Research
/Security News
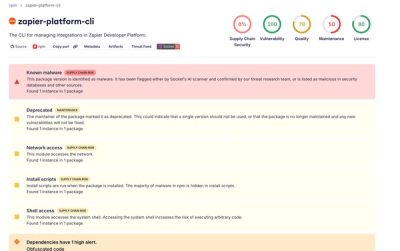
Shai Hulud Strikes Again (v2)
Another wave of Shai-Hulud campaign has hit npm with more than 500 packages and 700+ versions affected.
By Socket Research Team - Nov 24, 2025
workhorse
Advanced tools
![]()
![]()
Multi-threaded job backend with database queuing for Ruby. Battle-tested and ready for production-use.
How it works:
perform method.What it does not do:
>= 3.0 (may work with earlier versions but is untested)>= 7.0fork. See the
FAQ for possible workarounds.Add workhorse to your Gemfile:
gem 'workhorse'
Install it using bundle install as usual.
Run the install generator:
bundle exec rails generate workhorse:install
This generates:
jobsconfig/initializers/workhorse.rb for global configuration
--skip-initializer flagbin/workhorse.rbPlease customize the initializer and worker script to your liking.
When using Oracle databases, make sure your schema has access to the package
DBMS_LOCK:
GRANT execute ON DBMS_LOCK TO <schema-name>;
Workhorse can handle any jobs that support the perform method and are
serializable. To queue a basic job, use Workhorse.enqueue.
You can optionally pass a queue name, a priority, and a description.
class MyJob
def initialize(name)
@name = name
end
def perform
puts "Hello #{@name}"
end
end
Workhorse.enqueue MyJob.new('John'), queue: :test, priority: 2, description: 'Basic Job'
Workhorse allows you to easily queue
RailsOps operations using the static
method Workhorse.enqueue_op:
Workhorse.enqueue_op Operations::Jobs::CleanUpDatabase, { queue: :maintenance, priority: 2 }, quiet: true
The first argument of the method is the Operation you want to run. Parameters passed in using the second argument will be used by Workhorse and parameters passed using the third argument will be used for operation instantiation at job execution, i.e.:
Workhorse.enqueue_op <Operation Class Name>, { <Workhorse Options> }, { <RailsOps Options> }
If you do not want to pass any parameters to the operation, just omit the third hash:
Workhorse.enqueue_op Operations::Jobs::CleanUpDatabase, queue: :maintenance, priority: 2
Workhorse has no out-of-the-box functionality to support scheduling of regular jobs, such as maintenance or backup jobs. There are two primary ways of achieving regular execution:
Rescheduling by the same job after successful execution and setting
perform_at
This is simple to set up and requires no additional dependencies. However, the time taken to execute a job and the time delay caused by the polling interval cannot easily be factored into the calculation of the interval, leading to a slight shift in effective execution date. (This can be mitigated by scheduling the job before knowing whether the current run will succeed. Proceed down this path at your own peril!)
Example: A job that takes 5 seconds to run and reschedules itself every 10 minutes. If started at 12:00 sharp, after one hour it will execute at 13:00:30 at the earliest due to cumulative execution time.
In its most basic form, the perform method of a job would look as follows:
class MyJob
def perform
# Do all the work
# Perform again after 10 minutes (600 seconds)
Workhorse.enqueue MyJob.new, perform_at: Time.now + 600
end
end
Using an external scheduler
A more elaborate setup requires an external scheduler, but which can still be
called from Ruby. One such scheduler is
rufus-scheduler. A small
example of an adapted bin/workhorse.rb to accommodate for the additional
cog in the mechanism is given below:
#!/usr/bin/env ruby
require './config/environment'
Workhorse::Daemon::ShellHandler.run do |daemon|
# Start scheduler process
daemon.worker 'Scheduler' do
scheduler = Rufus::Scheduler.new
scheduler.cron '0/10 * * * *' do
Workhorse.enqueue Workhorse::Jobs::CleanupSucceededJobs.new
end
Signal.trap 'TERM' do
scheduler.shutdown
end
scheduler.join
end
# Start 5 worker processes with 3 threads each
5.times do
daemon.worker do
Workhorse::Worker.start_and_wait(pool_size: 3, polling_interval: 10, logger: Rails.logger)
end
end
end
This allows starting and stopping the daemon with the usual interface. Note that the scheduler is handled like a Workhorse worker, the consequence of which is that only one 'worker' should be started by the ShellHandler. Otherwise there would be multiple jobs scheduled at the same time.
Please refer to the documentation for rufus-scheduler (or the scheduler of your choice) for further options concerning the timing of the jobs.
Workers poll the database for new jobs and execute them in one or more threads. Typically, one worker is started per process. While you can start workers manually, either in your main application process(es) or in a separate one, workhorse also provides you with a convenient way of starting one or multiple worker processes as daemons.
Workers are created by instantiating, configuring, and starting a new
Workhorse::Worker instance:
Workhorse::Worker.start_and_wait(
pool_size: 5, # Processes 5 jobs concurrently
quiet: false, # Logs to STDOUT
logger: Rails.logger # Logs to Rails log. You can also
# provide any custom logger.
)
See code documentation
for more information on the arguments. All arguments passed to start_and_wait
are passed to the initializer of Workhorse::Worker.
Using Workhorse::Daemon::ShellHandler, you can spawn one or multiple worker
processes automatically. This is useful for cases where you want the workers to
exist in separate processes as opposed to your main application process(es).
For this case, the workhorse install routine automatically creates the file
bin/workhorse.rb, which can be used to start one or more worker processes.
The script can be called as follows:
RAILS_ENV=production bundle exec bin/workhorse.rb start|stop|kill|status|watch|restart|usage
Within the shell handler, you can instantiate, configure, and start a worker as described under Start workers manually:
Workhorse::Daemon::ShellHandler.run do |daemon|
5.times do
daemon.worker do
# This will be run 5 times, each time in a separate process. Per process, it
# will be able to process 3 jobs concurrently.
Workhorse::Worker.start_and_wait(pool_size: 3, logger: Rails.logger)
end
end
end
By default, each worker only polls in the given interval. This means that if you schedule, for example, 50 jobs at once and have a polling interval of 1 minute with a queue size of 1, the poller would tackle the first job and then wait for a whole minute until the next poll. This would mean that these 50 jobs would take at least 50 minutes to be executed, even if they only take a few seconds each.
This is where instant repolling comes into play: Using the worker option
instant_repolling, you can force the poller to automatically re-poll the
database whenever a job has been performed. It then goes back to the usual
polling interval.
This setting is recommended for all setups and may eventually be enabled by default.
By default, each job is run in an individual database transaction. An exception
to this is when performing ActiveJob jobs using perform_now, where no
transaction is created.
By default, transactions are created using ActiveRecord::Base.transaction.
You can customize this using the setting config.tx_callback in your
config/initializers/workhorse.rb (see commented out section in the generated
configuration file).
You can turn off transaction wrapping in the following ways:
Globally using the setting config.perform_jobs_in_tx = false in your
config/initializers/workhorse.rb. This is not recommended as running jobs
without transactions can potentially be harmful.
On a per-job basis. This is the recommended approach for jobs that either open up their own transaction(s) or jobs that explicitly do not need a transaction for whatever reason.
Usage of this feature depends on whether you are dealing with an ActiveJob job, an enqueued RailsOps operation or a plain Workhorse job class.
For ActiveJob:
Add the following mixin to your job class (usually ApplicationJob):
class ApplicationJob
include Workhorse::ActiveJobExtension
end
Use the DSL-method skip_tx inside the job classes where you want to
disable transaction wrapping, e.g.:
class MyJob < ApplicationJob
skip_tx
def perform
# Something without transaction
end
end
For enqueuable RailsOps operations:
Add the following static method to your operation class:
class MyOp < RailsOps::Operation
def self.skip_tx?
true
end
end
For plain Workhorse job classes:
Add the following static method to your job class:
class MyJob
def self.skip_tx?
true
end
end
By default, exceptions occurring in a worker thread will only be visible in the
respective log file, usually production.log. If you'd like to perform specific
actions when an exception arises, set the global option on_exception to a
callback of your liking, e.g.:
# config/initializers/workhorse.rb
Workhorse.setup do |config|
config.on_exception = proc do |e|
# Use gem 'exception_notification' for notifying about exceptions
ExceptionNotifier.notify_exception(e)
end
end
Using the settings config.silence_poller_exceptions and
config.silence_watcher, you can silence certain exceptions / error outputs
(both are disabled by default).
Jobs stored in the database can be accessed via the ActiveRecord model {Workhorse::DbJob}. This is the model representing a specific job database entry and is not to be confused with the actual job class you're enqueueing.
DbJobs are returned to you when enqueuing new jobs:
db_job = Workhorse.enqueue(MyJob.new)
You can also obtain a job via its ID that you either get from a returned job (see example above) or else by manually querying the database table:
db_job = Workhorse::DbJob.find(42)
Note that database job objects reflect the job at the point in time when the
database job object has been instantiated. To make sure you're looking at the
latest job info, use the in-place reload method:
db_job.reload
You can also retrieve a list of jobs in a specific state using one of the following methods:
DbJob.waiting
DbJob.locked
DbJob.started
DbJob.succeeded
DbJob.failed
Jobs in a state other than waiting are either being processed or else already
in a final state such as succeeded and won't be performed again. Workhorse
provides an API method for resetting jobs in the following cases:
A job has succeeded or failed (states succeeded and failed) and needs to
re-run. In these cases, perform a non-forced reset:
db_job.reset!
This is always safe to do, even with workers running.
A job is stuck in state locked or started and the corresponding worker
(check the database field locked_by) is not running anymore, i.e. due to a
database connection loss or an unexpected worker crash. In these cases, the
job will never be processed, and, if the job is in a queue, the entire queue is
considered to be locked and no further jobs will be processed in this queue.
In these cases, make sure the worker is stopped and perform a forced reset:
db_job.reset!(true)
Performing a reset will reset the job state to waiting and it will be
processed again. All meta fields will be reset as well. See inline documentation
of Workhorse::DbJob#reset! for more details.
While workhorse can be used though its custom interface as documented above, it
is also fully integrated into Rails using ActiveJob. See documentation of
ActiveJob for more
information on how to use it.
To use workhorse as your ActiveJob backend, set the queue_adapter to
workhorse, either using config.active_job.queue_adapter in your application
configuration or else using self.queue_adapter in a job class inheriting from
ActiveJob. See ActiveJob documentation for more details.
Per default, jobs remain in the database, no matter in which state. This can
eventually lead to a very large jobs database. You are advised to clean your
jobs database on a regular interval. Workhorse provides the job
Workhorse::Jobs::CleanupSucceededJobs for this purpose that cleans up all
succeeded jobs. You can run this using your scheduler in a specific interval.
When a worker exceeds the memory limit specified by
config.max_worker_memory_mb (assuming it is configured to a value greater than 0), it initiates
a graceful shutdown process by creating a shutdown file named
tmp/pids/workhorse.<pid>.shutdown.
Simultaneously, the watch command, if scheduled, monitors the presence of this
shutdown file. Upon detecting its existence, it silently triggers the restart of
the shutdown worker and removes the shutdown file to signify that the restart
process has begun.
This mechanism ensures that workers are automatically restarted without manual intervention when memory limits are exceeded.
Example configuration:
# config/initializers/workhorse.rb
Workhorse.setup do |config|
config.max_worker_memory_mb = 512 # Set the memory threshold to 512 megabytes
end
Using the load hook :workhorse_db_job, you can inject custom code into the
Gem-internal model class Workhorse::DbJob, for example:
# config/initializers/workhorse.rb
ActiveSupport.on_load :workhorse_db_job do
# Code within this block will be run inside of the model class
# Workhorse::DbJob.
belongs_to :user
end
Each worker process includes one thread that polls the database for jobs and dispatches them to individual worker threads. In case of an error in the poller (usually due to a database connection drop), the poller aborts and gracefully shuts down the entire worker. Jobs still being processed by this worker are attempted to be completed during this shutdown (which only works if the database connection is still active).
This means that you should always have an external watcher (usually a
cronjob), that calls the workhorse watch command regularly. This would
automatically restart crashed worker processes.
Each Workhorse worker uses a poller to check the database for new jobs. To
ensure that no job is obtained by more than one worker, a global database lock
is used. If a worker is killed, it may happen that the lock is not properly
released, which can cause all pollers to stop working because they cannot
acquire the lock. This is an edge case, as the locks should typically be
released properly, even if a worker process is killed using SIGKILL.
In the event that this still happens, Workhorse takes the following steps:
on_exception callback (if configured) after a configurable number of consecutive failures to obtain the lock.The maximum number of consecutive failures can be configured using
config.max_global_lock_fails, which defaults to 10.
Jobs in named queues (non-null queues) are always run sequentially. This means
that if a job in such a queue is stuck in states locked or started (i.e. due
to a database connection failure), no more jobs of this queue will be run as the
entire queue is considered locked to ensure that no jobs of the same queue run
in parallel.
For this purpose, Workhorse provides the built-in job
Workhorse::Jobs::DetectStaleJobsJob which you are advised schedule on a
regular basis. It picks up jobs that remained locked or started (running)
for more than a certain amount of time. If any of these jobs are found, an
exception is thrown (which may cause a notification if you configured
on_exception accordingly). See the job's API documentation for more
information.
Starting with Workhorse 1.2.16, there is also a feature that automatically
checks for stuck jobs (jobs in state locked or started running on the same
host where the corresponding PID does not have a process anymore) when starting
up the worker / poller. This feature can be turned on using the setting
config.clean_stuck_jobs. This is turned off by default.
Please consult the FAQ.
Copyright © 2017 - 2026 Sitrox. See LICENSE for further details.
FAQs
Unknown package
We found that workhorse demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Another wave of Shai-Hulud campaign has hit npm with more than 500 packages and 700+ versions affected.

Product
Add real-time Socket webhook events to your workflows to automatically receive software supply chain alert changes in real time.
Security News
ENISA has become a CVE Program Root, giving the EU a central authority for coordinating vulnerability reporting, disclosure, and cross-border response.