
Product
Introducing Reachability for PHP
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.
By Benjamin Barslev - Apr 24, 2026
metacluster
Advanced tools
MetaCluster: An Open-Source Python Library for Metaheuristic-based Clustering Problems

![]()

![]()


![]()


![]()
![]()
![]()
MetaCluster is the largest open-source nature-inspired optimization (Metaheuristic Algorithms) library for clustering problem in Python
MetaCluster, MhaKCentersClustering, and MhaKMeansTunerPlease include these citations if you plan to use this library:
@article{VanThieu2023,
author = {Van Thieu, Nguyen and Oliva, Diego and Pérez-Cisneros, Marco},
title = {MetaCluster: An open-source Python library for metaheuristic-based clustering problems},
journal = {SoftwareX},
year = {2023},
pages = {101597},
volume = {24},
DOI = {10.1016/j.softx.2023.101597},
}
@article{van2023mealpy,
title={MEALPY: An open-source library for latest meta-heuristic algorithms in Python},
author={Van Thieu, Nguyen and Mirjalili, Seyedali},
journal={Journal of Systems Architecture},
year={2023},
publisher={Elsevier},
doi={10.1016/j.sysarc.2023.102871}
}
$ pip install metacluster
After installation, check the version:
$ python
>>> import metacluster
>>> metacluster.__version__
We implement a dedicated Github repository for examples at MetaCluster_examples
Let's go through some basic examples from here:
# Load available dataset from MetaCluster
from metacluster import get_dataset
# Try unknown data
get_dataset("unknown")
# Enter: 1 -> This wil list all of avaialble dataset
data = get_dataset("Arrhythmia")
import pandas as pd
from metacluster import Data
# load X and y
# NOTE MetaCluster accepts numpy arrays only, hence use the .values attribute
dataset = pd.read_csv('examples/dataset.csv', index_col=0).values
X, y = dataset[:, 0:-1], dataset[:, -1]
data = Data(X, y, name="my-dataset")
You should confirm that your dataset is scaled and normalized
# MinMaxScaler
data.X, scaler = data.scale(data.X, method="MinMaxScaler", feature_range=(0, 1))
# StandardScaler
data.X, scaler = data.scale(data.X, method="StandardScaler")
# MaxAbsScaler
data.X, scaler = data.scale(data.X, method="MaxAbsScaler")
# RobustScaler
data.X, scaler = data.scale(data.X, method="RobustScaler")
# Normalizer
data.X, scaler = data.scale(data.X, method="Normalizer", norm="l2") # "l1" or "l2" or "max"
list_optimizer = ["BaseFBIO", "OriginalGWO", "OriginalSMA"]
list_paras = [
{"name": "FBIO", "epoch": 10, "pop_size": 30},
{"name": "GWO", "epoch": 10, "pop_size": 30},
{"name": "SMA", "epoch": 10, "pop_size": 30}
]
list_obj = ["SI", "RSI"]
list_metric = ["BHI", "DBI", "DI", "CHI", "SSEI", "NMIS", "HS", "CS", "VMS", "HGS"]
You can check all supported metaheuristic algorithms from: https://github.com/thieu1995/mealpy. All supported clustering objectives and metrics from: https://github.com/thieu1995/permetrics.
If you don't want to read the documents, you can print out all supported information by:
from metacluster import MetaCluster
# Get all supported methods and print them out
MetaCluster.get_support(name="all")
model = MetaCluster(list_optimizer=list_optimizer, list_paras=list_paras, list_obj=list_obj, n_trials=3, seed=10)
model.execute(data=data, cluster_finder="elbow", list_metric=list_metric, save_path="history", verbose=False)
model.save_boxplots()
model.save_convergences()
As you can see, you can define different datasets and using the same model to run it. Remember to set the name to your dataset, because the folder that hold your results is the name of your dataset. More examples can be found here
Official source code repo: https://github.com/thieu1995/metacluster
Official document: https://metacluster.readthedocs.io/
Download releases: https://pypi.org/project/metacluster/
Issue tracker: https://github.com/thieu1995/metacluster/issues
Notable changes log: https://github.com/thieu1995/metacluster/blob/master/ChangeLog.md
Official chat group: https://t.me/+fRVCJGuGJg1mNDg1
This project also related to our another projects which are optimization and machine learning. Check it here:
1. https://jtemporal.com/kmeans-and-elbow-method/
2. https://medium.com/@masarudheena/4-best-ways-to-find-optimal-number-of-clusters-for-clustering-with-python-code-706199fa957c
3. https://github.com/minddrummer/gap/blob/master/gap/gap.py
4. https://www.tandfonline.com/doi/pdf/10.1080/03610927408827101
5. https://doi.org/10.1016/j.engappai.2018.03.013
6. https://github.com/tirthajyoti/Machine-Learning-with-Python/blob/master/Clustering-Dimensionality-Reduction/Clustering_metrics.ipynb
7. https://elki-project.github.io/
8. https://sci2s.ugr.es/keel/index.php
9. https://archive.ics.uci.edu/datasets
10. https://python-charts.com/distribution/box-plot-plotly/
11. https://plotly.com/python/box-plots/?_ga=2.50659434.2126348639.1688086416-114197406.1688086416#box-plot-styling-mean--standard-deviation
FAQs
MetaCluster: An Open-Source Python Library for Metaheuristic-based Clustering Problems
We found that metacluster demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.

Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
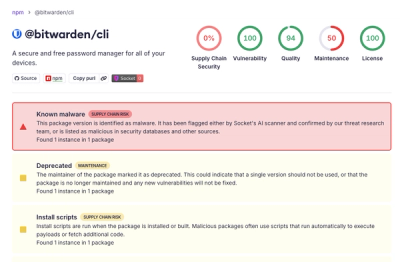
Research
/Security News
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.