"""Count the number of vowels in the text."""
def text_consonants(text):
"""Return all of the consonants in the text."""
def text_consonant_count(text):
"""Count the number of consonants in the text."""
def text_input(message='Enter/Paste your content.'):
"""."""
def text_ensure_starts_with(text: str, prefix: str):
"""Make sure the given text starts with the given prefix."""
def text_ensure_ends_with(text: str, suffix: str):
"""Make sure the given text ends with the given suffix."""
def titlecase(item):
"""."""
def uppercase(item):
"""."""
def uppercase_first_letter(text):
"""Make the first letter of the text uppercase."""
def lowercase_first_letter(text):
"""Make the first letter of the text lowercase."""
def crazycase(text):
"""Make the case of the characters in the given text pseudo-random"""
def kebab_case(text):
"""Return the text with a "-" in place of every space."""
def snake_case(text):
"""Return the text with a "_" in place of every space."""
def camel_case(text: str):
"""Return the text with no spaces and every word (except the first one) capitalized."""
def pascal_case(text: str):
"""Return the text with no spaces and every word capitalized."""
def sentence_case(text: str):
"""."""
def uppercase_count(text):
"""Count the number of uppercase letters in the given text."""
def lowercase_count(text):
"""Count the number of lowercase letters in the given text."""
def lowercase(item):
"""."""
def string_rotate(text, rot=13):
"""Return the text converted using a Caesar cipher (https://en.wikipedia.org/wiki/Caesar_cipher) in which the text is rotated by the given amount (using the `rot` argument)."""
def text_is_english_sentence(text: str) -> bool:
"""Determine whether or not the sentence is likely English."""
def leet_speak_to_text(leet_speak_text):
"""."""
def text_to_leet_speak(text):
"""."""
def unicode_to_ascii(text: str):
"""Convert the text to ascii."""
👋 If you want to get involved in this project, we have some short, helpful guides below:
If you have any questions or there is anything we did not cover, please raise an issue and we'll be happy to help.
This package was created with Cookiecutter and Floyd Hightower's Python project template.
FAQs
Democritus functions for working with Python strings.
We found that d8s-strings demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
We redesigned our GitHub PR comments to deliver clear, actionable security insights without adding noise to your workflow.
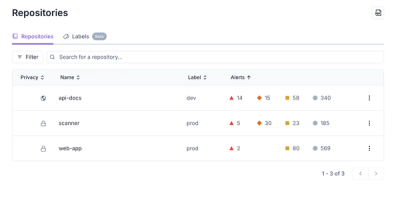
Product
Our redesigned Repositories page adds alert severity, filtering, and tabs for faster triage and clearer insights across all your projects.

Security News
Slopsquatting is a new supply chain threat where AI-assisted code generators recommend hallucinated packages that attackers register and weaponize.