
Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
Python framework to record and validate data pre-processing steps in Data Science and AI workflows. Still in ⚠️Development⚠️
pip install data-flow
If you have some raw data you often apply some functions that change your data to fit a specific problem. The problem is that there is no simple tool that can record and validate all the changes that happened to your data while you were working with it. It becomes a bigger problem when you have lots of pre-processing steps or work in a team with other developers.
By using Dataflow, you can easily wrap your functions with decorators and record/validate all the changes. You can think of Dataflow as a migration tool, but for data pipelines.
Without Dataflow, your code can look like this:
raw_data = [1, 2, 3, ...]
unique_data = list(set(raw_data))
sorted_data = sorted(unique_data)
final_data = [
value for value in sorted_data if value >= 5
]
print(final_data) # [2, 3, 4, 5]
It is a simple example, buy you can imagine your Torch, Tensorflow, Pandas or Numpy pre-processing here. However, there are some problems:
These problems have haunted many, but you can solve them easily with Dataflow:
from dataflow.mutations import mutation
from dataflow.validations.pipelines.after import after
from dataflow.validations.pipelines.before import before
@mutation() # Mutation is a step in your pipeline
@before(lambda data: len(data) > 0, hint="Data is empty") # Data is not empty before we run the mutation
@after(lambda data: len(data) > 5, hint="Data size is less than 5") # Data has enough entries after the mutation
def remove_duplicates(data: list[float]) -> list[float]:
return list(set(data))
@mutation() # Another mutation without any validations
def sort(data: list[float], reverse: bool = False) -> list[float]:
return sorted(data, reverse=reverse)
@mutation() # Mutation with a simple validation
@after(not_lambda_validation)
def remove_under_threshold(data: list[float], threshold: float) -> list[float]:
return [value for value in data if value >= threshold]
mutation_pipeline = sort() >> remove_duplicates() >> remove_under_threshold(threshold=2)
final_data = mutation_pipeline(data=[1, 2, 3, 4, 5] * 100) # final data = [2, 3, 4, 5]
print(mutation_pipeline) # sort() >> remove_duplicates() >> remove_under_threshold(threshold=2)
As you can see, we don't change much in the data pre-processing itself, but only add some decorators and use some new syntax to validate that the changes are correct. Dataflow enables users to easily find pitfalls and issues in their pipelines.
MIT
FAQs
Pipelines validations with simple decorators
We found that python-dataflow demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
Product
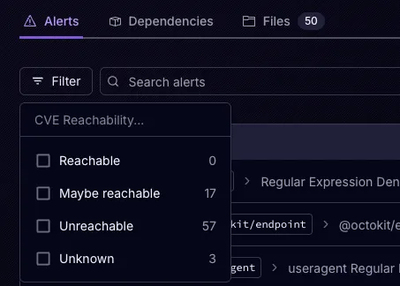
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.