

Product
Introducing Webhook Events for Alert Changes
Add real-time Socket webhook events to your workflows to automatically receive software supply chain alert changes in real time.
By Phil Gates-Idem - Nov 21, 2025
hyperway
Advanced tools
A graph based functional execution library. Connect functions arbitrarily through a unique API
![]()
![]()



A Python graph based functional execution library, with a unique API.
Hyperway is a graph based functional execution library, allowing you to connect functions arbitrarily through a unique API. Mimic a large range of programming paradigms such as procedural, parallel, or aspect-oriented-programming. Build B-trees or decision trees, circuitry or logic gates; all with a simple wiring methodology.
Hyperway has no enforced dependencies.
Install via pip:
pip install hyperway
If you want to render graphs, ensure graphviz is installed. This can be done through your own methods, or by installing the optional dependency:
pip install hyperway[graphviz]
For a quick example of the important parts, let's connect some functions and run the chain:
import hyperway
from hyperway.tools import factory as f
# Store
g = hyperway.Graph()
# Connect
first_connection = g.add(f.add_10, f.add_20)
# More connections
many_connections = g.connect(f.add_30, f.add_1, f.add_2, f.add_3)
# Cross connect
compound_connection = g.add(many_connections[1].b, f.add_3)
# Prepare to run
stepper = g.stepper(first_connection.a, 10)
# Run a step
concurrent_row = stepper.step()
Render this graph (if graphviz is installed):
g.write('intro-example', directory='renders', direction='LR')
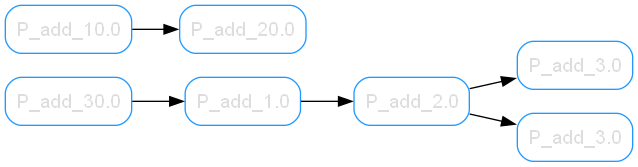
That's it! You're a graph engineer.
[!NOTE] The stepper yields rows of
(Unit, ArgsPack)tuples representing the next functions to execute. Continue callingstep()until no rows remain. Access results easily withstepper.get_result()orstepper.get_results().
Hyperway aims to simplify graph based execution chains, allowing a developer to use functional graphs without managing the connections.
[!TIP] TL;DR: The
Unit(or node) is a function connected to other nodes throughConnections. TheStepperwalks theGraphof all connections.
The Hyperway API aims to simplify standard graph-theory terminology, by providing more intuitive names for common graph components. Developers and mathematicians can extend the base library with preferred terms, without changing the core functionality:
class Vertex(Unit):
"""Alias for Unit (Node)"""
pass
Hyperway components, and their conventional siblings:
| Hyperway | Graph Theory | Description |
|---|---|---|
Graph | Graph, or Tree | A flat dictionary to hold all connections |
Unit | Node, Point, or Vertex | A function on a graph, bound through edges |
Connection | Edge, link, or Line | A connection between Units |
Stepper | Walker, or Agent | A graph walking tool |
The Graph is a fancy defaultdict of tuples, used to store connections:
import hyperway
g = hyperway.Graph()
There are a few convenience methods, such as add() and connect(), but fundamentally it's a dictionary of connections.
All Connections are stored within a single Graph instance. We can consider the graph as a dictionary register of all associated connections.
from hyperway.graph import Graph, add
from hyperway.nodes import as_units
from hyperway.tools import factory as f
g = Graph()
unit_a, unit_b = as_units(f.add_2, f.mul_2)
connection = add(g, unit_a, unit_b)
Under the hood, The graph is just a defaultdict and doesn't do much.
A Connection binds two functions (or Unit objects) together. It represents an edge between two nodes.
A connection needs a minimum of two nodes:

from hyperway.edges import make_edge
c = make_edge(f.add_1, f.add_2)
# <Connection>
We can create a connection in two ways:
The Graph has an add() method to create a connection between two functions:
import hyperway
from hyperway.tools import factory as f
g = hyperway.Graph()
connection = g.add(f.add_1, f.add_2)
# <Connection>
Alternatively we can use the make_edge function directly (without a graph):
from hyperway.edges import make_edge
from hyperway.tools import factory as f
c = make_edge(f.add_1, f.add_2)
# <Connection>
We can run a connection, calling the chain of two nodes. Generally a Connection isn't used outside a graph unless we're playing with it.
[!IMPORTANT] A
Connectionhas two processing steps due to a potential wire function. Consider usingpluck()to run both steps.
A standard call to a connection will run node a (the left side):
# connection = make_edge(f.add_1, f.add_2)
>>> value_part_a = connection(1) # call A-side `add_1`
2.0
Then process the second part b (providing the value from the first call):
>>> connection.process(value_part_a) # call B-side `add_2`
4.0
Alternatively use the pluck() method.
We can "pluck" a connection (like plucking a string) to run the functions with any arguments:
from hyperway.tools import factory as f
from hyperway.edges import make_edge
c = make_edge(f.add_1, f.add_2)
# Run side _a_ (`add_1`) and _b_ (`add_2`) with our input value.
c.pluck(1) # 4.0 == 1 + 1 + 2
c.pluck(10) # 13.0 == 10 + 1 + 2
The pluck() executes both nodes and the optional wire function, in the expected order. Fundamentally a connection is self-contained and doesn't require a parent graph.
An optional wire function exists between two nodes
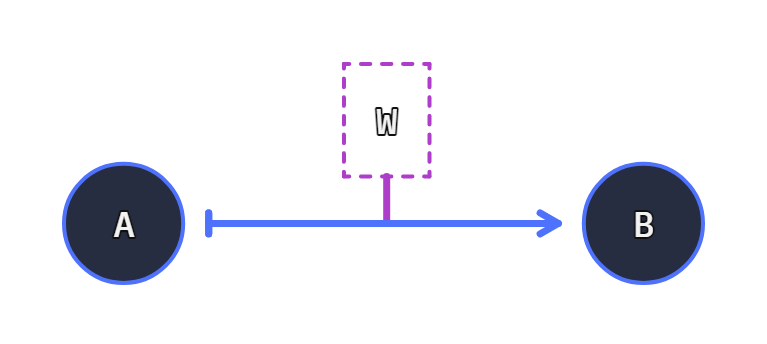
The Connection can have a function existing between its connected Units, allowing the alteration of the data through transit (whilst running through a connection):
from hyperway.tools import factory as f
from hyperway.edges import make_edge, wire
c = make_edge(f.add_1, f.add_2, through=wire(f.mul_2))
# <Connection(Unit(func=P_add_1.0), Unit(func=P_add_2.0), through="P_mul_2.0" name=None)>
When using the connection side A (the f.add_1 function), the wire function wire(f.mul_2) can inspect the values as they move to f.add_2.
It's important to note Hyperway is left-associative. The order of operation computes linearly:
assert c.pluck(1) == 6 # (1 + 1) * 2 + 2 == 6
assert c.pluck(10) == 24 # (10 + 1) * 2 + 2 == 24
It's easy to argue a wire function is a node, and you can implement the wire function without this connection tap.
Fundamentally a wire function exists for topological clarity and may be ignored.
make_edge can accept the wire function. It receives the concurrent values transmitting through the attached edge:
from hyperway.edges import make_edge
from hyperway.packer import argspack
import hyperway.tools as t
f = t.factory
def doubler(v, *a, **kw):
# The wire function `through` _doubles_ the given number.
# response with an argpack.
return argspack(v * 2, **kw)
c = make_edge(f.add_1, f.add_2, through=doubler)
# <Connection(Unit(func=P_add_1.0), Unit(func=P_add_2.0), name=None)>
c.pluck(1) # 6.0
c.pluck(2) # 8.0
c.pluck(3) # 10.0
[!IMPORTANT] Wire functions must return an
ArgsPackviaargspack(). Returning raw values will break the execution chain. See Extras forargspackdetails.
The wire function is the reason for a two-step process when executing connections:
# Call Node A: (+ 1)
c(4)
5.0
# Call Wire + B: (double then + 2)
c.process(5.0)
12.0
Or a single pluck():
c.pluck(4)
12.0
A connection A -> B may be the same node, performing a loop or self-referencing node connection.
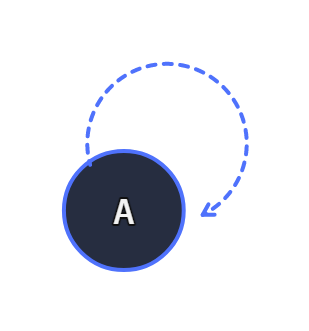
We can use the as_unit function, and reference the same unit on the graph:
# pre-define the graph node wrapper
u = as_unit(f.add_2)
# Build an loop edge
e = make_edge(u, u)
g = Graph()
g.add_edge(e)
# Setup the start from the unit (side A)
g.stepper(u, 1)
# Call the stepper forever.
g.step()
g.step()
...
# 3, 5, 7, 9, 11, ...
A function is our working code. We can borrow operator functions from the tools:
from hyperway.tools import factory as f
add_10 = f.add_10
# functools.partial(<built-in function add>, 10.0)
add_10(1)
# 11.0
add_10(14)
# 24.0
The Unit (or node) is a function connected to other nodes through a Connection. A Unit is a wrapper for any python function. Everything in the graph (and in a Connection) is a Unit.
When we create a new connection, it automatically wraps the given functions as Unit types:
c = make_edge(f.mul_3, f.add_4)
c.a
# <Unit(func=P_mul_3.0)>
c.b
# <Unit(func=P_add_4.0)>
A Unit has additional methods used by the graph tools, such as the process method:
# Call our add_4 function:
>>> c.b.process(1)
5.0
A new unit is very unique. Creating a Connection with the same function for both sides a and b, will insert two new nodes:
c = make_edge(f.add_4, f.add_4)
c.pluck(4)
12.0
We can cast a function as a Unit before insertion, allowing the re-reference to existing nodes.
Unit[!IMPORTANT] A
Unitis unique, even when using the same function:Unit(my_func)!=Unit(my_func)
If you create a Unit using the same function, this will produce two unique units:
unit_a = as_unit(f.add_2)
unit_a_2 = as_unit(f.add_2)
assert unit_a != unit_a_2 # Not the same.
Attempting to recast a Unit, will return the same Unit:
unit_a = as_unit(f.add_2)
unit_a_2 = as_unit(unit_a) # unit_a is already a Unit
assert unit_a == unit_a_2 # They are the same
With this we create a linear chain of function calls, or close a loop that will run forever.
Generally when inserting functions, a new reference is created. This allows us to use the same function at different points in a chain:
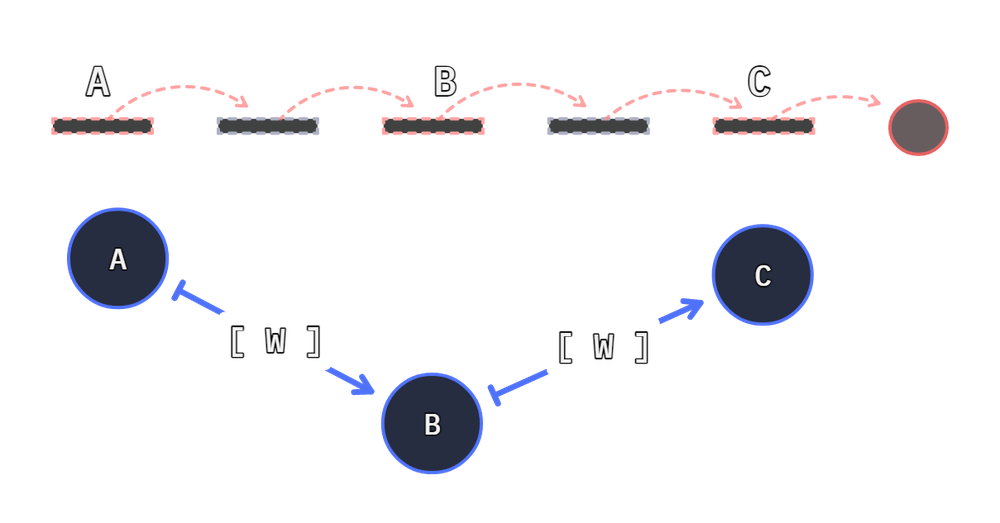
a = f.add_1
b = f.add_2
c = f.add_2
# a -> b -> c | done.
connection_1 = make_edge(a, b)
_ = make_edge(b, c)
_ = make_edge(c, a)
Closing a path produces a loop. To close a path we can reuse the same Unit at both ends of our path.
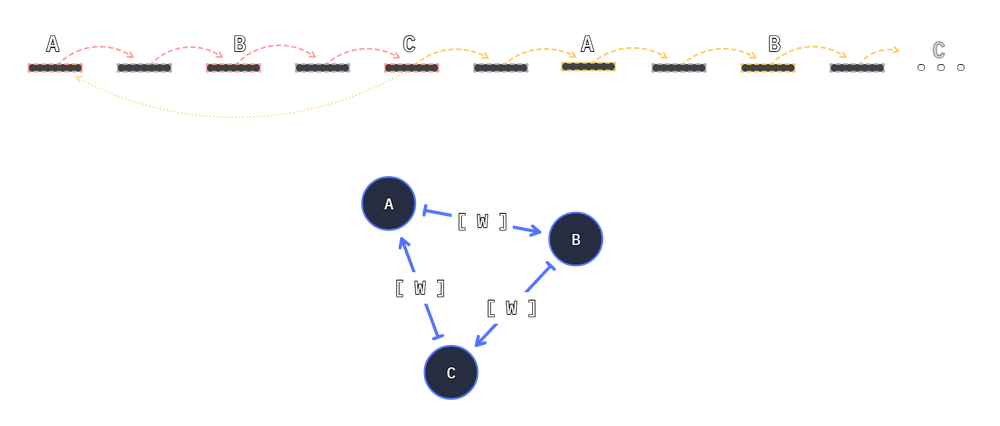
To ensure a node is reused when applied, we pre-convert it to a Unit:
a = as_unit(f.add_1) # sticky reference.
b = f.add_2
c = f.add_2
# a -> b -> c -> a ... forever
connection_1 = make_edge(a, b)
_ = make_edge(b, c)
_ = make_edge(c, a)
The Stepper run units and discovers connections through the attached Graph. It runs concurrent units and spools the next callables for the next step.
from hyperway.graph import Graph
from hyperway.tools import factory as f
g = Graph()
a_connections = g.connect(f.add_10, f.add_20, f.add_30)
b_connections = g.connect(f.add_1, f.add_2, f.add_3)
c_connection = g.add(b_connections[1].b, f.add_3)
first_connection_first_node = a_connections[0].a
stepper = g.stepper(first_connection_first_node, 10)
# <stepper.StepperC object at 0x000000000258FEB0>
concurrent_row = stepper.step()
# rows. e.g: ((<Unit(func=my_func)>, <ArgsPack(*(1,), **{})>),)
For each step() call, we yield a step. When iterating from first_connection_first_node (f.add_10), the stepper will pause half-way through our call. The next step will resolve the value and prepare the next step:
# From above:
# g.stepper(first_connection_first_node, 10)
stepper.step()
(
# Partial edge (from add_10 to add_20), with the value "20.0" (10 add 10)
(<edges.PartialConnection>, <ArgsPack(*(20.0,), **{})>),
)
stepper.step()
(
# Previous step complete; input(10), add(10), then add(20)
(<Unit(func=P_add_30.0)>, <ArgsPack(*(40.0,), **{})>),
)
We initiated a stepper at our preferred node stepper = g.stepper(first_connection_first_node, 10). Any subsequent stepper.step() calls push the stepper to the next execution step.
Each iteration returns the next thing to perform and the values from the previous unit call.
# Many (1) rows to call next.
(
(<Unit(func=P_add_30.0)>, <ArgsPack(*(40.0,), **{})>),
)
We see one row, with f.add_30 as the next function to call.
run_stepper FunctionThe stepper can run once (allowing us to loop it), or we can use the built-in run_stepper function, to walk the nodes until the chain is complete
from hyperway.graph import Graph
from hyperway.tools import factory as f
from hyperway.packer import argspack
from hyperway.stepper import run_stepper
g = Graph()
connections = g.connect(f.add_10, f.add_20, f.add_30)
# run until exhausted
result = run_stepper(g, connections[0].a, argspack(10))
The value of the stepper is concurrent. When a path ends, the value is stored in the stepper.stash.
When executing node steps, the result from the call is given to the next connected unit.
The stepper provides convenient methods to access results without manually unwrapping the stash:
g = Graph()
g.connect(f.add_10, f.add_20, f.add_30)
g.stepper_prepare(start_node, 10)
s = g.stepper()
while s.step():
pass
# Simple access to results
result = s.get_result() # 70 (single result)
results = s.get_results() # [70] (all results as list)
# Check if results exist
if s.has_results():
print(f"Got {s.result_count()} results")
For graphs with multiple endpoints, organize results by node:
# Branching graph with multiple handlers
g.add(source, handler_a) # handler_a named 'process_a'
g.add(source, handler_b) # handler_b named 'process_b'
g.stepper_prepare(source, 10)
s = g.stepper()
while s.step():
pass
# Organize by node name
results_dict = s.get_results_dict()
# {'process_a': [42], 'process_b': [100]}
# Access specific handler results
process_a_results = results_dict['process_a']
[!TIP] Use
get_result()for single-endpoint graphs,get_results()for all results as a list, orget_results_dict()to organize by node name.
You can organize results using custom keys:
# By node ID
results_by_id = s.get_results_dict(key=lambda n: n.id())
# By function name
results_by_func = s.get_results_dict(key=lambda n: n.func.__name__)
For advanced use cases, access raw ArgsPack objects and use .flat() for custom unwrapping:
# Get raw ArgsPack objects
raw_results = s.get_results(unwrap=False)
for akw in raw_results:
value = akw.flat() # Smart unwrapping to natural representation
# Or access directly: akw.args, akw.kw
For real-time processing, the streaming API yields results as they become available during graph execution:
g.stepper_prepare(start_node, 10)
s = g.stepper()
# Stream results as they arrive (no need to wait for completion)
for result in s.stream():
print(f"Got result: {result}")
# Process immediately, update progress, etc.
# After streaming, stash is empty (results were popped)
assert len(s.stash) == 0
Key Features:
# Multiple endpoints - results arrive as each branch completes
for result in s.stream():
process(result) # Handle each result immediately
# Early termination
for result in s.stream():
if result > 50:
break # Stop execution when condition met
[!TIP] Use
stream()for long-running graphs, reactive patterns, or when you need progress feedback. For complete graphs where you need all results at once, use the standardget_results()approach.
📖 Full Streaming Documentation →
If two nodes call to the same destination node, this causes two calls of the next node:
+4
i +2 +3 print
+5
With this layout, the print function will be called twice by the +4 and +5 node. Two calls occur:
10
1 3 6 print
11
# Two results
print(10) # from path: 1 → +2 → +3 → +4 → 10
print(11) # from path: 1 → +2 → +3 → +5 → 11
This is because there are two connections to the print node, causing two calls.
Use merge nodes to action one call to a node, with two results.
merge_node=True on target nodeconcat_aware=True on the stepper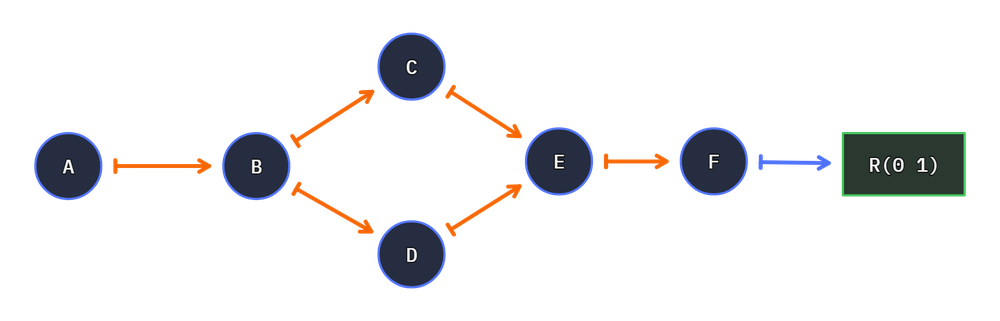
g = Graph()
u = as_unit(print)
u.merge_node = True
s = g.stepper()
s.concat_aware = True
s.step()
...
When processing a print merge-node, one call is executed when events occur through multiple connections during one step:
10
1 3 6 print
11
print(10, 11) # resultant
[!IMPORTANT] Every fork within the graph will yield a new path.
A path defines the flow of a stepper through a single processing chain. A function connected to more than one function will fork the stepper and produce a result per connection.
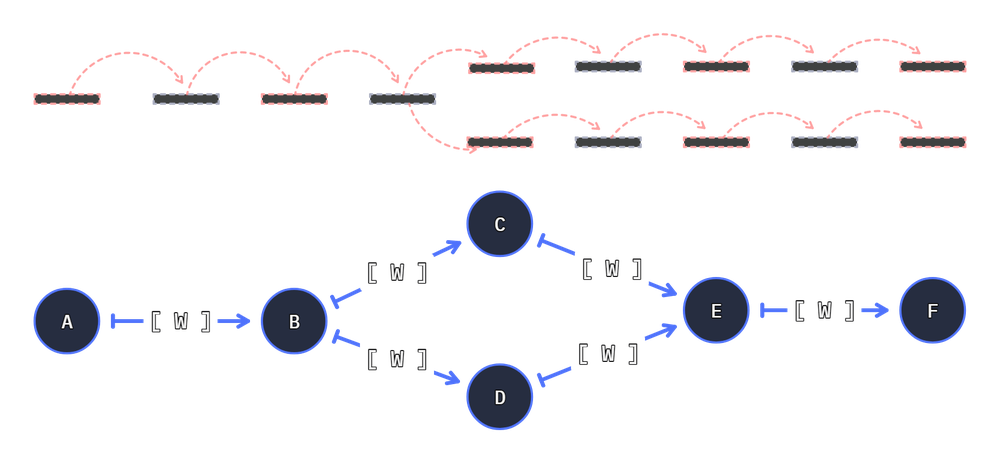
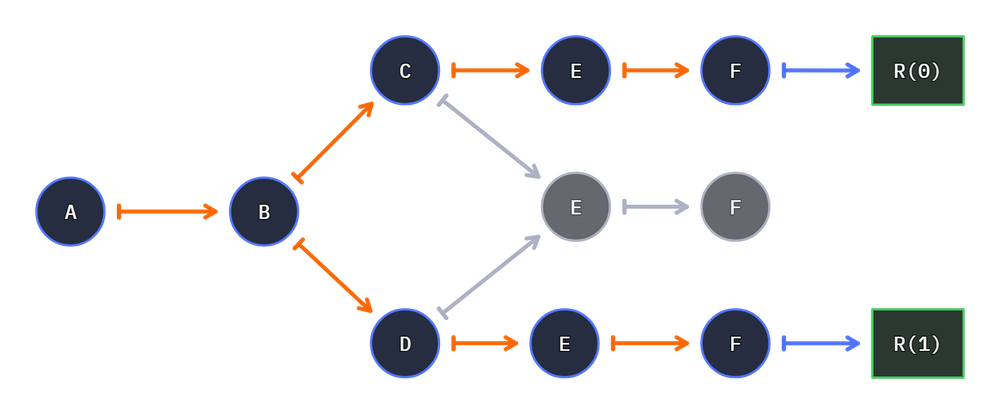
For example a graph with a a split path will yield two results:
from hyperway import Graph, as_units
from hyperway.tools import factory as f
g = Graph()
split, join = as_units(f.add_2, f.add_2)
cs = g.connect(f.add_1, split)
g.connect(split, f.add_3, join)
g.connect(split, f.add_4, join)
g.connect(join, f.add_1)
If graphviz is installed, The graph can be rendered with graph.write():
# Continued from above
g.write('double-split', direction='LR')

Connecting nodes will grow the result count. For example creating in two exits nodes will double the result count
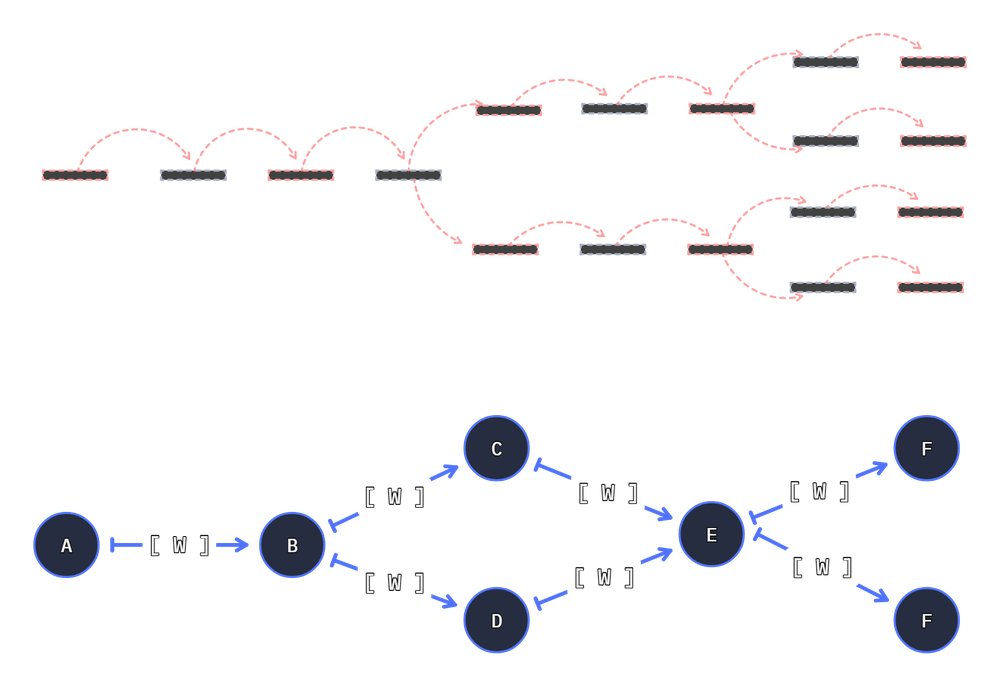
To model this, we can extend the above code with an extra connection: g.connect(join, f.sub_1):
# same as above
from hyperway import Graph, as_units
from hyperway.tools import factory as f
g = Graph()
split, join = as_units(f.add_2, f.add_2)
cs = g.connect(f.add_1, split)
g.connect(split, f.add_3, join)
g.connect(split, f.add_4, join)
g.connect(join, f.add_1)
# connect another function
g.connect(join, f.sub_1)
g.write('double-double-split', direction='LR')

[!NOTE] The count of results is a product of the node count - and may result exponential paths if unmanaged. Hyperway can and will execute this forever.
Wire functions have been removed for clarity
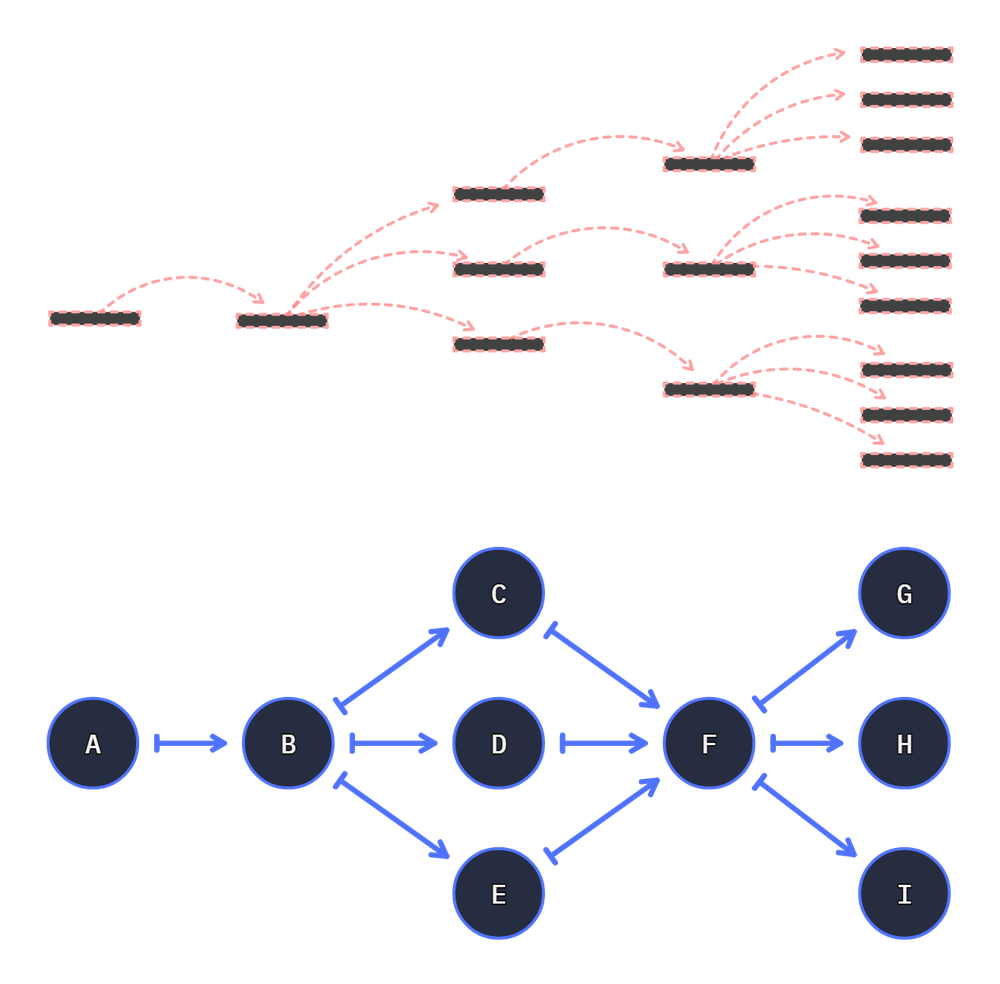
from hyperway import Graph, as_unit
g = Graph()
split = as_unit(f.add_2, name='split')
join_a = as_unit(f.add_2)
# sum([1,2,3]) accepts an array - so we merge the args for the response.
join = as_unit(lambda *x: sum(x), name='sum')
cs = g.connect(f.add_1, split)
g.connect(split, f.add_3, join)
g.connect(split, f.add_4, join)
g.connect(split, f.add_5, join)
g.connect(join, f.add_1)
g.connect(join, f.sub_1)
g.connect(join, f.sub_2)
g.write('triple-split', direction='LR')

Knuckles enable nodes to dynamically choose which outgoing edges to traverse based on runtime data. This allows you to build conditional routing, state machines, and decision trees directly into your graph topology.
By default, when a node has multiple outgoing connections, the stepper traverses all of them (parallel expansion). A knuckle intercepts this behavior and returns a filtered subset of edges.
from hyperway.graph import Graph
from hyperway.nodes import Unit, as_unit
from hyperway.packer import argspack
class Router(Unit):
"""Route based on 'target' key in data."""
def get_connections(self, graph, akw=None):
# Get all outgoing edges from this node
connections = tuple(graph.get(self.id(), ()))
if akw is None:
return connections # No data, return all edges
# Filter edges by connection name matching 'target' key
target = akw.get('target')
if target is None:
return connections
filtered = tuple(c for c in connections if c.name == target)
return filtered if filtered else ()
# Build a graph with conditional routing
g = Graph()
router = Router(lambda x: x)
handler_a = as_unit(lambda x: f"Handler A: {x}")
handler_b = as_unit(lambda x: f"Handler B: {x}")
g.add(router, handler_a, name='route_a')
g.add(router, handler_b, name='route_b')
# Execute: only handler_a will be reached
g.stepper_prepare(router, argspack(10, target='route_a'))
s = g.stepper()
while s.step():
pass
# Result in s.stash will be "Handler A: 10"
The get_connections() method receives the current data (akw) and can apply any logic to filter edges—based on values, predicates, state, or even external conditions.
[!TIP] Use knuckles for: conditional branching, routing based on data attributes, implementing state machines, round-robin scheduling, or circuit breaker patterns.
See docs/knuckles.md for advanced patterns including stateful knuckles, predicate-based filtering, and round-robin routing.
[!IMPORTANT] Hyperway is left-associative, Therefore PEMDAS/BODMAS will not function as expected - graph chains execute linearly.
The order of precedence for operations occurs through sequential evaluation (from left to right) similar to C. Each operation is executed as it is encountered, without regard to the traditional precedence of operators.
| Standard order precedence | Hyperway left-association |
|---|---|
|
|
# example sequential evaluation
from hyperway.tools import factory as f
from hyperway.edges import make_edge, wire
c = make_edge(f.add_1, f.add_2, through=wire(f.mul_2))
assert c.pluck(1) == 6 # (1 + 1) * 2 + 2 == 6
assert c.pluck(10) == 24 # (10 + 1) * 2 + 2 == 24
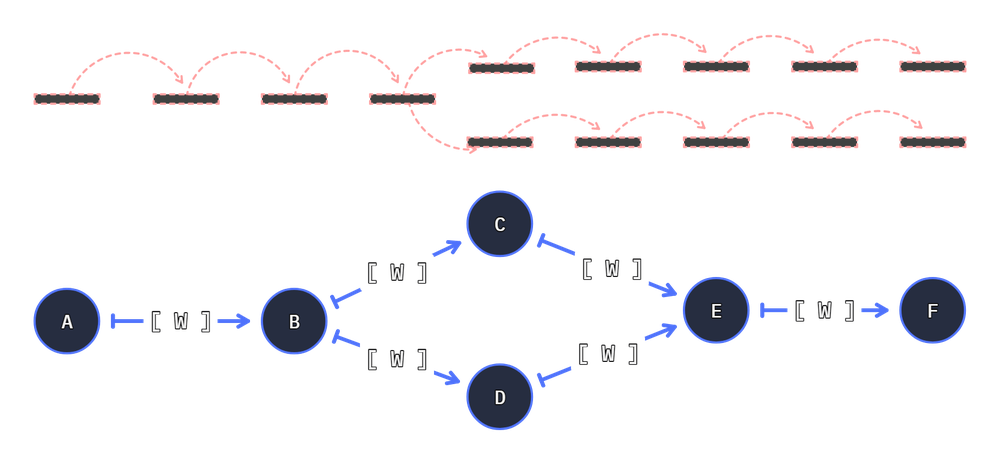
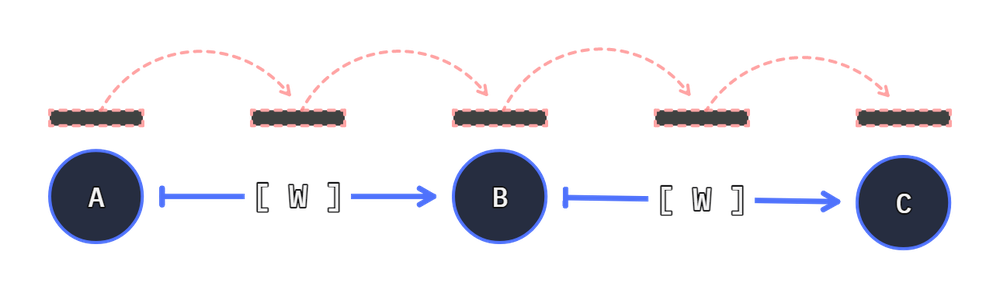
Connection is bound to two nodes, and maintains a wire-function.We push Node to Node Connections into the Graph dictionary. The Connection knows A, B, and potentially a Wire function.
When running the graph we use a Stepper to processes each node step during iteration, collecting results of each call, and the next executions to perform.
We walk through the graph using a Stepper. Upon a step we call any rows of waiting callables. This may be the users first input and will yield next callers and the result.
The Stepper should call each next caller with the given result. Each caller will return next callers and a result for the Stepper to call again.
In each iteration the callable resolves one or more connections. If no connections return for a node, The execution chain is considered complete.
The Graph is purposefully terse. Its build to be as minimal as possible for the task. In the raw solution the Graph is a defaultdict(tuple) with a few additional functions for node acquisition.
The graph maintains a list of ID to Connection set.
{
ID: (
Connection(to=ID2),
),
ID2: (
Connection(to=ID),
)
}
A Connection bind two functions and an optional wire function.
A -> [W] -> B
When executing the connection, input starts through A, and returns through B. If the wire function exists it may alter the value before B receives its input values.
A Unit represents a thing on the graph, bound to other units through connections.
def callable_func(value):
return value * 3
as_unit(callable_func)
A unit is one reference
unit = as_unit(callable_func)
unit2 = as_unit(callable_func)
assert unit != unit2
argspackThe argspack simplifies the movement of arguments and keyword arguments for a function.
we can wrap the result as a pack, always ensuring its unpackable when required.
akw = argspack(100)
akw.a
(100, )
akw = argspack(foo=1)
akw.kw
{ 'foo': 1 }
Although many existing libraries cater to graph theory, they often require a deep understanding of complex terminology and concepts. As an engineer without formal training in graph theory, these libraries are challenging. Hyperway is the result of several years of research aimed at developing a simplified, functional, graph-based execution library with a minimal set of core features.
I'm slowly updating it to include the more advanced future features, such as hyper-edges and connection-decisions, bridging the gap between academic graph theory and practical application, providing developers with a low-level runtime that facilitates functional execution without the need for specialized knowledge.
tf.functionFAQs
A graph based functional execution library. Connect functions arbitrarily through a unique API
We found that hyperway demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Add real-time Socket webhook events to your workflows to automatically receive software supply chain alert changes in real time.
Security News
ENISA has become a CVE Program Root, giving the EU a central authority for coordinating vulnerability reporting, disclosure, and cross-border response.

Product
Socket now scans OpenVSX extensions, giving teams early detection of risky behaviors, hidden capabilities, and supply chain threats in developer tools.