
Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
Functional-style Streams library for processing collections. Supports querying files (json, toml, yaml, xml, csv, tsv, plain text) - as well as creating and updating them. Provides easy integration with itertools


![]()

Functional-style Streams API library
Facilitates processing of collections and iterables using fluent APIs.
Gives access to files of various types (json, toml, yaml, xml, csv, tsv, plain text) for reading and executing complex queries.
Provides easy integration with itertools.
(NB: Commonly used itertools 'recipes' are included as part of the main APIs.)
Stream([1, 2, 3])
Stream.of(1, 2, 3)
Stream.empty()
Stream.iterate(0, lambda x: x + 1)
NB: in similar fashion you can create finite ordered stream by providing a condition predicate
Stream.iterate(10, operation=lambda x: x + 1, condition=lambda x: x < 15).to_list()
# [10, 11, 12, 13, 14]
import random
Stream.generate(lambda: random.random())
Stream.constant(42)
Stream.from_range(0, 10).to_list()
Stream.from_range(0, 10, 3).to_list()
Stream.from_range(10, -1, -2).to_list()
Stream.of(1, 2, 3).concat(Stream.of(4, 5)).to_list()
Stream([1, 2, 3]).concat([5, 6]).to_list()
Stream([2, 3, 4]).prepend(0, 1).to_list()
Stream.of(3, 4, 5).prepend(Stream.of([0, 1], 2)).to_list()
NB: creating new stream from None raises error.
In cases when the iterable could potentially be None use the of_nullable() method instead;
it returns an empty stream if None and a regular one otherwise
Stream([1, 2, 3]).filter(lambda x: x % 2 == 0)
Stream([1, 2, 3]).map(str).to_list()
Stream([1, 2, 3]).map(lambda x: x + 5).to_list()
Stream.of(None, "foo", "", "bar", 0, []).filter_map(str.upper, discard_falsy=True).to_list()
# ["FOO", "BAR"]
Stream([[1, 2], [3, 4], [5]]).flat_map(lambda x: Stream(x)).to_list()
# [1, 2, 3, 4, 5]
Stream([[1, 2], [3, 4], [5]]).flatten().to_list()
# [1, 2, 3, 4, 5]
Stream([1, 2, 3]).reduce(lambda acc, val: acc + val, identity=3).get()
(Stream([1, 2, 3, 4])
.filter(lambda x: x > 2)
.peek(lambda x: print(f"{x} ", end=""))
.map(lambda x: x * 20)
.to_list())
iterable = ["x", "y", "z"]
Stream(iterable).enumerate().to_list()
Stream(iterable).enumerate(start=1).to_list()
# [(0, "x"), (1, "y"), (2, "z")]
# [(1, "x"), (2, "y"), (3, "z")]
Stream([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(start=1, stop=-3, step=2).to_list()
# [2, 4, 6]
Stream([1, 1, 2, 2, 2, 3]).distinct().to_list()
Stream.iterate(0, lambda x: x + 1).skip(5).limit(5).to_list()
Stream([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).limit(3).to_tuple()
Stream([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).head(3).to_tuple()
Stream([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).tail(3).to_tuple()
Stream.of(1, 2, 3, 4, 5, 6, 7, 2, 3).take_while(lambda x: x < 5).to_list()
# [1, 2, 3, 4]
Stream.of(1, 2, 3, 5, 6, 7, 2).drop_while(lambda x: x < 5).to_list()
# [5, 6, 7, 2]
(Stream.of((3, 30), (2, 30), (2, 20), (1, 20), (1, 10))
.sort(lambda x: (x[0], x[1]), reverse=True)
.to_list())
# [(3, 30), (2, 30), (2, 20), (1, 20), (1, 10)]
(Stream.of((3, 30), (2, 30), (2, 20), (1, 20), (1, 10))
.reverse(lambda x: (x[0], x[1]))
.to_list())
# [(3, 30), (2, 30), (2, 20), (1, 20), (1, 10)]
NB: in case of stream of dicts all key-value pairs are represented internally as DictItem objects
(including recursively for nested Mapping structures)
to provide more convenient intermediate operations syntax e.g.
first_dict = {"a": 1, "b": 2}
second_dict = {"x": 3, "y": 4}
(Stream(first_dict).concat(second_dict)
.filter(lambda x: x.value % 2 == 0)
.map(lambda x: x.key)
.to_list())
(Stream([1, 2, 3, 4])
.on_close(lambda: print("Sorry Montessori"))
.peek(lambda x: print(f"{'$' * x} ", end=""))
.map(lambda x: x * 2)
.to_list())
# "$ $$ $$$ $$$$ Sorry Montessori"
# [2, 4, 6, 8]
Stream([1, 2, 3]).to_list()
Stream([1, 2, 3]).to_tuple()
Stream([1, 2, 3]).to_set()
class Foo:
def __init__(self, name, num):
self.name = name
self.num = num
Stream([Foo("fizz", 1), Foo("buzz", 2)]).to_dict(lambda x: (x.name, x.num))
# {"fizz": 1, "buzz": 2}
In the case of a collision (duplicate keys) the 'merger' functions indicates which entry should be kept
collection = [Foo("fizz", 1), Foo("fizz", 2), Foo("buzz", 2)]
Stream(collection).to_dict(collector=lambda x: (x.name, x.num), merger=lambda old, new: old)
# {"fizz": 1, "buzz": 2}
to_dict method also supports creating dictionaries from dict DictItem objects
first_dict = {"x": 1, "y": 2}
second_dict = {"p": 33, "q": 44, "r": None}
Stream(first_dict).concat(Stream(second_dict)).to_dict(lambda x: DictItem(x.key, x.value or 0))
# {"x": 1, "y": 2, "p": 33, "q": 44, "r": 0}
e.g. you could combine streams of dicts by writing:
Stream(first_dict).concat(Stream(second_dict)).to_dict()
(simplified from '.to_dict(lambda x: x)')
Stream({"a": 1, "b": [2, 3]}).to_string()
# "Stream(DictItem(key=a, value=1), DictItem(key=b, value=[2, 3]))"
Stream({"a": 1, "b": [2, 3]}).map(lambda x: {x.key: x.value}).to_string(delimiter=" | ")
# "Stream({'a': 1} | {'b': [2, 3]})"
Stream([1, 2, 3]).collect(tuple)
Stream.of(1, 2, 3).collect(list)
Stream.of(1, 1, 2, 2, 2, 3).collect(set)
Stream.of(1, 2, 3, 4).collect(dict, lambda x: (str(x), x * 10))
Stream.of("x", "y", "z").collect(str, str_delimiter="->")
Stream("AAAABBBCCD").group_by(collector=lambda key, grouper: (key, len(grouper)))
# {"A": 4, "B": 3, "C": 2, "D": 1}
coll = [Foo("fizz", 1), Foo("fizz", 2), Foo("fizz", 3), Foo("buzz", 2), Foo("buzz", 3), Foo("buzz", 4), Foo("buzz", 5)]
Stream(coll).group_by(
classifier=lambda obj: obj.name,
collector=lambda key, grouper: (key, [(obj.name, obj.num) for obj in list(grouper)]))
# {"fizz": [("fizz", 1), ("fizz", 2), ("fizz", 3)],
# "buzz": [("buzz", 2), ("buzz", 3), ("buzz", 4), ("buzz", 5)]}
Stream([1, 2, 3, 4]).for_each(lambda x: print(f"{'#' * x} ", end=""))
Stream([1, 2, 3, 4]).filter(lambda x: x % 2 == 0).count()
Stream.of(1, 2, 3, 4).sum()
Stream.of(2, 1, 3, 4).min().get()
Stream.of(2, 1, 3, 4).max().get()
Stream.of(1, 2, 3, 4, 5).average()
Stream.of(1, 2, 3, 4).filter(lambda x: x % 2 == 0).find_first().get()
Stream.of(1, 2, 3, 4).filter(lambda x: x % 2 == 0).find_any().get()
Stream.of(1, 2, 3, 4).any_match(lambda x: x > 2)
Stream.of(1, 2, 3, 4).all_match(lambda x: x > 2)
Stream.of(1, 2, 3, 4).none_match(lambda x: x < 0)
Stream({"a": 1, "b": 2}).take_first().get()
Stream([]).take_first(default=33).get()
# DictItem(key="a", value=1)
# 33
Stream({"a": 1, "b": 2}).take_last().get()
Stream([]).take_last(default=33).get()
fizz = Foo("fizz", 1)
buzz = Foo("buzz", 2)
Stream([buzz, fizz]).compare_with(Stream([fizz, buzz]), lambda x, y: x.num == y.num)
Stream([2, 3, 4, 5, 6]).quantify(predicate=lambda x: x % 2 == 0)
NB: although the Stream is closed automatically by the terminal operation
you can still close it by hand (if needed) invoking the close() method.
In turn that will trigger the close_handler (if such was provided)
Invoke use method by passing the itertools function and it's arguments as **kwargs
import itertools
import operator
Stream([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).use(itertools.islice, start=3, stop=8)
Stream.of(1, 2, 3, 4, 5).use(itertools.accumulate, func=operator.mul).to_list()
Stream(range(3)).use(itertools.permutations, r=3).to_list()
Invoke the 'recipes' described here as stream methods and pass required key-word arguments
Stream([1, 2, 3]).ncycles(count=2).to_list()
Stream.of(2, 3, 4).take_nth(10, default=66).get()
Stream(["ABC", "D", "EF"]).round_robin().to_list()
NB: use 'pip install pyrio[fs]' to install necessary extra dependencies
FileStream("path/to/file").map(lambda x: f"{x.key}=>{x.value}").to_tuple()
# ("abc=>xyz", "qwerty=>42")
from operator import attrgetter
from pyrio import DictItem
(FileStream("path/to/file")
.filter(lambda x: "a" in x.key)
.map(lambda x: DictItem(x.key, sum(x.value) * 10))
.sort(attrgetter("value"), reverse=True)
.map(lambda x: f"{str(x.value)}::{x.key}")
.to_list())
# ["230::xza", "110::abba", "30::a"]
FileStream("path/to/file").map(lambda x: f"fizz: {x['fizz']}, buzz: {x['buzz']}").to_tuple()
# ("fizz: 42, buzz: 45", "fizz: aaa, buzz: bbb")
from operator import itemgetter
FileStream("path/to/file").map(itemgetter('fizz')).to_list()
# ['42', 'aaa']
You could query the nested dicts by creating streams out of them
(FileStream("path/to/file")
.map(lambda x: (Stream(x).to_dict(lambda y: DictItem(y.key, y.value or "Unknown"))))
.save())
(FileStream("path/to/lorem/ipsum")
.map(lambda x: x.strip())
.enumerate()
.filter(lambda line: "id" in line[1])
.to_dict()
)
# {1: "sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.",
# 6: "Excepteur sint occaecat cupidatat non proident, sunt in culpa",
# 7: "qui officia deserunt mollit anim id est laborum."}
from decimal import Decimal
(FileStream.process(
file_path="path/to/file.json",
f_open_options={"encoding": "utf-8"},
f_read_options={"parse_float": Decimal})
.map(lambda x:x.value).to_list())
# ['foo', True, Decimal('1.22'), Decimal('5.456367654)]
To include the root tag when loading an .xml file pass 'include_root=True'
FileStream.process("path/to/custom_root.xml", include_root=True).map(
lambda x: f"root={x.key}: inner_records={str(x.value)}"
).to_list()
# ["root=custom-root: inner_records={'abc': 'xyz', 'qwerty': '42'}"]
in_memory_dict = Stream(json_dict).filter(lambda x: len(x.key) < 6).to_tuple()
FileStream("path/to/file.json").prepend(in_memory_dict).save("./tests/resources/updated.json")
If no path is given, the source file for the FileStream will be updated
FileStream("path/to/file.json").concat(in_memory_dict).save()
NB: if while updating the file something goes wrong, the original content will be restored/preserved
FileStream("path/to/test.toml").save(null_handler=lambda x: DictItem(x.key, x.value or "N/A"))
NB: useful for writing .toml files which don't allow None values
FileStream("path/to/file.json").concat(in_memory_dict).save(
file_path="merged.xml",
f_open_options={"encoding": "utf-8"},
f_write_options={"indent": 4},
)
E.g. to append to existing file pass f_open_options={"mode": "a"} to the save() method.
NB: By default saving plain text uses "\n" as delimiter between items,
you can pass custom delimiter using f_write_options
(FileStream("path/to/lorem/ipsum")
.map(lambda line: line.strip())
.enumerate()
.filter(lambda line: "ad" in line[1])
.map(lambda line: f"line:{line[0]}, text='{line[1]}'")
.save(f_open_options={"mode": "a"}, f_write_options={"delimiter": " || "})
)
# Lorem ipsum...
# ...
# line:0, text='Lorem ipsum dolor sit amet, consectetur adipisicing elit,' || line:2, text='Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris'
When working with plain text you can pass 'header' and 'footer' as f_write_options
to be prepended or appended to the FileStream output
(FileStream("path/to/lorem/ipsum")
.map(lambda line: line.strip())
.enumerate()
.filter(lambda line: line[0] == 3)
.map(lambda line: f"{line[0]}: {line[1]}")
.save(f_open_options={"mode": "a"}, f_write_options={"header": "\nHeader\n", "footer": "\nFooter\n"})
)
# Lorem ipsum...
# ...
# qui officia deserunt mollit anim id est laborum.
#
# Header
# 3: nisi ut aliquip ex ea commodo consequat.
# Footer
#
To add custom root tag when saving an .xml file pass 'xml_root="my-custom-root"'
FileStream("path/to/file.json").concat(in_memory_dict).save(
file_path="path/to/custom.xml",
f_open_options={"encoding": "utf-8"},
f_write_options={"indent": 4},
xml_root="my-custom-root",
)
(
FileStream("path/to/file.csv")
.concat(
FileStream("path/to/other/file.json")
.filter(
lambda x: (
Stream(x.value)
.find_first(lambda y: y.key == "name" and y.value != "Snake")
.or_else_get(lambda: None)
)
is not None
)
.map(lambda x: x.value)
)
.map(lambda x: (Stream(x).to_dict(lambda y: DictItem(y.key, y.value or "N/A"))))
.save("path/to/third/file.tsv")
)
# check if given string is palindrome; string length is guaranteed to be > 0
def validate_str(string):
stop = len(string) // 2 if len(string) > 1 else 1
return Stream.from_range(0, stop).all_match(lambda x: string[x] == string[-x - 1])
validate_str("a1b2c3c2b1a")
validate_str("abc321")
validate_str("xyyx")
validate_str("aba")
validate_str("z")
# True
# False
# True
# True
# True
# count vowels and constants in given string
def process_str(string):
ALL_VOWELS = "AEIOUaeiou"
return (Stream(string)
.filter(lambda ch: ch.isalpha())
.partition(lambda ch: ch in ALL_VOWELS) # Partitions entries into true and false ones
.map(lambda p: tuple(p))
.enumerate()
.map(lambda x: ("Vowels" if x[0] == 0 else "Consonants", [len(x[1]), x[1]]))
.to_dict()
)
process_str("123Ab5oc-E6db#bCi9<>")
# {'Vowels': [4, ('A', 'o', 'E', 'i')], 'Consonants': [6, ('b', 'c', 'd', 'b', 'b', 'C')]}
How hideous can it get?

FAQs
Functional-style Streams library for processing collections. Supports querying files (json, toml, yaml, xml, csv, tsv, plain text) - as well as creating and updating them. Provides easy integration with itertools
We found that pyrio demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
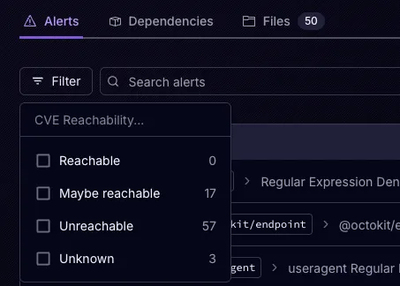
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.