====
ELI5
.. image:: https://img.shields.io/pypi/v/eli5.svg
:target: https://pypi.python.org/pypi/eli5
:alt: PyPI Version
.. image:: https://github.com/eli5-org/eli5/actions/workflows/python-package.yml/badge.svg?branch=master
:target: https://github.com/eli5-org/eli5/actions
:alt: Build Status
.. image:: https://codecov.io/github/TeamHG-Memex/eli5/coverage.svg?branch=master
:target: https://codecov.io/github/TeamHG-Memex/eli5?branch=master
:alt: Code Coverage
.. image:: https://readthedocs.org/projects/eli5/badge/?version=latest
:target: https://eli5.readthedocs.io/en/latest/?badge=latest
:alt: Documentation
ELI5 is a Python package which helps to debug machine learning
classifiers and explain their predictions.
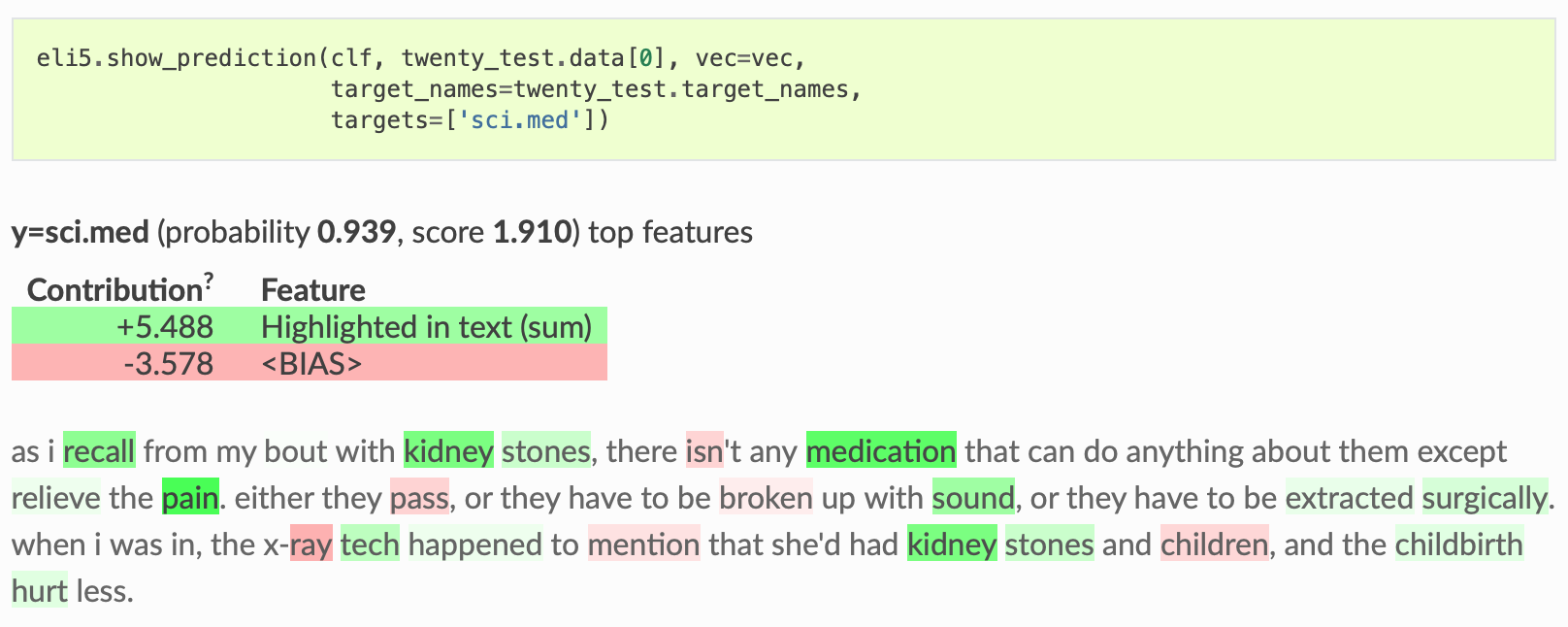
.. image:: https://raw.githubusercontent.com/eli5-org/eli5/refs/heads/master/docs/source/static/readme-show-prediction.png
:alt: explain_prediction for text data
.. image:: https://raw.githubusercontent.com/eli5-org/eli5/refs/heads/master/docs/source/static/gradcam-catdog.png
:alt: explain_prediction for image data
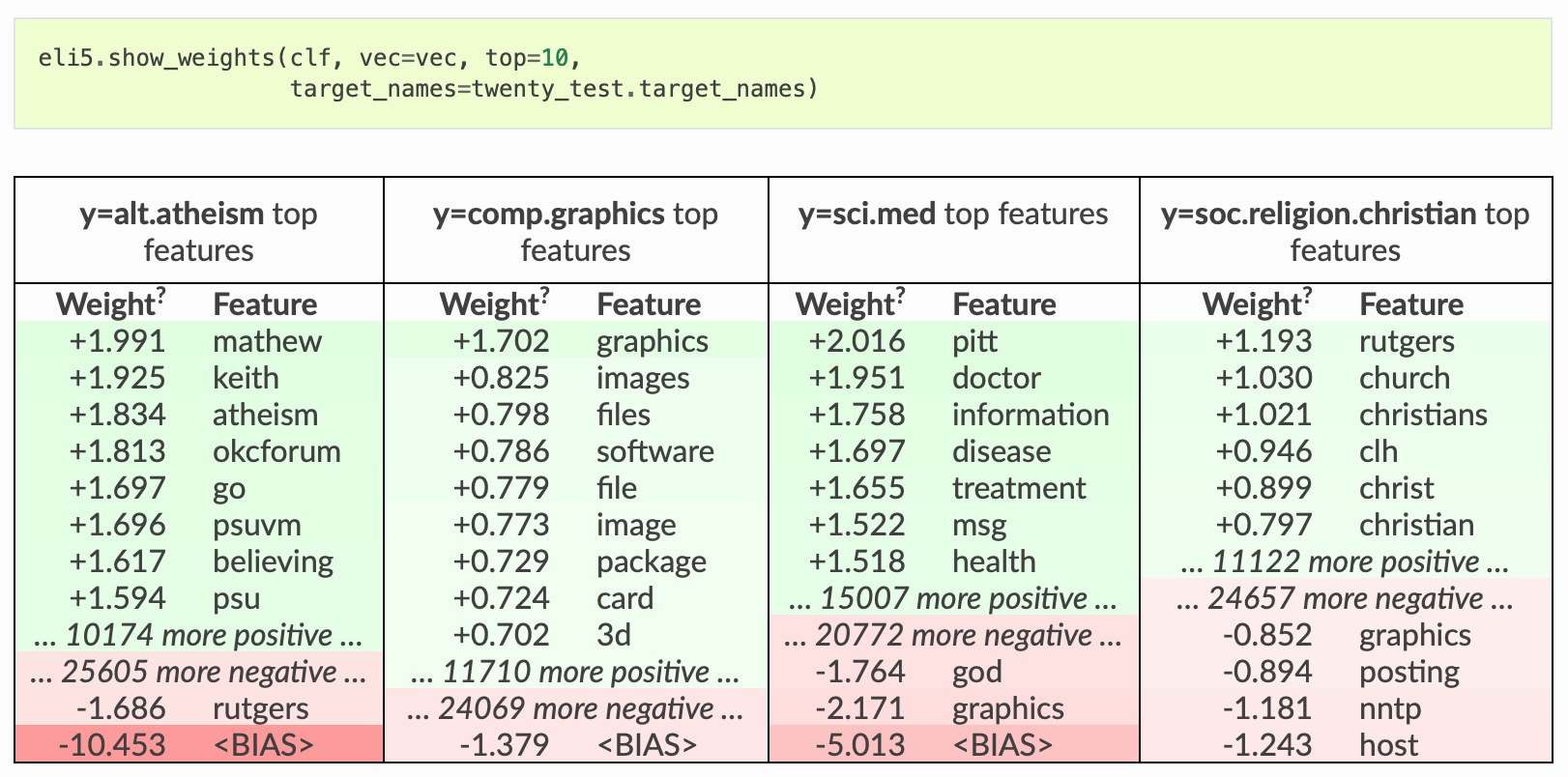
.. image:: https://raw.githubusercontent.com/eli5-org/eli5/refs/heads/master/docs/source/static/readme-show-weights.png
:alt: explain_weights for text data
It provides support for the following machine learning frameworks and packages:
-
scikit-learn_. Currently ELI5 allows to explain weights and predictions
of scikit-learn linear classifiers and regressors, print decision trees
as text or as SVG, show feature importances and explain predictions
of decision trees and tree-based ensembles. ELI5 understands text
processing utilities from scikit-learn and can highlight text data
accordingly. Pipeline and FeatureUnion are supported.
It also allows to debug scikit-learn pipelines which contain
HashingVectorizer, by undoing hashing.
-
Keras_ - explain predictions of image classifiers via Grad-CAM visualizations.
-
xgboost_ - show feature importances and explain predictions of XGBClassifier,
XGBRegressor and xgboost.Booster.
-
LightGBM_ - show feature importances and explain predictions of
LGBMClassifier, LGBMRegressor and lightgbm.Booster.
-
CatBoost_ - show feature importances of CatBoostClassifier,
CatBoostRegressor and catboost.CatBoost.
-
lightning_ - explain weights and predictions of lightning classifiers and
regressors.
-
sklearn-crfsuite_. ELI5 allows to check weights of sklearn_crfsuite.CRF
models.
-
OpenAI_ python client. ELI5 allows to explain LLM predictions with token probabilities.
ELI5 also implements several algorithms for inspecting black-box models
(see Inspecting Black-Box Estimators_):
- TextExplainer_ allows to explain predictions
of any text classifier using LIME_ algorithm (Ribeiro et al., 2016).
There are utilities for using LIME with non-text data and arbitrary black-box
classifiers as well, but this feature is currently experimental.
Permutation importance_ method can be used to compute feature importances
for black box estimators.
Explanation and formatting are separated; you can get text-based explanation
to display in console, HTML version embeddable in an IPython notebook
or web dashboards, a pandas.DataFrame object if you want to process
results further, or JSON version which allows to implement custom rendering
and formatting on a client.
.. _lightning: https://github.com/scikit-learn-contrib/lightning
.. _scikit-learn: https://github.com/scikit-learn/scikit-learn
.. _sklearn-crfsuite: https://github.com/scrapinghub/sklearn-crfsuite
.. _LIME: https://eli5.readthedocs.io/en/latest/blackbox/lime.html
.. _TextExplainer: https://eli5.readthedocs.io/en/latest/tutorials/black-box-text-classifiers.html
.. _xgboost: https://github.com/dmlc/xgboost
.. _LightGBM: https://github.com/Microsoft/LightGBM
.. _Catboost: https://github.com/catboost/catboost
.. _Keras: https://keras.io/
.. _Permutation importance: https://eli5.readthedocs.io/en/latest/blackbox/permutation_importance.html
.. _Inspecting Black-Box Estimators: https://eli5.readthedocs.io/en/latest/blackbox/index.html
.. _OpenAI: https://github.com/openai/openai-python
License is MIT.
Check docs <https://eli5.readthedocs.io/>_ for more.
.. note::
This project was previously developed at https://github.com/TeamHG-Memex/eli5/
with support from Hyperion Gray <https://www.hyperiongray.com>_.
Changelog
0.16.0 (2024-04-20)
- support explain_prediction with Grad-CAM for Keras 3.x, TF 2.x image classifiers
(use versions prior to 0.14 for TF 1.x support)
0.15.0 (2025-04-06)
- support explain_prediction with OpenAI client, highlighting token logprobs
0.14.0 (2025-03-26)
- add support for scikit-learn 1.6+
- drop support for python 3.6, 3.7, 3.8
- add support for python 3.11, 3.12, 3.13
0.13.0 (2022-05-11)
- drop python2.7 support
- fix newer xgboost with unnamed features
0.12.0 (2022-05-11)
- use Jinja2 >= 3.0.0, please use eli5 0.11 if you'd prefer to use
an older version of Jinja2
- support lightgbm.Booster
0.11.0 (2021-01-23)
- fixed scikit-learn 0.22+ and 0.24+ support.
- allow nan inputs in permutation importance (if model supports them).
- fix for permutation importance with sample_weight and cross-validation.
- doc fixes (typos, keras and TF versions clarified).
- don't use deprecated getargspec function.
- less type ignores, mypy updated to 0.750.
- python 3.8 and 3.9 tested on GI, python 3.4 not tested any more.
- tests moved to github actions.
0.10.1 (2019-08-29)
- Don't include typing dependency on Python 3.5+
to fix installation on Python 3.7
0.10.0 (2019-08-21)
- Keras image classifiers: explaining predictions with Grad-CAM
(GSoC-2019 project by @teabolt).
0.9.0 (2019-07-05)
- CatBoost support: show feature importances of CatBoostClassifier,
CatBoostRegressor and catboost.CatBoost.
- Test fixes: fixes for scikit-learn 0.21+, use xenial base on Travis
- Catch exceptions from improperly installed LightGBM
0.8.2 (2019-04-04)
- fixed scikit-learn 0.21+ support (randomized linear models are removed
from scikit-learn);
- fixed pandas.DataFrame + xgboost support for PermutationImportance;
- fixed tests with recent numpy;
- added conda install instructions (conda package is maintained by community);
- tutorial is updated to use xgboost 0.81;
- update docs to use pandoc 2.x.
0.8.1 (2018-11-19)
- fixed Python 3.7 support;
- added support for XGBoost > 0.6a2;
- fixed deprecation warnings in numpy >= 1.14;
- documentation, type annotation and test improvements.
0.8 (2017-08-25)
- backwards incompatible: DataFrame objects with explanations no longer
use indexes and pivot tables, they are now just plain DataFrames;
- new method for inspection black-box models is added
(
eli5-permutation-importance);
- transfor_feature_names is implemented for sklearn's MinMaxScaler,
StandardScaler, MaxAbsScaler and RobustScaler;
- zero and negative feature importances are no longer hidden;
- fixed compatibility with scikit-learn 0.19;
- fixed compatibility with LightGBM master (2.0.5 and 2.0.6 are still
unsupported - there are bugs in LightGBM);
- documentation, testing and type annotation improvements.
0.7 (2017-07-03)
- better pandas.DataFrame integration:
eli5.explain_weights_df,
eli5.explain_weights_dfs, eli5.explain_prediction_df,
eli5.explain_prediction_dfs,
eli5.format_as_dataframe <eli5.formatters.as_dataframe.format_as_dataframe>
and eli5.format_as_dataframes <eli5.formatters.as_dataframe.format_as_dataframes>
functions allow to export explanations to pandas.DataFrames;
eli5.explain_prediction now shows predicted class for binary
classifiers (previously it was always showing positive class);eli5.explain_prediction supports targets=[<class>] now
for binary classifiers; e.g. to show result as seen for negative class,
you can use eli5.explain_prediction(..., targets=[False]);- support
eli5.explain_prediction and eli5.explain_weights
for libsvm-based linear estimators from sklearn.svm: SVC(kernel='linear')
(only binary classification), NuSVC(kernel='linear') (only
binary classification), SVR(kernel='linear'), NuSVR(kernel='linear'),
OneClassSVM(kernel='linear');
- fixed
eli5.explain_weights for LightGBM_ estimators in Python 2 when
importance_type is 'split' or 'weight';
- testing improvements.
0.6.4 (2017-06-22)
- Fixed
eli5.explain_prediction for recent LightGBM_ versions;
- fixed Python 3 deprecation warning in formatters.html;
- testing improvements.
0.6.3 (2017-06-02)
eli5.explain_weights and eli5.explain_prediction
works with xgboost.Booster, not only with sklearn-like APIs;eli5.formatters.as_dict.format_as_dict is now available as
eli5.format_as_dict;- testing and documentation fixes.
0.6.2 (2017-05-17)
- readable
eli5.explain_weights for XGBoost models trained on
pandas.DataFrame;
- readable
eli5.explain_weights for LightGBM models trained on
pandas.DataFrame;
- fixed an issue with
eli5.explain_prediction for XGBoost
models trained on pandas.DataFrame when feature names contain dots;
- testing improvements.
0.6.1 (2017-05-10)
- Better pandas support in
eli5.explain_prediction for
xgboost, sklearn, LightGBM and lightning.
0.6 (2017-05-03)
- Better scikit-learn Pipeline support in
eli5.explain_weights:
it is now possible to pass a Pipeline object directly. Curently only
SelectorMixin-based transformers, FeatureUnion and transformers
with get_feature_names are supported, but users can register other
transformers; built-in list of supported transformers will be expanded
in future. See sklearn-pipelines for more.
- Inverting of HashingVectorizer is now supported inside FeatureUnion
via
eli5.sklearn.unhashing.invert_hashing_and_fit.
See sklearn-unhashing.
- Fixed compatibility with Jupyter Notebook >= 5.0.0.
- Fixed
eli5.explain_weights for Lasso regression with a single
feature and no intercept.
- Fixed unhashing support in Python 2.x.
- Documentation and testing improvements.
0.5 (2017-04-27)
- LightGBM_ support:
eli5.explain_prediction and
eli5.explain_weights are now supported for
LGBMClassifier and LGBMRegressor
(see eli5 LightGBM support <library-lightgbm>).
- fixed text formatting if all weights are zero;
- type checks now use latest mypy;
- testing setup improvements: Travis CI now uses Ubuntu 14.04.
.. _LightGBM: https://github.com/Microsoft/LightGBM
0.4.2 (2017-03-03)
- bug fix: eli5 should remain importable if xgboost is available, but
not installed correctly.
0.4.1 (2017-01-25)
- feature contribution calculation fixed
for
eli5.xgboost.explain_prediction_xgboost
0.4 (2017-01-20)
eli5.explain_prediction: new 'top_targets' argument allows
to display only predictions with highest or lowest scores;eli5.explain_weights allows to customize the way feature importances
are computed for XGBClassifier and XGBRegressor using importance_type
argument (see docs for the eli5 XGBoost support <library-xgboost>);eli5.explain_weights uses gain for XGBClassifier and XGBRegressor
feature importances by default; this method is a better indication of
what's going, and it makes results more compatible with feature importances
displayed for scikit-learn gradient boosting methods.
0.3.1 (2017-01-16)
- packaging fix: scikit-learn is added to install_requires in setup.py.
0.3 (2017-01-13)
eli5.explain_prediction works for XGBClassifier, XGBRegressor
from XGBoost and for ExtraTreesClassifier, ExtraTreesRegressor,
GradientBoostingClassifier, GradientBoostingRegressor,
RandomForestClassifier, RandomForestRegressor, DecisionTreeClassifier
and DecisionTreeRegressor from scikit-learn.
Explanation method is based on
http://blog.datadive.net/interpreting-random-forests/ .eli5.explain_weights now supports tree-based regressors from
scikit-learn: DecisionTreeRegressor, AdaBoostRegressor,
GradientBoostingRegressor, RandomForestRegressor and ExtraTreesRegressor.eli5.explain_weights works for XGBRegressor;- new
TextExplainer <lime-tutorial> class allows to explain predictions
of black-box text classification pipelines using LIME algorithm;
many improvements in eli5.lime <eli5-lime>.
- better
sklearn.pipeline.FeatureUnion support in
eli5.explain_prediction;
- rendering performance is improved;
- a number of remaining feature importances is shown when the feature
importance table is truncated;
- styling of feature importances tables is fixed;
eli5.explain_weights and eli5.explain_prediction support
more linear estimators from scikit-learn: HuberRegressor, LarsCV, LassoCV,
LassoLars, LassoLarsCV, LassoLarsIC, OrthogonalMatchingPursuit,
OrthogonalMatchingPursuitCV, PassiveAggressiveRegressor,
RidgeClassifier, RidgeClassifierCV, TheilSenRegressor.- text-based formatting of decision trees is changed: for binary
classification trees only a probability of "true" class is printed,
not both probabilities as it was before.
eli5.explain_weights supports feature_filter in addition
to feature_re for filtering features, and eli5.explain_prediction
now also supports both of these arguments;- 'Weight' column is renamed to 'Contribution' in the output of
eli5.explain_prediction;
- new
show_feature_values=True formatter argument allows to display
input feature values;
- fixed an issue with analyzer='char_wb' highlighting at the start of the
text.
0.2 (2016-12-03)
- XGBClassifier support (from
XGBoost <https://github.com/dmlc/xgboost>__
package);
eli5.explain_weights support for sklearn OneVsRestClassifier;- std deviation of feature importances is no longer printed as zero
if it is not available.
0.1.1 (2016-11-25)
- packaging fixes: require attrs > 16.0.0, fixed README rendering
0.1 (2016-11-24)
- HTML output;
- IPython integration;
- JSON output;
- visualization of scikit-learn text vectorizers;
sklearn-crfsuite <https://github.com/TeamHG-Memex/sklearn-crfsuite>__
support;lightning <https://github.com/scikit-learn-contrib/lightning>__ support;eli5.show_weights and eli5.show_prediction functions;eli5.explain_weights and eli5.explain_prediction
functions;eli5.lime <eli5-lime> improvements: samplers for non-text data,
bug fixes, docs;- HashingVectorizer is supported for regression tasks;
- performance improvements - feature names are lazy;
- sklearn ElasticNetCV and RidgeCV support;
- it is now possible to customize formatting output - show/hide sections,
change layout;
- sklearn OneVsRestClassifier support;
- sklearn DecisionTreeClassifier visualization (text-based or svg-based);
- dropped support for scikit-learn < 0.18;
- basic mypy type annotations;
feature_re argument allows to show only a subset of features;target_names argument allows to change display names of targets/classes;targets argument allows to show a subset of targets/classes and
change their display order;- documentation, more examples.
0.0.6 (2016-10-12)
- Candidate features in eli5.sklearn.InvertableHashingVectorizer
are ordered by their frequency, first candidate is always positive.
0.0.5 (2016-09-27)
- HashingVectorizer support in explain_prediction;
- add an option to pass coefficient scaling array; it is useful
if you want to compare coefficients for features which scale or sign
is different in the input;
- bug fix: classifier weights are no longer changed by eli5 functions.
0.0.4 (2016-09-24)
- eli5.sklearn.InvertableHashingVectorizer and
eli5.sklearn.FeatureUnhasher allow to recover feature names for
pipelines which use HashingVectorizer or FeatureHasher;
- added support for scikit-learn linear regression models (ElasticNet,
Lars, Lasso, LinearRegression, LinearSVR, Ridge, SGDRegressor);
- doc and vec arguments are swapped in explain_prediction function;
vec can now be omitted if an example is already vectorized;
- fixed issue with dense feature vectors;
- all class_names arguments are renamed to target_names;
- feature name guessing is fixed for scikit-learn ensemble estimators;
- testing improvements.
0.0.3 (2016-09-21)
- support any black-box classifier using LIME (http://arxiv.org/abs/1602.04938)
algorithm; text data support is built-in;
- "vectorized" argument for sklearn.explain_prediction; it allows to pass
example which is already vectorized;
- allow to pass feature_names explicitly;
- support classifiers without get_feature_names method using auto-generated
feature names.
0.0.2 (2016-09-19)
- 'top' argument of
explain_prediction
can be a tuple (num_positive, num_negative);
- classifier name is no longer printed by default;
- added eli5.sklearn.explain_prediction to explain individual examples;
- fixed numpy warning.
0.0.1 (2016-09-15)
Pre-release.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}