Product
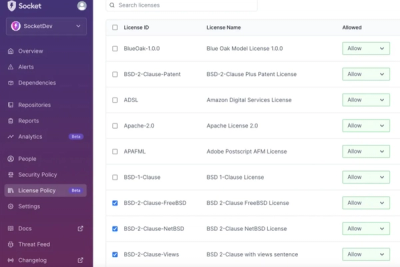
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
This repo provides the service code for llmsherpa API to connect. This repo contains custom RAG (retrieval augmented generation) friendly parsers for the following file formats:
The PDF parser is a rule based parser which uses text co-ordinates (boundary box), graphics and font data from nlmatics modified version of tika found here https://github.com/nlmatics/nlm-tika. The PDF parser works off text layer and also offers a OCR option (apply_ocr) to automatically use OCR if there are scanned pages in your PDFs. The OCR feature is based off a nlmatics modified version of tika which uses tesseract underneath. Check out the notebook pdf_visual_ingestor_step_by_step to experiment directly with the PDF parser.
The PDF Parser offers the following features:
A special HTML parser that creates layout aware blocks to make RAG performance better with higher quality chunks.
A special text parser which tries to figure out lists, tables, headers etc. purely by looking at the text and no visual, font or bbox information.
There are two ways to process these types of documents
java -jar <path_to_nlm_ingestor>/jars/tika-server-standard-nlm-modified-2.9.2_v2.jar
!pip install nlm-ingestor
python -m nlm_ingestor.ingestion_daemon
A docker image is available via public github container registry.
Pull the docker image
docker pull ghcr.io/nlmatics/nlm-ingestor:latest
Run the docker image mapping the port 5001 to port of your choice.
docker run -p 5010:5001 ghcr.io/nlmatics/nlm-ingestor:latest-<version>
Once you have the server running, you can use the llmsherpa API library to get chunks and use them for your LLM projects. Your llmsherpa_url will be: "http://localhost:5010/api/parseDocument?renderFormat=all"
Sample test code to test the server with llmsherpa parser is in this notebook.
Over the course of 4 years, nlmatics team evaluated a variety of options including a yolo based vision parser developed by Tom Liu and Yi Zhang. Ultimately, we settled with the rule based parser due to the following reasons.
The PDFparser visual_ingestor and new_indent_parser was written by Ambika Sukla with additional contributions from Reshav Abraham who wrote the initial code to modify tika, Tom Liu who wrote the original Indent Parser and Kiran Panicker who made several improvements to the parsing speed, table parsing accuracy, indent parsing accuracy and reordering accuracy.
The HTML Ingestor was written by Tom Liu.
The Markdown Parser was written by Yi Zhang.
The Text Ingestor was written by Reshav Abraham.
The XML Ingestor was written by Ambika Sukla primarily to process PubMed XMLs.
The line_parser which serves as a core sentence processing utility for all the other parsers was written by Ambika Sukla.
Also we are thankful to the Apache PDFBox and Tika developer community for their years of work in providing the base for the PDF Parser.
Nlm modified version of Tika can be found in the 2.4.1-nlm branch here https://github.com/nlmatics/nlm-tika/tree/2.4.1-nlm For convenience, a compiled jar file of the code is included in this repo in jars/ folder. In some cases, your PDFs may result in errors in the Java server and you will need to modify the code there to resolve the issue and recompile the jar file.
The following files are changed:
The above is to add font and co-ordinates to every text element. It also removes watermarks.
The above is to add lines and rectangles that can potentially help with table detection.
To see the impact of these changes, see the first part of the notebook here: https://github.com/nlmatics/nlm-ingestor/blob/main/notebooks/pdf_visual_ingestor_step_by_step.ipynb
Some ideas for future work:
FAQs
Parsers and ingestors for different file types and formats
We found that nlm-ingestor demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
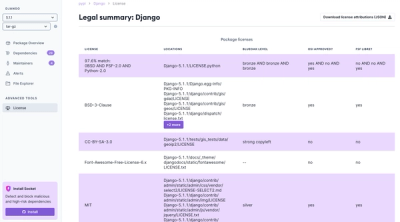
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
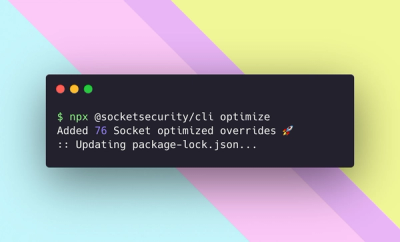
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.