Product
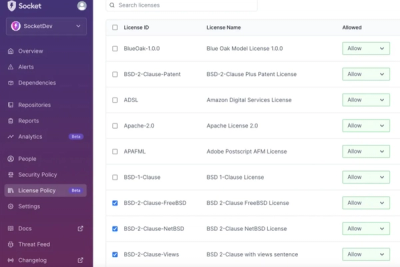
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
com.github.zherebjatjew:xml-machine
Advanced tools
State machine builder for parsing XML based ont StaX
Stream XML parsers are in general faster than DOM-based parsers and less memory consuming. However, they have significant drawbacks:
This library helps to solve at least the first problem. It provides to you an instrument for building a state machine and easily operate with xml nodes respecting document structure.
There are two main components: state machine builder and xml parser.
The parser takes the state machine and runs it against given XML.
Parser can use any Stax-based xml reader. In tests, I use the native one,
java.xml.stream.XMLStreamReader.
Let's go to the code. Imagine you have an xml:
<library>
<book language="en">
<title>American Gods</title>
<author>Neil Gaiman</author>
</book>
<book language="pl">
<author>Chuck Palahniuk</author>
<title>Fight Club</title>
</book>
</library>
and you need to print out authors and titles. With the tool you can do it easily:
try (StringReader reader = new StringReader(xml) {
StaxParser parser = new StaxParser(XMLInputFactory.newInstance()
.createXMLStreamReader(reader));
parser.read(RootHandler.instance(
"library", r -> r.then("book")
.or("author", x -> x.text(System.out::println))
.or("title", x -> x.text(System.out::println)))
);
}
it will print out
American Gods
Neil Gaiman
Chuck Palahniuk
Fight Club
You can notice that it is not quite fancy because authors and titles go in a random order. What if you have to prepare a CSV where first column contains authors and second column contains book titles?
To solve that we can take advantage of a powerful feature called propagation. It tells the machine to publish text of a node to its parent.
try (StringReader reader = new StringReader(xml) {
StaxParser parser = new StaxParser(XMLInputFactory.newInstance()
.createXMLStreamReader(reader));
parser.read(RootHandler.instance(
"library", r -> r.then("book")
.or("author", x -> Handler::propagate)
.or("title", x -> Handler::propagate)
.close(book -> System.out.println(book.getProperty("author") + ',' + book.getProperty("title"))))
);
}
Output:
Neil Gaiman,American Gods
Chuck Palahniuk,Fight Club
Values can be propagated further. In this case their names get path reflecting source of the value.
E.g., in the snippet above, if you propagated book node, you can address values from library node
as book/author and book/title.
By default, the parser skips attributes for the sake of performance. You can turn on attribute fetching explicitly for separate nodes.
Attributes can be propagated. Let's filter from our books only English versions. Notice
new withAttributes instruction, and that attribute is referenced with '@' prefix.
try (StringReader reader = new StringReader(xml) {
StaxParser parser = new StaxParser(XMLInputFactory.newInstance()
.createXMLStreamReader(reader));
parser.read(RootHandler.instance(
"library", r -> r.then("book").withAttributes()
.or("author", x -> Handler::propagate)
.or("title", x -> Handler::propagate)
.close(book -> {
if ("en".equals(book.getProperty("@language") {
System.out.println(book.getProperty("author") + ',' + book.getProperty("title"))))
}
}
);
}
The example above can be implemented in more concise way by using assumptions.
try (StringReader reader = new StringReader(xml) {
StaxParser parser = new StaxParser(XMLInputFactory.newInstance()
.createXMLStreamReader(reader));
parser.read(RootHandler.instance(
"library", r -> r.then("book").withAttributes()
.assume(f -> "en".equals(f.getProperty("@language"))
.or("author", x -> Handler::propagate)
.or("title", x -> Handler::propagate)
.close(book -> System.out.println(book.getProperty("author") + ',' + book.getProperty("title"))))
);
}
Handler#then, Handler#or.FAQs
State machine builder for parsing XML based ont StaX
We found that com.github.zherebjatjew:xml-machine demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
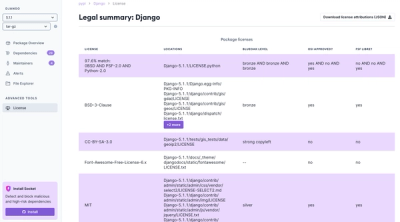
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
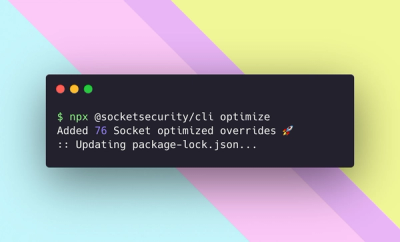
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.