Product
Introducing License Enforcement in Socket
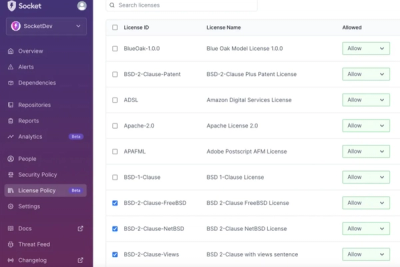
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
github.com/antipasta/prose



prose is Go library for text (primarily English at the moment) processing that supports tokenization, part-of-speech tagging, named-entity extraction, and more. The library's functionality is split into subpackages designed for modular use.
See the GoDoc documentation for more information.
$ go get github.com/jdkato/prose/...
NOTE: When using some vendoring tools, such as
govendor, you may need to include thegithub.com/jdkato/prose/internal/package in addition to the core package(s). See #14 for more information.
Word, sentence, and regexp tokenizers are available. Every tokenizer implements the same interface, which makes it easy to customize tokenization in other parts of the library.
package main
import (
"fmt"
"github.com/jdkato/prose/tokenize"
)
func main() {
text := "They'll save and invest more."
tokenizer := tokenize.NewTreebankWordTokenizer()
for _, word := range tokenizer.Tokenize(text) {
// [They 'll save and invest more .]
fmt.Println(word)
}
}
The tag package includes a port of Textblob's "fast and accurate" POS tagger. Below is a comparison of its performance against NLTK's implementation of the same tagger on the Treebank corpus:
| Library | Accuracy | 5-Run Average (sec) |
|---|---|---|
| NLTK | 0.893 | 7.224 |
prose | 0.961 | 2.538 |
(See scripts/test_model.py for more information.)
package main
import (
"fmt"
"github.com/jdkato/prose/tag"
"github.com/jdkato/prose/tokenize"
)
func main() {
text := "A fast and accurate part-of-speech tagger for Golang."
words := tokenize.NewTreebankWordTokenizer().Tokenize(text)
tagger := tag.NewPerceptronTagger()
for _, tok := range tagger.Tag(words) {
fmt.Println(tok.Text, tok.Tag)
}
}
The tranform package implements a number of functions for changing the case of strings, including Title, Snake, Pascal, and Camel.
Additionally, unlike strings.Title, tranform.Title adheres to common guidelines—including styles for both the AP Stylebook and The Chicago Manual of Style. You can also add your own custom style by defining an IgnoreFunc callback.
Inspiration and test data taken from python-titlecase and to-title-case.
package main
import (
"fmt"
"strings"
"github.com/jdkato/prose/transform"
)
func main() {
text := "the last of the mohicans"
tc := transform.NewTitleConverter(transform.APStyle)
fmt.Println(strings.Title(text)) // The Last Of The Mohicans
fmt.Println(tc.Title(text)) // The Last of the Mohicans
}
The summarize package includes functions for computing standard readability and usage statistics. It's among the most accurate implementations available due to its reliance on legitimate tokenizers (whereas others, like readability-score, rely on naive regular expressions).
It also includes a TL;DR algorithm for condensing text into a user-indicated number of paragraphs.
package main
import (
"fmt"
"github.com/jdkato/prose/summarize"
)
func main() {
doc := summarize.NewDocument("This is some interesting text.")
fmt.Println(doc.SMOG(), doc.FleschKincaid())
}
The chunk package implements named-entity extraction using a regular expression indicating what chunks you're looking for and pre-tagged input.
package main
import (
"fmt"
"github.com/jdkato/prose/chunk"
"github.com/jdkato/prose/tag"
"github.com/jdkato/prose/tokenize"
)
func main() {
words := tokenize.TextToWords("Go is an open source programming language created at Google.")
regex := chunk.TreebankNamedEntities
tagger := tag.NewPerceptronTagger()
for _, entity := range chunk.Chunk(tagger.Tag(words), regex) {
fmt.Println(entity) // [Go Google]
}
}
If not otherwise specified (see below), the source files are distributed under MIT License found in the LICENSE file.
Additionally, the following files contain their own license information:
tag/aptag.go: MIT © Matthew Honnibal.tokenize/punkt.go: MIT © Eric Bower.tokenize/pragmatic.go: MIT © Kevin S. Dias.FAQs
Unknown package
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
Product
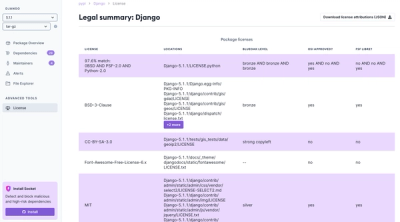
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
Product
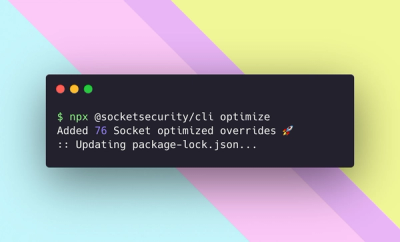
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.