
Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
![]()
![]()
Typed wrappers over pandas DataFrames with schema validation.
![]()
TypedDataFrame is a lightweight wrapper over pandas DataFrame that provides runtime schema validation and can be used to establish strong data contracts between interfaces in your Python code.
The goal of the library is to reveal and make explicit all unclear or forgotten assumptions about your DataFrame.
Check the Official Documentation.
Install typedframe library:
pip install typedframe
Assume an overly simplified preprocessing code like this:
def preprocess(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
c1_min, c1_max = df['col1'].min(), df['col1'].max()
df['col1'] = 0 if c1_min == c1_max else (df['col1'] - c1_min) / (c1_max - c1_min)
df['month'] = df['date'].dt.month
df['comment'] = df['comment'].str.lower()
return df
To add typedframe schema support for this transformation we will define two schema classes - for the input and for the output:
import numpy as np
from typedframe import TypedDataFrame, DATE_TIME_DTYPE
class MyRawData(TypedDataFrame):
schema = {
'col1': np.float64,
'date': DATE_TIME_DTYPE,
'comment': str,
}
class PreprocessedData(MyRawData):
schema = {
'month': np.int8
}
Then let's modify the preprocess function to take a typed wrapper MyRawData as input and return PreprocessedData:
def preprocess(data: MyRawData) -> PreprocessedData:
df = data.df.copy()
c1_min, c1_max = df['col1'].min(), df['col1'].max()
df['col1'] = 0 if c1_min == c1_max else (df['col1'] - c1_min) / (c1_max - c1_min)
df['month'] = df['date'].dt.month
df['comment'] = df['comment'].str.lower()
return PreprocessedData.convert(df)
As you can see the actual DataFrame can be accessed via the .df attribute of the Typed DataFrame.
Now clients of the preprocess function can easily check what are the inputs and outputs without the need to look at its internals.
And if there are some unforseen changes in the data an exception will be thrown before the actual function will be invoked.
Let's check:
import pandas as pd
df = pd.DataFrame({
'col1': [0.1, 0.2],
'date': ['2021-01-01', '2022-01-01'],
'comment': ['foo', 'bar']
})
df.date = pd.to_datetime(df.date)
bad_df = pd.DataFrame({
'col1': [1, 2],
'comment': ['foo', 'bar']
})
df2 = preprocess(MyRawData(df))
df3 = preprocess(MyRawData(bad_df))
The first call was successful. But when we've tried to pass a wrong dataframe as input we've got the following error:
AssertionError: Dataframe doesn't match schema
Actual: {'col1': dtype('int64'), 'comment': dtype('O')}
Expected: {'col1': <class 'numpy.float64'>, 'date': dtype('<M8[ns]'), 'comment': <class 'object'>}
Difference: {('col1', <class 'numpy.float64'>), ('date', dtype('<M8[ns]'))}
Tested on the following versions:
Python: 3.9
numpy: 1.20, 1.21, 1.22
pandas: 1.2, 1.3, 1.4
git clone git@github.com:areshytko/typedframe.git
cd typedframe
pip install -r requirements.txt
pytest
FAQs
Typed Wrappers over Pandas and Polars DataFrames with schema validation
We found that typedframe demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
Product
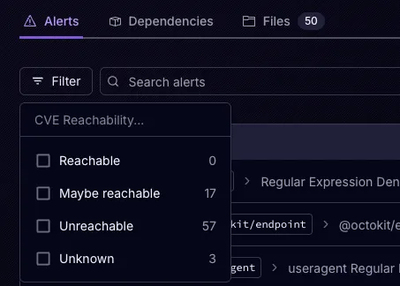
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.