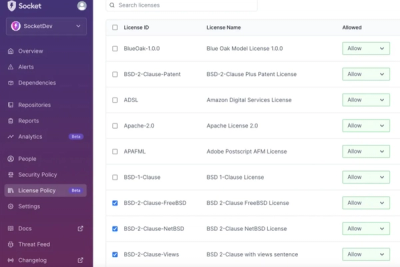
Product
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
dataskemaData schema validation for python
v1.7.3
Including flask_form and Form names in package init.py
v1.7.2
Annotation @dataskema.flask_query supports Form/POST parameters
New annotation @dataskema.flask_form to validate Form/POST parameters
New dataschema object Form to map incoming form data
v1.7.1
Message with wrong formatting fixed
v1.7.0
Now dict fields can have its own schema using 'schema' keyword
Use 'only-schema-keys' keyword to reject no declareted fields
New 'null-when-zero' keyword that rewrites incoming value to None value when zero (number or string)
Some minor bugs fixed
v1.6.7
v1.6.6
v1.6.5
v1.6.4
v1.6.3
dataskema)dataskemaFirst, define your own data schema using dataskema default data types (dataskema.data_types.py) or using your own data types. For example (mydatatypes.py):
from dataskema.data_types import DataTypes as t
class MyDataTypes(t):
address = t.type(t.title, {
'label': 'Address',
'regexp': '^[a-zA-Z0-9\\.\\@\\+\\-\\_]+$',
})
phone_number = t.str({
'max-size: 20,
'regexp': '^[0-9\\-]+]+$',
})
...
Now, import your data schema and use it with dataskema validation decorators. Look that t.name is inherited from default data types of dataskema.data_types.DataTypes class. Default data types are methods that creates default types permitting add more properties, but you can use as it is. The @dataskema.args decorator validate method arguments. Look how use it.
Import dataskema package and our data types python file:
import dataskeme
from mydatatypes import MyDataTypes as t
Print validated contact data:
@dataskeme.args(name=t.name(), address=t.address, phone_number=t.phone_number)
def print_contact_data(name: str, address: str, phone_numer: str):
print(f"Name: {name}"
print(f"Address: {address}"
print(f"Phone number: {phone_number}"
Pass contact data for validate and print:
def service_print_contact():
name = 'Lorenzo'
addresss = 'C/ Costa Rica, 32'
phone_number = '999-845-321'
try:
print_contact_data(name, address, phone_number)
except SchemaValidationResult as res:
print(res.get_message())
3) In the above example, before printing contact data, it is validated with own data schema. If the data are correct, no error will be shown. But if we modify mydatatypes.py to force a validation error, then:
phone_number = t.str({
'max-size: 20,
'regexp': '^[0-9]+$',
})
...
Now, we are not permitting phone numbers with minus symbols. The error will be:
'phone_number' has an invalid format
4) We can specify label for this paramente to show a better message:
phone_number = t.str({
'label': 'Phone number',
'max-size: 20,
'regexp': '^[0-9]+$',
})
...
The error will be:
'Phone number' has an invalid format
5) We can specify our own format error message too:
phone_number = t.str({
'label': 'Phone number',
'max-size: 20,
'regexp': '^[0-9]+$',
'message': '{name} has an invalid phone number format'
})
...
The error will be:
'Phone number' has an invalid phone number format
6) Other test: Empty name value and change name type as mandatory using inline type change. Look t.mandatory() method in the decorator:
@dataskeme.args(name=t.mandatory(t.name()), address=t.address, phone_number=t.phone_number)
def print_contact_data(name: str, address: str, phone_numer: str):
...
The error will be:
'name' is mandatory
...and 1 error more
7) Want you see all errors? Change dataskeme.MAX_VALIDATION_MESSAGES = 10 to see the 10 first validation messages o dataskeme.MAX_VALIDATION_MESSAGES = 0 to see all
'name' is mandatory
'Phone number' has an invalid phone number format
8) Now, 'name' is a field name it is not a known name. Then, use t.label() to assign a new label o modify your data scheme to assign a label to this type.
@dataskeme.args(name=t.label(t.mandatory(t.name()), 'Contact name'), address=t.address, phone_number=t.phone_number)
def print_contact_data(name: str, address: str, phone_numer: str):
...
or create data type directly in your data schema. It's really better:
In mydatatypes.py:
contact_name = t.name({
'label': 'Contact name',
'required': True,
})
...
In my test file:
@dataskeme.args(name=t.contact_name, address=t.address, phone_number=t.phone_number)
def print_contact_data(name: str, address: str, phone_numer: str):
...
This will show the next error:
'Contact name' is mandatory
'Phone number' has an invalid phone number format
9) "Well, but I want to show errors in each formulary field. Is this possible?" Yes, it is. Validation exception (SchemaValidationResult) has a method to return validation info by field: get_result_of(field_name). This method returns this data structure by each field:
{
'valid': <boolean to indicate if this field was validated with positive result or not>
'message': <validation message only if valid=False>
'label': <label assigned to field only if valid=False>
}
The method get_results() returns all validation results in a dict whose keys are the field names. The method get_message() returns all validation messages. In own example, the returning would be:
get_results():
{
'name': {
'valid': False,
'message': 'It is mandatory',
'label': 'Contact name'
},
'address': {
'valid': True
},
'phone_number': {
'valid': False,
'message': 'It has an invalid phone number format',
'label': 'Phone number'
},
}
get_message():
"'Contact name' is mandator\n'Phone number' has an invalid phone number format",
10) dataskema supports Spanish and English messages. Use dataskema.lang.DEFAULT = dataskema.lang.ES to show Spanish language. You can specify your own format error messages and your own labels in multilanguage. Look this example:
from dataskema.lang import ES, EN
phone_number = t.str({
'label': {
ES: 'Teléfono',
EN: 'Phone number',
},
'max-size: 20,
'regexp': '^[0-9]+$',
'message': {
ES: '{name} es un número teléfono no válido',
EN: '{name} has an invalid phone number format',
})
...
You can use any language using this definition way. ES and EN are strings 'es' and 'es' respectively. You can use another languages:
FR = 'fr'
phone_number = t.str({
'label': {
ES: 'Teléfono',
EN: 'Phone number',
FR: 'Téléphone',
},
'max-size: 20,
'regexp': '^[0-9]+$',
'message': {
ES: '{name} es un número teléfono no válido',
EN: '{name} has an invalid phone number format',
FR: '{name} c'est un numéro de téléphone invalide',
})
...
11) "Fine, but solution that I search is for Flask endpoints and its incoming parameters". No problem, dataskema is the solution. For example, look that Flask endpoint. Look that user_id parameter passed as argument for the next method.
@flask_app.route('/api/user/<user_id>', methods=['PUT'])
def update_user(user_id: str):
json_data = request.get_json()
...
This example not validate user_id neither json_data. Now, we will use our decorators and our data schema (mydatatypes.py). Look as update_user method includes the json params that we need us. This params are defined by above decorator flask_json. If the incoming params not validate then a SchemaValidationResult will be raised. Look how user_id is validated with arg decorator.
@flask_app.route('/api/user/<user_id>', methods=['PUT'])
@dataskema.args(user_id=t.user_id)
@dataskema.flask_json(name=t.contact_name, address.t.address, phone_number=t.phone_number)
def update_user(user_id: str, name: str, address: str, phone_number: str):
...
14) "But, What happes if my GET method not contains JSON data because the data is in the query string?" Easy. Use flask_query decorator in the same way.
@flask_app.route('/api/user/<user_id>', methods=['GET'])
@dataskema.args(user_id=t.user_id)
@dataskema.flask_query(name=t.contact_name, address.t.address, phone_number=t.phone_number)
def update_user(user_id: str, name: str, address: str, phone_number: str):
...
15) "And now, how catch the decorator exception to process validation result?" Use your own decorator (for example, @my_json_result) to catch this result and response with JSON data as this example is shown:
@flask_app.route('/api/user/<user_id>', methods=['PUT'])
@my_json_result()
@dataskema.args(user_id=t.user_id)
@dataskema.flask_json(name=t.name, address.t.address, phone_number=t.phone_number)
def update_user(user_id: str, name: str, address: str, phone_number: str):
...
The code of @my_json_result could be something as this:
def my_json_result():
def inner_function(function):
@functools.wraps(function)
def wrapper(*args, **kwargs):
try:
return function(*args, **kwargs)
except SchemaValidationResult as ve:
return {
'result': 'ERR',
'reason': ve.get_message(),
'errors': ve.get_results()
}
return wrapper
return inner_function
15) "All of this is bored for me. I hate decorators". Well, if you want to use the code for validate parameters in the traditional way, look this examples:
@flask_app.route('/api/user/<user_id>', methods=['PUT'])
def update_user(user_id):
try:
args_validator = Args({'user_id': user_id})
args_validator.validate({'user_id': t.user_id})
json_validator = JSON() # --> load JSON data: name, address & phone_number
json_validator.validate({'name': t.name, 'address': t.address, 'phone_number': t.phone_number})
return {result: 'OK'}
raise SchemaValidatorResult as ex:
error_msg = ex.get_message()
errors = ex.get_result()
return {result: 'ERR', reason: error_msg, errors: errors}
It's really worse, less elegant and too much bored code...
You can define your struct data types with some of that keywords.
That keywords are for all types:
'type': <keyword>Type of data. Possible types are: 'int', 'float', 'str', 'bool', 'list', 'dict', 'date', 'time', 'datetime', 'any'.
If the data value cannot cast with the defined type then a format error message will be raised. This default message could be overriden using the message keyword. By default, the type will be str. If default keyword is defined, the default value type will be the type of this default value especified.
'default': <any>Default value for the data when it is not passed.
'mandatory': <bool>The data must be mandatory. If type=str the data will be empty if only had blank characters.
'message': <str> or <dict>Override the default message for format errors. You can to use {name} to specify the data name. If you want to specify some languages, you can use a dict with the keys EN or ES for english or spanish languages respectively.
'label': <str>By default, the data name is the incoming paramenter name. You can overwrite using this keyword for better understanding.
'cast': <schema>Cast to other type using the same definition schema of types
'type': 'str'Keywords only for type specified as 'str' are:
'white-list': [...]list of valid values for the data
'icase': <bool>ignore case for matching the white-list
'regexp': <str>Regular expression to match de data value. The default format error message could be overriden using the message keyword.
'min-size': <int>Limit the minimum number of characters for the data. Valid for 'str', 'int' and 'float' types
'max-size': <int>Limit the maximum number of characters for the data. Valid for 'str', 'int' and 'float' types
'max-lines': <int>Limit the maximum number of lines for the data. Valid for 'str' types
'to': <keywords>Tranformation string functions. Several functions can be applied separating them by commas. Possible values are:
'upper': Convert string to uppercase.'lower': Convert string to lowercase.'no-trim': No trim the string. By default, all strings are trimmed by both sides.'trim': Force trim (by default)'format': <str>Format output string using format python string method. If input object is a date, time o datetime then this format must be a valid date, time o datetime format. If input object is an int or float then this format must be a valid number format.
'join': <str>If input data es a list, join items as a string list with the 'join' separator between items.
'type': 'int' or 'float'Keywords only for type specified as 'int' or 'float' are:
'min-value': <int>Limit the minimum value for the data.
'max-value': <int>Limit the maximum value for the data.
'type': 'list'Keywords only for type specified as 'list' are:
'schema': <dict>Schema of data for list items. This data schema must be validated for each item list. The schema format is the same of this schema and use the same keyword and constraints.
'iempty': <bool>Ignore empty list item. Por defecto es True
'iduplicated': <bool>Ignore duplicated list items. Por defecto es True
'type': 'date', 'time' or 'datetime'Keywords only for types specified as 'date', 'time' or 'datetime' are:
'format': <str>Format to parse string date, time or datetime in an object correctly
'type': 'dict'Keywords only for type specified as 'dict' are:
'schema': <dict>Schema of data for dict items. Collection of keys that matches with incoming keys of dict parameter. Each key schema define the schema of its value
'type': 'bool' or 'any'That types have no specific keywords:
That are the default data types defined by dataskema by the class DataTypes in data_types.py file. It's very illustrative as an example because create default methods that define types permitting extends its properties with more keywords:
The class DataTypes define static methods to ease add keywords in a default type without modify the type. That methods are:
label(type, label): include a label for the typedefault(type, default_value): include a default value for the typeupper(type): force incoming value to be uppercaselower(type): force incoming value to be lowercasemandatory(type): the value must be mandatorytype(type, newtype): One way to redefine inline a complex type. Useful for define our own data types using DataTypes classstr(extended_properties): Define a 'type': 'str' permitting extends more keywords.int(extended_properties): Define a 'type': 'int' permitting extends more keywords.float(extended_properties): Define a 'type': 'float' permitting extends more keywords.bool(extended_properties): Define a 'type': 'bool' permitting extends more keywords.list(extended_properties): Define a 'type': 'list' permitting extends more keywords.dict(extended_properties): Define a 'type': 'dict' permitting extends more keywords.date(extended_properties): Define a 'type': 'date' permitting extends more keywords.time(extended_properties): Define a 'type': 'time' permitting extends more keywords.datetime(extended_properties): Define a 'type': 'datetime' permitting extends more keywords.str_list(schema, extended_properties): Define a 'type': 'str' as string item list comma-separatedwhite_list(list, extended_properties): Define a 'type': 'str' including a white-list and more keywords.positive(extended_properties): Define a 'type': 'int' including its constraints for be a positive number.zero_positive(extended_properties): Define a 'type': 'int' including its constraints for be a zero o positive number.negative(extended_properties): Define a 'type': 'int' including its constraints for be a negative number.url(extended_properties): Define a 'type': 'str' including its constraints for url format.email(extended_properties): Define a 'type': 'str' including its constraints for email format.password(extended_properties): Define a 'type': 'str' including its constraints for passworddecimal(extended_properties): Define a 'type': 'str' including its constraints for a decimal format.hexadecimal(extended_properties): Define a 'type': 'str' including its constraints for hexadecimal format.base64(extended_properties): Define a 'type': 'str' including its constraints for base64 format.alfanumeric(extended_properties): Define a 'type': 'str' including its constraints only for alfanumeric characters.short_id(extended_properties): Define a 'type': 'str' with 'max-size': 20.long_id(extended_properties): Define a 'type': 'str' with 'max-size': 40.name(extended_properties): Define a 'type': 'str' with 'max-size': 100.title(extended_properties): Define a 'type': 'str' with 'max-size': 200.summary(extended_properties): Define a 'type': 'str' with 'max-size': 2000.text(extended_properties): Define a 'type': 'str' with 'max-size': 500000 and 'max-lines': 10000.version(extended_properties): Define a 'type': 'str' with a valid version format.search(extended_properties): Define a 'type': 'str' for search strings.Examples:
Importing dataskema.data_types.DataTypes as t:
t.name() is not a mandatory type but t.mandatory(t.name()), yes
t.name() name by default will be 'name' but t.label(t.name(),'Contact') will be named 'Contact'
For define own our types in a custom class:
from dataskema.data_types import DataTypes as t
class MyDataTypes(t):
contact_name = t.mandatory(t.label(t.name, 'Contact'))
contact_email = t.label(t.email(), 'Contact e-mail')
address = t.label(t.title(), 'Address')
postal_code = t.numeric({
'label': 'Postal code'
'mandatory': true,
'min-size': 5,
'max-size': 5,
})
contact = t.dict({
'label': 'Contact info',
'schema': {
'contact_name': t.contact_name,
'contact_email': t.contact_email,
'address': t.address,
'postal_code': t.postal_code,
}
})
...
FAQs
Data schema to validate parameters easily, quickly and with minimal code
We found that dataskema demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
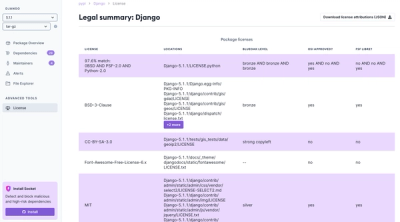
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
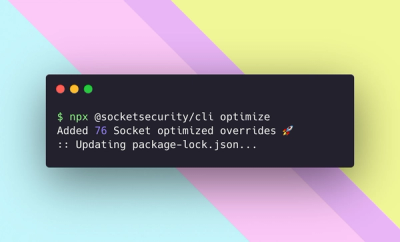
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.