Product
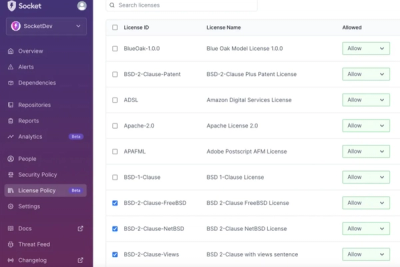
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
A flexible sentiment analysis predictor package supporting multiple pre-trained models, customizable preprocessing, visualization tools, fine-tuning capabilities, and seamless integration with pandas DataFrames.
![]()

![]()
![]()
![]()
A flexible sentiment analysis predictor package supporting multiple pre-trained models, customizable preprocessing, visualization tools, fine-tuning capabilities, and seamless integration with pandas DataFrames.
sentimentpredictor is a Python package designed to classify sentiments in text using various pre-trained models from Hugging Face's Transformers library. This package provides a user-friendly interface for sentiment classification, along with tools for data preprocessing, visualization, fine-tuning, and integration with popular data platforms.
You can install the package using pip:
pip install sentimentpredictor
Here's an example of how to use the SentimentPredictor to classify a single text:
from sentimentpredictor import SentimentPredictor
# Initialize the predictor with the default model
predictor = SentimentPredictor()
# Classify a single text
text = "I am very happy today!"
result = predictor.predict(text)
print("Sentiment:", result['label'])
print("Confidence:", result['confidence'])
You can classify multiple texts at once using the predict_batch method:
texts = ["I am very happy today!", "I am so sad."]
results = predictor.predict_batch(texts)
print("Batch processing results:", results)
To visualize the sentiment distribution of a text:
from sentimentpredictor import plot_sentiment_distribution
result = predictor.predict("I am very happy today!")
plot_sentiment_distribution(result['probabilities'], predictor.labels.values())
You can also use the package from the command line:
sentimentpredictor --model roberta --text "I am very happy today!"
Integrate with pandas DataFrames to classify text columns:
import pandas as pd
from sentimentpredictor import DataFrameSentimentPredictor
df = pd.DataFrame({
'text': ["I am very happy today!", "I am so sad."]
})
predictor = DataFrameSentimentPredictor()
df = predictor.classify_dataframe(df, 'text')
print(df)
Analyze and plot sentiment trends over time:
from sentimentpredictor import SentimentAnalysisTrends
texts = ["I am very happy today!", "I am feeling okay.", "I am very sad."]
trends = SentimentAnalysisTrends()
sentiments = trends.analyze_trends(texts)
trends.plot_trends(sentiments)
Fine-tune a pre-trained model on your own dataset:
from sentimentpredictor.fine_tune import fine_tune_model
# Define your train and validation datasets
train_dataset = ...
val_dataset = ...
# Fine-tune the model
fine_tune_model(predictor.model, predictor.tokenizer, train_dataset, val_dataset, output_dir='fine_tuned_model')
By default, the sentimentpredictor package logs messages at the WARNING level and above. If you need more detailed logging (e.g., for debugging), you can set the logging level to INFO or DEBUG:
from sentimentpredictor.logger import set_logging_level
# Set logging level to INFO
set_logging_level('INFO')
# Set logging level to DEBUG
set_logging_level('DEBUG')
You can set the logging level to one of the following: DEBUG, INFO, WARNING, ERROR, CRITICAL.
Run the tests using pytest:
poetry run pytest
This project is licensed under the MIT License - see the LICENSE file for details.
This package uses pre-trained models from the Hugging Face Transformers library.
Contributions are welcome! Please see the CONTRIBUTING file for guidelines on how to contribute to this project.
FAQs
A flexible sentiment analysis predictor package supporting multiple pre-trained models, customizable preprocessing, visualization tools, fine-tuning capabilities, and seamless integration with pandas DataFrames.
We found that sentimentpredictor demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
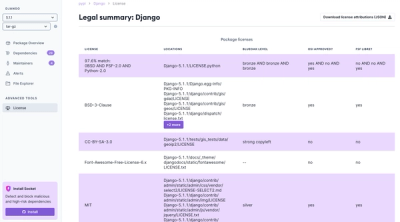
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
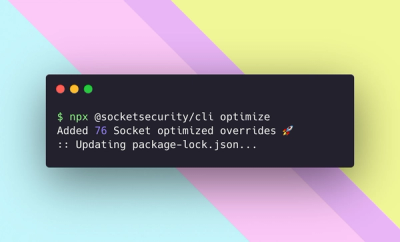
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.