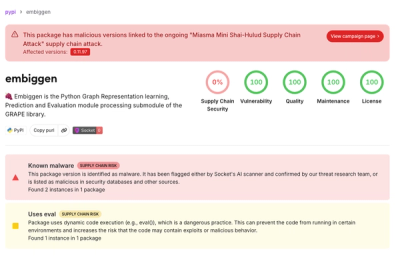
Legion
Orchestrate 49 AI specialist personalities across 10 AI CLI runtimes plus the Kilo Code plugin.
"My name is Legion, for we are many."
What It Does
Turn 49 isolated agent personalities into a coordinated legion. The native Legion entry point now depends on the runtime you install into. See the audited compatibility matrix in docs/runtime-audit.md before assuming /legion:* works everywhere.
Installation
Quick install (recommended)
npx @9thlevelsoftware/legion --claude
Replace --claude with your runtime of choice:
--claude | Claude Code |
--codex | OpenAI Codex CLI |
--cursor | Cursor |
--copilot | GitHub Copilot CLI |
--gemini | Google Gemini CLI |
--antigravity | Antigravity CLI |
--kiro | Kiro CLI (preferred) |
--amazon-q | Deprecated alias for --kiro |
--windsurf | Windsurf |
--opencode | OpenCode |
--kilo | Kilo CLI |
--kilo-code | Kilo Code Plugin |
--kilocode | Alias for --kilo-code |
--aider | Aider (manual-only; native install disabled) |
Runtime Support Tiers
| Claude Code | Certified | Control runtime with native Legion slash commands, agents, and skills |
| OpenAI Codex CLI | Beta | Native prompt commands plus a Legion bridge skill; use /project:legion-start or /prompts:legion-start |
| GitHub Copilot CLI | Beta | Native /legion-start skills plus a legion-orchestrator agent profile |
| Google Gemini CLI | Beta | Native /legion:start custom commands in .gemini/commands/legion/ |
| Antigravity CLI | Certified | Native /legion:start plugins in .agents/plugins/legion/ (local) or ~/.gemini/config/plugins/legion/ (global) |
| Kiro CLI (formerly Amazon Q Developer CLI) | Beta | Native @legion-orchestrator custom agent plus steering files |
| OpenCode | Beta | Native /legion-start custom commands plus a Legion subagent |
| Kilo CLI | Beta | Native /legion-start custom commands plus a Legion subagent |
| Kilo Code Plugin | Beta | Native Legion custom mode plus Legion workflows and Agent Skills in both .kilocode/ and CLI-backed .kilo/ paths; use --kilo-code instead of --kilo |
| Cursor | Experimental | Local-only rules install in .cursor/rules/; plain-language Legion requests only |
| Windsurf | Experimental | Local-only rules install in .windsurf/rules/; plain-language Legion requests only |
| Aider | Experimental | Manual-only fallback; automated native install is intentionally disabled |
Local development
git clone https://github.com/9thLevelSoftware/legion.git
node bin/install.js --claude
Prerequisites
- Node.js 18+
- One of the 10 AI CLI runtimes listed above or Kilo Code plugin support via
--kilo-code (support tier varies by runtime)
Codex note
If you install with --codex, Legion writes its workflow files into .legion/, installs native prompt commands into .codex/prompts/ for local installs or ~/.codex/prompts/ for global installs, and also installs a legion bridge skill into .agents/skills/legion/.
- Local Codex installs appear as
/project:legion-start, /project:legion-plan, /project:legion-build, and so on
- Global Codex installs appear as
/prompts:legion-start, /prompts:legion-plan, /prompts:legion-build, and so on
- Legacy
/legion:* aliases remain bridge-only fallbacks, and plain-language Legion intents still work
Repo-native Codex plugin
This repository now also ships a repo-native Codex plugin manifest at .codex-plugin/plugin.json.
- Use the repo-native plugin path when you want Codex to load Legion directly from this checkout as a local plugin bundle
- The repo-native plugin exposes a top-level
legion bridge skill at skills/legion/SKILL.md, which routes plain-language Legion requests and legacy /legion:* intents to the matching workflow under commands/
- This path is additive: it does not replace or modify the existing
npx @9thlevelsoftware/legion --codex installer flow
- The
npx installer remains the path that writes native Codex prompt commands into .codex/prompts/ or ~/.codex/prompts/
Native entry points
| Claude Code | /legion:start | /legion:start |
| OpenAI Codex CLI | /project:legion-start | /prompts:legion-start |
| GitHub Copilot CLI | /legion-start or /agent legion-orchestrator | /legion-start or /agent legion-orchestrator |
| Google Gemini CLI | /legion:start | /legion:start |
| Antigravity CLI | /legion:start | /legion:start |
| Kiro CLI | @legion-orchestrator | @legion-orchestrator |
| OpenCode | /legion-start | /legion-start |
| Kilo CLI | /legion-start | /legion-start |
| Kilo Code Plugin | Select Legion mode or run /legion-start.md or /legion-start | Select Legion mode or run /legion-start.md or /legion-start |
| Cursor | Plain-language request after local rules install | Not supported |
| Windsurf | Plain-language request after local rules install | Not supported |
| Aider | Manual-only | Manual-only |
Getting Started
- Install Legion (see above)
- Start Legion with the runtime-native entry point from the table above
- Answer the guided questions — or run
/legion:explore first to create a design document
- Review the generated PROJECT.md and ROADMAP.md
- Plan the first phase with the runtime-native Legion plan entry
- Execute the phase with the runtime-native Legion build entry
- Review the phase with the runtime-native Legion review entry
- Repeat plan → build → review for each phase
Commands
These are the canonical Legion command names. Each runtime maps them to its own discovery surface. Codex uses flat prompt names such as /project:legion-start; Gemini keeps /legion:start; Copilot, OpenCode, and Kilo CLI use flat /legion-start; Kilo Code Plugin installs both plugin workflows such as /legion-start.md and CLI-backed workflows such as /legion-start, plus a single Legion mode bridge and individual Agent Skills; Kiro uses @legion-orchestrator; Cursor and Windsurf rely on their installed rules and plain-language intent routing. Nineteen commands total.
/legion:start | Initialize project with guided questioning | Run once at project start |
/legion:plan <N> | Plan phase N with agent recommendations and wave-structured tasks | After start, or after completing a phase |
/legion:build | Execute current phase with parallel agent teams | After planning a phase |
/legion:review | Run QA review cycle with testing/QA agents | After building a phase |
/legion:status | Show progress dashboard and route to next action | Anytime — routes you to the right command |
/legion:quick <task> | Run ad-hoc task with intelligent agent selection | Anytime — for one-off tasks |
/legion:advise <topic> | Get read-only expert consultation from any agent | Anytime — standalone advisory, no phase context needed |
/legion:portfolio | Multi-project dashboard with dependency tracking | When managing multiple projects |
/legion:milestone | Milestone completion, archiving, and metrics | At project milestones |
/legion:agent | Create a new agent personality through guided workflow | When you need a specialist that doesn't exist |
/legion:map | Generate, refresh, check, or query the codebase map dataset | Before start or planning in existing codebases |
/legion:explore | Research-first design discovery with Polymath | Creates a design doc; can hand off to /legion:start <design-doc> when you choose |
/legion:board | Convene board of directors for governance decisions | For architecture decisions, go/no-go calls, conflict resolution |
/legion:retro | Run structured retrospective on completed phases or milestones | After phases or milestones — captures what worked, what didn't |
/legion:ship | Pre-ship checklist, PR creation, deployment verification, canary monitoring | After review — formal shipping stage before the next phase |
/legion:learn | Record, recall, and manage project-specific patterns and preferences | Anytime — operationalizes project memory |
/legion:update | Check for updates and install latest version from npm | After installation — keeps Legion current |
/legion:polish | Run 4-pass code cleanup on changed files or a target path | After review, or anytime via ad-hoc invocation |
/legion:validate | Validate .planning/ state file integrity, schema conformance, and cross-references | Anytime — catches drift and corruption early (supports --ci, --fix) |
How It Works
/legion:start Guided questioning → PROJECT.md + ROADMAP.md
↓
/legion:plan 1 Phase decomposition → Wave-structured plans + agent teams
↓ ↓ (optional)
↓ Plan critique → Pre-mortem + assumption hunting
↓
/legion:build Parallel execution → Agents work in character, wave by wave
↓
/legion:review Quality gate → Review → Fix → Re-review (default max 3 cycles, configurable)
↓ ↓ (optional)
↓ Panel mode → 2-4 domain-weighted reviewers with rubrics
↓ ↓ (post-review, configurable)
↓ Code polish → 4-pass cleanup (comments, simplification, readability, consistency)
↓
/legion:ship Ship pipeline → Pre-ship gates → PR creation → deployment verification
↓
/legion:retro Retrospective → What worked, what didn't, reusable patterns
↓
/legion:plan 2 → ... Repeat for each phase until project complete
/legion:map Standalone → Codebase documentation + semantic index
/legion:explore Standalone → Research + questions + design doc before optional start
/legion:advise <topic> Standalone → Read-only expert consultation (any time)
/legion:quick <task> Standalone → One-off task with agent selection (any time)
/legion:polish [target] Standalone → 4-pass code cleanup with safety rails (any time)
/legion:learn <lesson> Standalone → Record patterns, pitfalls, and preferences (any time)
Claude Opus 4.7 Hardening
Recent releases rewrote large parts of Legion to behave better on Claude Opus 4.7 and other literal, high-context models. The goal was not to flatten the system. It was to lower hot-path prompt weight, tighten interaction contracts, and remove ambiguity that caused retries or drift.
- Lean always-load core:
workflow-common-core now carries the minimum shared contract - adapter detection, state and path resolution, control-mode defaults, and context ceilings. Heavier behavior stays in optional skills.
- Retrieval over preload: AGENTS.md and CLAUDE.md keep a compressed index in context, then commands read the exact agent or skill file they need instead of dragging the full roster into every command.
- Conditional skill loading:
/legion:plan, /legion:build, /legion:review, and /legion:status load codebase-map, GitHub, critique, panel, and domain skills only when their activation conditions are met.
- Prompt-budget enforcement:
wave-executor estimates prompt size before spawning, warns near adapter limits, and blocks oversized launches instead of letting agents fail mid-flight.
- Smaller coordinator context: spawned agents report structured summaries and downstream waves receive focused handoff context rather than full execution traces.
- More deterministic control flow: the v7.3.3 audit replaced vague triggers, free-form gates, and underspecified dispatch wording with concrete activation rules, closed-set AskUserQuestion flows, completion gates, and explicit dispatch tables.
Workflows
Core Workflow: start → plan → build → review
The main loop for any project. Run through these four commands in order, repeating plan → build → review for each phase.
/legion:start — Project Initialization
Guides you through an adaptive conversation (5-8 exchanges) to capture project vision, requirements, and constraints before generating any plans.
Key steps:
- Pre-flight check — detects existing projects and offers to reinitialize or continue
- Design document input — optionally consumes
.planning/explorations/*-design.md from /legion:explore
- Codebase map pre-flight — if source code is found, checks for a fresh
/legion:map dataset and asks whether to use, refresh, skip, or abort
- Vision exploration — 3-stage adaptive conversation via
questioning-flow: vision → requirements → constraints, targeting 5-8 natural exchanges
- Agent recommendation —
agent-registry scores all 49 agents to recommend 2-4 per phase based on keyword match and division affinity
- Document generation — produces
PROJECT.md, ROADMAP.md, and STATE.md using questioning-flow templates
- Portfolio registration — registers the project in the global portfolio via
portfolio-manager at ~/.claude/legion/portfolio.md
Skills invoked: workflow-common-core → questioning-flow → agent-registry → portfolio-manager | codebase-mapper (optional map pre-flight)
Tools: Read, Write, Edit, Bash, Grep, Glob, AskUserQuestion
Produces: .planning/PROJECT.md, .planning/ROADMAP.md, .planning/STATE.md | optional .planning/CODEBASE.md and .planning/codebase/ map artifacts
User interaction: Guided Q&A throughout; confirms generated documents before finalizing
/legion:plan <N> — Phase Planning
Decomposes a roadmap phase into as many wave-structured plans as needed, using the default max of 3 tasks per plan only as a per-plan task cap (configurable via settings). Recommends agents from the 49-agent registry for each plan and gets your confirmation.
Key steps:
- Parse or auto-detect the next unplanned phase from STATE.md
- Load phase context — reads ROADMAP.md requirements, prior phase summaries, and the codebase map if present (retrieves relevant chunks, risk areas, and conventions)
- Detect domain-specific workflows —
marketing-workflows activates for MKT-* requirements (campaign briefs, content calendars), design-workflows activates for DSN-* requirements (design systems, three-lens review)
- (Optional) Architecture proposals — spawns 2-3 read-only Explore agents with competing philosophies (Minimal, Clean, Pragmatic) for complex phases; user selects an approach
- (Optional) Spec pipeline — 5-stage specification process (gather → research → write → critique → assess) producing a structured spec at
.planning/specs/
- Decompose into plans via
phase-decomposer — any number of plans per phase, with the default max 3 tasks per plan applying only inside each plan, grouped into dependency waves (parallel within, sequential between)
- Recommend agents per plan using
agent-registry scoring (keyword match 3pts, division affinity 2pts, partial match 1pt, memory boost from past outcomes)
- (Optional) Plan critique — spawns 2 read-only Explore agents (
testing-qa-verification-specialist for pre-mortem, product-sprint-prioritizer for assumption hunting) with PASS/CAUTION/REWORK verdicts
- Generate plan files with full task instructions, verification commands, and YAML frontmatter
- (Optional) GitHub issue creation via
github-sync — creates a labeled issue with plan checklist
Skills invoked: workflow-common-core → phase-decomposer → agent-registry → memory-manager | codebase-mapper (map context) | marketing-workflows | design-workflows | spec-pipeline | plan-critique | github-sync (all optional)
Tools: Read, Write, Edit, Bash, Grep, Glob, AskUserQuestion
Produces: .planning/phases/{NN}-{slug}/CONTEXT.md and {NN}-{PP}-PLAN.md files | .planning/specs/ (optional) | .planning/campaigns/ (marketing) | .planning/designs/ (design)
User interaction: Confirms agent recommendations; opts into architecture proposals, spec pipeline, and plan critique; reviews critique findings
/legion:build — Phase Execution
Spawns agents with full personality injection to execute all plans for the current phase. Runs waves in parallel, tracks progress, and commits completed work.
Key steps:
- Determine target phase from STATE.md or
--phase N flag; validate plan files exist
- Discover plans via
wave-executor — parse YAML frontmatter, build wave map, validate no circular dependencies or file conflicts
- Create a Claude Code Team via TeamCreate (
phase-{NN}-execution) with TaskCreate for each plan and cross-wave dependencies via TaskUpdate
- Execute plans wave by wave via
wave-executor — all agents within a wave spawn in parallel via Agent tool with model: "sonnet"
- Each agent receives its complete personality .md (currently 156-472 lines) concatenated with the plan file as its prompt; autonomous plans skip personality injection
- Agents auto-remediate environment issues (missing deps, wrong versions) — classify errors as BLOCKER vs ENVIRONMENT, retry once after remediation
- Collect results via SendMessage — parse structured summaries, write
{NN}-{PP}-SUMMARY.md files
- Track progress via
execution-tracker — update STATE.md, ROADMAP.md progress table, create atomic git commits per successful plan
- Record outcomes via
memory-manager (optional) — agent, task type, success/failure, importance score with time-decay
- Detect manual edits — intersect agent-modified files with
git diff to capture corrective preference signals
- Shutdown team via SendMessage shutdown_request + TeamDelete
Skills invoked: workflow-common-core → wave-executor → execution-tracker → memory-manager | codebase-mapper (map context injection) | github-sync (issue checklist + PR creation)
Tools: Read, Write, Edit, Bash, Grep, Glob, Agent, TeamCreate, TeamDelete, TaskCreate, TaskUpdate, TaskList, SendMessage, AskUserQuestion
Produces: Implementation artifacts plus {NN}-{PP}-SUMMARY.md files, atomic git commits, optional GitHub PR
User interaction: Confirms pre-execution plan; monitors progress; resolves blockers if agents get stuck
/legion:review — Quality Review
Selects appropriate review agents for the phase, runs a structured dev-QA loop (default max 3 cycles, configurable), and marks the phase complete only after review passes.
Key steps:
- Determine target phase and load build summaries — reads CONTEXT.md, all PLAN.md and SUMMARY.md files, builds deduplicated file list for review
- Detect manual edits — intersects
git diff with agent-modified files before review begins, stores corrective preferences via memory-manager
- Choose review mode: classic (
review-loop — static phase-type-to-agent mapping) or panel (review-panel — dynamic 2-4 reviewer composition with domain-weighted rubrics)
- Classic mapping: code →
testing-qa-verification-specialist; API → testing-api-tester; design → three-lens review (brand-guardian + ux-architect + ux-researcher); marketing → testing-workflow-optimizer
- Panel mode: scores all review-capable agents via
agent-registry, caps panel size (2 single-domain, 3 standard, 4 cross-domain), enforces max 2 per division + at least 1 Testing agent, assigns non-overlapping rubrics
- Create a Claude Code Team via TeamCreate (
phase-{NN}-review)
- Spawn review agents in parallel — each receives full personality .md + phase context + rubric (panel mode); all agents spawn in a single response via Agent tool with
model: "sonnet"
- Collect findings via SendMessage — parse severity (BLOCKER/WARNING/SUGGESTION), deduplicate across reviewers, triage into must-fix and nice-to-have
- Panel synthesis (panel mode only) — cross-cutting themes, hot spots (files flagged by 2+ reviewers), aggregate verdict
- Route fixes — group findings by file type, spawn appropriate fix agents (frontend →
engineering-frontend-developer, backend → engineering-backend-architect, etc.), create fix commits
- Re-review — scoped to modified files, bounded by configured max cycles (default 3); escalate to user if blockers persist
- On PASS: write
{NN}-REVIEW.md, mark phase complete in STATE.md + ROADMAP.md, close GitHub issue (optional)
- On ESCALATE: present remaining blockers with fix attempt history, offer manual fix / accept-as-is / investigate options
- Shutdown team via SendMessage + TeamDelete
Skills invoked: workflow-common-core → review-loop | review-panel → execution-tracker → memory-manager | design-workflows (three-lens) | github-sync
Tools: Read, Write, Edit, Bash, Grep, Glob, Agent, TeamCreate, TeamDelete, TaskCreate, TaskUpdate, TaskList, SendMessage, AskUserQuestion
Produces: {NN}-REVIEW.md, fix commits, updated STATE.md and ROADMAP.md
User interaction: Chooses review mode; confirms reviewer selection; reviews findings; approves fixes; decides escalation path
Navigation
/legion:status — Progress Dashboard
Single command to understand where the project is and what to do next. Reads all project state and displays a clear dashboard with session resume context.
Key steps:
- Load project state — reads PROJECT.md, STATE.md, ROADMAP.md, REQUIREMENTS.md (if exists)
- Calculate progress via
execution-tracker — 20-char progress bar from ROADMAP.md plan counts
- Display milestone progress via
milestone-tracker (if milestones defined)
- Load memory briefing via
memory-manager (if OUTCOMES.md exists) — last 5 outcomes, top 3 agents by success rate
- Check codebase map status (CODEBASE.md plus
.planning/codebase/ artifacts; suggest /legion:map --refresh if stale or partial)
- Fetch GitHub status via
github-sync (if STATE.md has GitHub section) — live issue/PR/milestone state via gh CLI
- Route to next action — decision tree: no project → start; pending → plan; planned → build; executed → review; complete → next phase or finish
Skills invoked: workflow-common-core → execution-tracker → milestone-tracker | memory-manager | github-sync | codebase-mapper (staleness check)
Tools: Read, Grep, Glob (read-only — no file modifications)
Produces: Dashboard display (no file changes)
User interaction: Follow the suggested next action, or run any command
Ad-hoc
/legion:quick <task> — One-off Task Execution
Run any task outside the normal phase workflow with automatic agent selection. No phase planning required.
Key steps:
- Parse the task description from arguments — works with or without an initialized project
- Load project context (optional) — reads PROJECT.md for tech stack awareness if available
- Score agents via
agent-registry (keyword match 3pts, division affinity 2pts, partial match 1pt) and recommend top 2 candidates
- Spawn the selected agent via Agent tool with
model: "sonnet" and full personality injection — or run autonomously if user prefers
- Return results with an optional conventional commit (auto-detects type: feat/fix/test/docs/refactor from task description)
Skills invoked: workflow-common-core → agent-registry
Tools: Read, Write, Edit, Bash, Grep, Glob, Agent, AskUserQuestion
Produces: Task output plus optional git commit (does NOT update STATE.md or ROADMAP.md)
User interaction: Confirms agent selection; approves commit
/legion:advise <topic> — Expert Consultation
Get read-only strategic advice from any of the 49 agent personalities. The advisor can explore your codebase and ask clarifying questions but cannot modify any files.
Key steps:
- Parse the topic (architecture, UX, marketing strategy, etc.) — provides a topic reference table spanning Engineering, Design, Business, Marketing, Testing, Product, and Spatial Computing
- Load project context from PROJECT.md if available (works without it for pure domain expertise)
- Score and recommend the best advisor via
agent-registry — top 2 candidates presented with match rationale
- Spawn the advisor as a read-only Explore subagent (tool-level enforcement: no Write, no Edit, no Bash) with full personality injection and
model: "sonnet"
- Display structured advice: Assessment → Recommendations → Trade-offs → Next Steps
- Interactive follow-up loop — ask another question (same advisor, carries prior context), switch topics (new advisor), or end session
Skills invoked: workflow-common-core → agent-registry
Tools: Read, Grep, Glob, Agent, AskUserQuestion (advisor spawned as Explore — cannot modify files)
Produces: Advisory output (no file changes, no state updates)
User interaction: Selects advisor agent; asks follow-up questions; ends session when satisfied
/legion:map — Codebase Mapping
Generate, refresh, check, or query the codebase map dataset used by planning, build, review, and status workflows.
Key steps:
- Detect source code and existing map artifacts
- In
--check, report freshness/completeness without writing files
- In default or
--refresh, generate architecture documentation, functionality inventory, dependency graph, API surface, test map, risk hotspots, setup/runbook, and conventions
- Write
.planning/CODEBASE.md, .planning/codebase/index.jsonl, .planning/codebase/symbols.json, .planning/codebase/search.md, and .planning/config/directory-mappings.yaml
- In
--query, search the existing index and return matching chunks plus source files to read next
Skills invoked: workflow-common-core → codebase-mapper
Tools: Read, Write, Edit, Bash, Grep, Glob, AskUserQuestion
Produces: .planning/CODEBASE.md, .planning/codebase/, .planning/config/directory-mappings.yaml
User interaction: Confirms refresh when a fresh map already exists; mapping remains user-approved during /legion:start
/legion:explore — Design Discovery
Run research-first product/design discovery with Polymath before committing to formal project initialization. Explore inspects current project context, researches the initial ask, asks focused clarifying questions, compares approaches, and saves a design document.
Key steps:
- Inspect local project context, codebase map, and prior exploration docs
- Capture or resume the initial ask
- Run bounded local/web research where available
- Ask one material clarifying question at a time via structured choices
- Compare 2-3 viable approaches and capture the selected direction
- Save
.planning/explorations/YYYY-MM-DD-<slug>-design.md
- Ask whether to start with the design, keep discussing, or park it
Skills invoked: workflow-common-core → polymath-engine → questioning-flow
Tools: Read, Write, Edit, Bash, Grep, Glob, AskUserQuestion
Produces: .planning/explorations/*-design.md
User interaction: Answers focused design questions; explicitly chooses whether to hand off to /legion:start <design-doc-path>
Management
/legion:portfolio — Multi-Project Dashboard
Cross-project visibility when managing multiple Legion projects. Shows dependency tracking, agent allocation, and offers strategic coordination from the Studio Producer agent.
Key steps:
- Load the global portfolio registry (
~/.claude/legion/portfolio.md) — validates each project path exists, reads each project's STATE.md and ROADMAP.md
- Display all projects with progress bars, health indicators (
[OK] green / [!!] yellow / [XX] red), sorted by health then recency
- Display cross-project dependencies — checks live phase completion status, flags blocking vs resolved
- Display agent allocation — shared agents across projects, division coverage table (requires 2+ projects)
- Interactive operations: view project details, add cross-project dependencies, invoke Studio Producer analysis
- Studio Producer consultation (optional) — spawns
project-management-studio-producer via Agent tool with model: "opus" for strategic portfolio coordination
Skills invoked: workflow-common-core → portfolio-manager → agent-registry
Tools: Read, Write, Edit, Bash, Grep, Glob, Agent, AskUserQuestion
Produces: Dashboard display; optional portfolio registry updates and Studio Producer analysis
User interaction: Reviews dashboard; adds dependencies; requests strategic coordination; exits when done
/legion:milestone — Milestone Lifecycle
Handles the full milestone lifecycle: define milestone groupings, track status, mark milestones complete with summaries, and archive completed artifacts.
Key steps:
- Load project state — checks for existing
## Milestones section in ROADMAP.md; offers to define milestones if none exist
- Display milestone dashboard via
milestone-tracker — phase-level progress with 10-char progress bars per milestone
- Define milestones — analyzes phases for logical groupings (theme clusters, dependency chains), proposing as many milestones as the roadmap needs with no fixed phase-count limit
- Complete milestone — validates all phases are Complete, generates summary at
.planning/milestones/MILESTONE-{N}.md with metrics (plans, requirements, files, agents), closes GitHub milestone via github-sync (optional)
- Archive milestone — moves phase directories from
.planning/phases/ to .planning/archive/milestone-{N}/, condenses STATE.md, updates ROADMAP.md
Skills invoked: workflow-common-core → milestone-tracker → execution-tracker | github-sync
Tools: Read, Write, Edit, Bash, Grep, Glob, AskUserQuestion
Produces: Updated ROADMAP.md, milestone summaries at .planning/milestones/, archived phase directories at .planning/archive/
User interaction: Selects milestone operation; confirms completion and archiving
/legion:agent — Agent Creator
Create a new specialist agent when the 49 existing personalities don't cover your needs. Guided conversation produces a validated agent .md file and registers it in the catalog.
Key steps:
- Stage 1: Agent Identity — adaptive conversation via
agent-creator to define role, specialty, and division (infers kebab-case name like {division}-{specialty})
- Stage 2: Capabilities & Personality — captures top 3-5 unique capabilities, communication style, and hard rules; shows example agents (engineering, testing, design) for reference
- Stage 3: Registry Tags — generates 3-5 task type tags aligned with existing
agent-registry taxonomy; presents for confirmation
- Schema validation — runs 8 checks (name uniqueness, format regex, description, color, division, 50+ line body, heading check, name in body); blocks until all pass
- Generate files — writes agent .md file to
agents/ with YAML frontmatter + substantive personality (80-120 lines), inserts catalog row into agent-registry
- Git commit — stages agent file + registry update
Skills invoked: workflow-common-core → agent-creator → agent-registry
Tools: Read, Write, Edit, Bash, Grep, Glob, AskUserQuestion
Produces: New agent personality file in agents/, updated agent-registry SKILL.md
User interaction: Guided 3-stage Q&A; reviews and confirms the generated personality and registry tags
v2.0 Advisory Features
Three capabilities shipped in v2.0 that extend the core workflow with read-only analysis and multi-perspective review.
Strategic Advisors (/legion:advise)
Lightweight expert consultation without the overhead of phase workflows or the risk of code changes.
- Read-only by design — advisors are spawned as Explore agents (tool-level enforcement: no Write, no Edit, no Bash)
- Topic-based agent selection — the registry algorithm scores all 49 agents against the topic and recommends the best match
- Full personality injection — the advisor operates in complete character with its specialist expertise, communication style, and hard rules
- Project-aware — loads PROJECT.md context when available, but works without it for pure domain expertise
- Interactive follow-up — after initial advice, continue with follow-up questions, switch topics, or end the session
- No state changes — advisory sessions never update STATE.md, ROADMAP.md, or any project files
Dynamic Review Panels
Context-aware multi-perspective review teams that replace static reviewer mapping with dynamic composition.
- 2-4 reviewers — panel size scales with domain complexity: 2 for single-domain, 3 for standard, 4 for cross-domain phases
- Domain-weighted rubrics — each reviewer evaluates against 3-5 non-overlapping criteria specific to their specialty (Production Readiness, Verification Completeness, Brand Consistency, etc.)
- No criterion overlap — rubric design ensures reviewers check different aspects of the work, not the same things from different angles
- Diversity enforcement — max 2 reviewers from the same division; at least one Testing agent on every panel
- Cross-cutting synthesis — findings are deduplicated across reviewers, hot spots identified (files flagged by 2+ reviewers), and an aggregate verdict computed
- Panel vs. classic mode — users choose during
/legion:review; classic mode uses the original static phase-type-to-agent mapping
Plan Critique
Pre-execution stress testing that catches plan weaknesses before agents start building.
- Pre-mortem analysis — assumes the phase has already failed and works backward to identify 3-5 specific failure scenarios with root causes, likelihood, and impact scores
- Assumption hunting — extracts 5-10 implicit assumptions from the plan, rates each by impact and evidence strength, and flags critical ones (high impact + weak evidence)
- Three verdicts — PASS (proceed), CAUTION (addressable risks, review mitigations), REWORK (plan needs revision)
- Maps to plan sections — every finding traces to a specific task in a specific plan file with an actionable mitigation or challenge action
- Optional step — activates when the user selects it during
/legion:plan; does not run automatically
- Read-only agents — critique agents are spawned as Explore subagents to prevent plan modification
v6.0 Discipline & Intelligence
v6.0 transforms Legion from a working orchestration protocol into a disciplined, observable, and smarter one. Twelve phases of improvements across plan safety, agent intelligence, advanced exploration, and release hardening.
Plan Schema Hardening
Plans now include three contract fields in YAML frontmatter that enforce discipline at planning time:
files_forbidden — Glob patterns for files the plan must NOT touch. Prevents scope creep across plan boundaries (e.g., agents modifying shared config that belongs to another plan).expected_artifacts — Explicit output contracts listing every file the plan must produce. Missing artifacts trigger warnings during review.verification_commands — Mandatory bash commands that prove the plan's work succeeded. Plans missing verification commands are flagged as BLOCKER by plan-critique. Every plan is now provably complete, not just asserted complete.
Wave Safety
Two mechanisms prevent file conflicts during parallel wave execution:
- File overlap detection — Plan-critique scans all plans within a wave and flags BLOCKER when two plans list overlapping
files_modified. Caught at planning time, not during a broken build.
sequential_files — Wave metadata can declare files that require single-agent access. The wave executor serializes dispatch for plans sharing sequential files, even within a parallel wave.
Control Modes
Four presets adjust how strictly authority matrix rules are enforced, set via settings.json:
autonomous | Full agent freedom. Authority boundaries off. For trusted workflows and rapid prototyping. |
guarded (default) | Authority boundaries active, domain-filtered reviews, escalation protocol enforced. |
advisory | Read-only mode. Agents suggest but don't execute. All findings shown unfiltered. |
surgical | Maximum restriction. Agents only touch explicitly listed files. All out-of-scope changes blocked. |
Mode profiles are defined in .planning/config/control-modes.yaml. See docs/control-modes.md for detailed usage.
Observability
Two additions provide audit trails for agent decisions:
- Decision logging in SUMMARY.md — Each plan summary now includes an "Agent Selection Rationale" section with recommendation scores, adapter used, and confidence levels. Understand why agents were chosen, not just which ones.
- Cycle-over-cycle diff in REVIEW.md — Each review cycle records a "Cycle Delta" section showing what changed between review rounds. Track whether review cycles are making progress or spinning.
Agent Metadata Enrichment & Recommendation Engine v2
All 49 agent frontmatter files now include structured metadata:
languages: [javascript, typescript, python]
frameworks: [node, express, react]
artifact_types: [code, tests, documentation]
review_strengths: [code-quality, reliability, test-coverage]
The recommendation engine scores against these fields (not just keywords and division affinity), producing more accurate agent-task matches. Outcomes recorded with task_type classification enable archetype-weighted boosts — agents that historically succeed at similar task types get priority.
Adapter Conformance & Validation
- Adapter schema conformance tests — All 10 adapters validated for required fields
- Cross-reference validation — Command files verified to reference existing skills and agents (no dead references)
lint-commands test — Catches orphan tags and broken references in command .md files- New adapter fields —
max_prompt_size and known_quirks in ADAPTER.md spec, so skills can adapt behavior per-runtime
Codebase Mapper Enrichment
The codebase map (/legion:map → codebase-mapper) produces .planning/CODEBASE.md plus semantic index artifacts under .planning/codebase/:
- Dependency Risk — Identifies outdated packages, unmaintained dependencies, and heavy transitive dependency trees. Ranks by risk score (staleness + popularity + security advisories).
- Test Coverage Correlation — Maps untested files against fan-in (how many other files depend on them) and complexity. High fan-in + no tests = highest risk. Degrades gracefully when coverage data is unavailable.
- Semantic Search Index — Stores chunk summaries, aliases, symbols, related files, and search protocol for map-aware command context without embeddings or a vector database.
Polymath Design Discovery
/legion:explore now uses a single research-first design discovery flow. It saves a design document under .planning/explorations/ and offers /legion:start <design-doc-path> only after the user explicitly chooses to start.
Authority & Conflict Resolution
- Escalation automation protocol — Structured
<escalation> blocks with severity, type, decision context, and alternatives. Defined in .planning/config/escalation-protocol.yaml.
- Agent-to-agent communication conventions — Forward-only handoff context in SUMMARY.md files, escalation inheritance across waves, and agent discovery (every agent knows its wave position, peers, and authority domains). Defined in
.planning/config/agent-communication.yaml.
Intent Routing v2
- Natural language intent parsing — Ambiguous inputs are parsed to command + flags (e.g., "fix the tests" routes to
/legion:review, "add a new agent" routes to /legion:agent).
- Context-aware suggestions — The intent router considers current STATE.md position when recommending actions. If you're post-build, it suggests review. If you're between phases, it suggests planning.
v7.0 Governance & Cross-CLI Dispatch
v7.0 adds a governance layer and cross-CLI orchestration to Legion. Claude Code can now convene boards of directors for high-stakes decisions and dispatch work to Gemini CLI and Codex CLI based on capability matching.
Board of Directors
A governance escalation tier for decisions that matter too much for routine review:
- Dynamic composition — Board members are assembled from Legion's 49 agents by the recommendation engine, scored by topic relevance. No fixed director roles.
- 5-phase deliberation — Independent assessment (parallel, dispatch-aware) → structured discussion (2 rounds) → final vote (with confidence scores) → resolution (supermajority formula) → persistence (auditable artifact trail).
- Two modes —
/legion:board meet <topic> for full deliberation with voting; /legion:board review for quick parallel assessments without deliberation.
- Cross-CLI assessments — Board assessments can be dispatched to Gemini (for UX evaluation) or Codex (for implementation feasibility) via the dispatch layer.
Cross-CLI Dispatch
Infrastructure enabling Claude Code to route work to external CLIs as subagents:
- Capability-based routing — Each CLI declares capabilities (e.g., Gemini:
ui_design, web_search; Codex: code_implementation, testing). Tasks are matched to the best-fit CLI automatically.
- File-based handoff — Prompts and results flow through
.planning/dispatch/ files. Auditable, reliable, works across all CLIs.
- Control-mode-aware — Dispatch behavior adapts to the current control mode. In
surgical mode, external CLIs are restricted to read-only assessments.
- Graceful fallback — If an external CLI isn't installed, the dispatch layer falls back to an internal Claude Code agent with a warning.
Enhanced Review System
- Multi-pass evaluators — Four specialized evaluator types (Code Quality, UI/UX, Integration, Business Logic) with domain-specific rubrics. Each evaluator runs 6-7 focused passes in a single invocation.
- Anti-sycophancy rules — Injected into all review agent prompts: no performative agreement, pushback expected, every finding must include file:line + what/why/how-to-fix, clear verdict mandatory.
- Structured review requests — Review context is auto-populated from build phase SUMMARY.md files, giving reviewers complete scope without manual assembly.
v7.1.0 Shipping, Learning & Consolidation
v7.1.0 completes the core workflow loop with three new commands and tightens the agent roster through consolidation.
New Commands
/legion:ship — Pre-ship checklist, PR creation, deployment verification, and canary monitoring. The formal shipping stage between review and the next phase./legion:retro — Structured retrospective on completed phases or milestones. Captures what worked, what didn't, and reusable patterns. Feeds learnings back into future planning via RETRO.md consumption./legion:learn — Record, recall, and manage project-specific patterns, pitfalls, and preferences. Operationalizes cross-session memory outside the build/review cycle.
Agent Consolidation (53→49→48)
Four agent merges in v7.1.0 reduced the roster from 53 to 49. v7.2.0 merged one more, bringing the total to 48 agents across 9 divisions. v7.5.0 added the Code Polisher specialist (see below), bringing the current total to 49.
v7.2.0 Agent Depth, Security & Infrastructure
v7.2.0 is the largest single release: 61 files changed across agent enrichment, security hardening, new commands, and 2026 tech integration. All features default to off — zero behavioral change for existing users.
Agent Enrichment
10 thin agents (88-131 lines) enriched to 200-338 lines with domain-specific depth: code review rubrics, refactoring frameworks, spatial interaction patterns, Livewire lifecycle edge cases, growth experiment templates, and more. Merge of data-analytics-reporter + support-analytics-reporter into data-analytics-engineer.
Security Hardening
- Dependency vulnerability scanning — 6 package ecosystems (npm, pip, cargo, go, maven, gems) with severity classification and remediation guidance
- Secret detection — 12+ patterns (API keys, tokens, credentials, private keys) with file-type-specific scanning
- Supply chain checks — Lockfile integrity, typosquatting detection, unmaintained dependency flagging
- Post-execution boundary verification — Authority-enforcer now validates that agents stayed within their
files_modified scope after execution. Guarded mode warns; surgical mode auto-reverts
New Command: /legion:validate
State file integrity checker for .planning/ artifacts. Validates schema conformance, cross-references between plans and state, and detects corruption. Supports --ci flag for pipeline integration and --fix for auto-remediation.
Quick Command Enhancement
--fix flag — Inline review + PR creation in a single command (replaces the proposed /legion:hotfix command). Includes GitHub issue linking support.
Plan Auto-refinement
--auto-refine flag on /legion:plan — Automatic re-planning when plan critique returns CRITICAL findings. Max 2 refinement cycles with user fallback if issues persist.
Memory Pruning
OUTCOMES.md pruning with archive mechanism. Old outcomes are compressed and archived rather than deleted, keeping the active memory table lean. --prune flag on /legion:learn, with configurable auto_prune, prune_threshold, and prune_age_days settings.
Git Worktrees (opt-in)
Opt-in filesystem isolation during parallel agent waves via execution.use_worktrees setting. Full worktree lifecycle: create per-agent → spawn in isolation → merge back with conflict detection → cleanup. Relaxes files_modified disjointness constraint when active; sequential_files constraint preserved for merge-order safety.
Structured Output Schemas
JSON Schema validation files at docs/schemas/ for four core artifact types:
plan-frontmatter.schema.json — Validates PLAN.md YAML frontmattersummary.schema.json — Structured SUMMARY.md content modeloutcomes-record.schema.json — Single OUTCOMES.md record validationreview-finding.schema.json — Review finding structure with severity/status enums
Claude Code Hooks Integration
New hooks-integration skill defining opt-in hook configurations for lifecycle automation:
- Pre-build plan validation
- Post-build notification
- Pre-ship security gate
- Installation guide, integration matrix, graceful degradation guarantees
Extended Thinking for Planning
models.planning_reasoning setting (default: false) enables deeper requirement analysis, wave ordering rationale, and research synthesis in phase-decomposer and polymath-engine. Requires adapter supports_extended_thinking capability.
Dynamic Knowledge Index (Context Engineering)
A compressed directory index embedded in AGENTS.md and CLAUDE.md that maps every agent and skill file by division/category using a pipe-delimited format. Paired with a retrieval-led reasoning directive that shifts the LLM's default from pre-trained knowledge to file retrieval.
Based on Vercel's Context Engineering research, which showed that an always-in-context compressed index achieves 100% tool-use success vs. 53-79% for skills-based approaches. The mechanism: removing the decision to consult documentation eliminates the failure mode entirely.
Three reinforcement layers:
- AGENTS.md / CLAUDE.md — the index is always in context with the "Prefer retrieval-led reasoning" directive
- wave-executor Step 2 — personality file read is labeled
RETRIEVAL-LED — MANDATORY with explicit failure mode description
- workflow-common-core — Personality Injection core contract states retrieval-led reasoning is non-negotiable
A generator script (scripts/generate-knowledge-index.js) rebuilds the index when agents or skills change. The --patch flag updates both AGENTS.md and CLAUDE.md in-place. The agent-creator skill calls this automatically after creating new agents.
v7.5.0 Code Polish ("Deslopping")
v7.5.0 adds automated code cleanup to the post-review pipeline and as a standalone command. The Code Polisher agent runs a structured 4-pass rubric that removes AI-generated slop — excessive comments, over-engineered patterns, inconsistent naming, and redundant abstractions — with safety rails that revert any file whose tests regress.
/legion:polish
Standalone command for ad-hoc code cleanup on any target path, phase files, or the current working directory.
- 4-pass rubric — Comment Cleanup → Code Simplification → Readability Refactoring → Consistency Normalization
- Severity split — Each pass has auto-apply actions (safe mechanical fixes) and flag-for-review actions (judgment calls presented to the user)
- Safety rails — Runs project tests before and after polish. Any file that causes test regression is reverted automatically. Type checker verification when available
- Convention detection — Merges conventions from three sources: CLAUDE.md explicit rules > CODEBASE.md detected patterns > code sampling implicit conventions
- Scope control —
--scope=changed (current phase files only), --scope=dependents (changed + direct importers, default), --scope=directory (full directory tree). Hard cap at 50 files
Review Pipeline Integration
When review.polish is enabled in settings (default: true), /legion:review automatically runs the code polish skill as a post-review step after the QA loop passes. This is non-blocking — polish failures never prevent phase completion.
- Configurable scope —
review.polish_scope setting controls how many files are polished: changed, dependents (default), or directory
- New agent —
testing-code-polisher (#49) joins the Testing division with specialized review strengths: code-clarity, comment-quality, naming-conventions, structural-simplification, convention-consistency
- New skill —
code-polish provides the reusable 4-pass engine consumed by both the command and the review integration
v8.0.3 Codebase Map & Design Discovery
v8.0.3 separates codebase understanding from idea exploration. Codebase mapping is now a first-class, queryable dataset, while exploration is a research-first design conversation that produces a design document before any project initialization.
/legion:map
/legion:map owns architecture documentation and retrieval context for existing codebases.
- Modes — default full map,
--check freshness check, --refresh rebuild, --scope <path> focused mapping, and --query <text> readback against the existing index.
- Dataset — writes
.planning/CODEBASE.md for human readers plus .planning/codebase/index.jsonl, .planning/codebase/symbols.json, .planning/codebase/search.md, and .planning/config/directory-mappings.yaml.
- Freshness metadata — records generated time, analyzed commit, source file count, source fingerprint, scope, and map schema version so commands can detect stale or partial maps.
- Semantic search without services — no embeddings, vector database, or API key dependency. Commands search summaries, aliases, symbols, keywords, and paths with
rg, then read original source lines for evidence.
- Consumer protocol —
/legion:plan, /legion:build, /legion:review, /legion:status, and /legion:quick retrieve relevant chunks instead of assuming all context comes from CODEBASE.md.
/legion:start Map Preflight
/legion:start now checks for source code before project setup. If a codebase exists, it checks map freshness and asks whether to use the current map, refresh it, skip mapping for this start, or abort and run mapping manually. Start can also consume a saved exploration design document via /legion:start <design-doc-path>.
/legion:explore
/legion:explore is no longer a mode picker and no longer starts projects automatically. Polymath now runs one design-discovery path: inspect context, research the ask when tools are available, ask one high-signal clarification at a time, compare 2-3 viable approaches, and save .planning/explorations/YYYY-MM-DD-<slug>-design.md. The final choice is explicit: start with the design, keep discussing, or park it.
Release Coverage
- Command lint and cross-reference coverage now includes
commands/map.md.
- Installer smoke tests verify
/legion:map appears in Codex prompts and flat-command runtime surfaces.
- Map-specific regression tests cover required artifacts, freshness metadata, consumer references, and explore/start decoupling.
Standing on the Shoulders of Giants
Legion didn't invent its patterns from scratch. It cherry-picked the best ideas from twelve proven Claude Code projects, combined them into something greater than the sum of its parts, and left behind the complexity that made each hard to adopt.
What We Took (and What We Left Behind)
Legion now ships 49 built-in personalities: 51 originated in the agency-agents repository by msitarzewski, plus 4 Legion-native specializations, consolidated from the original 55 via 5 agent merges and 1 addition (Code Polisher, v7.5.0). These are not generic role labels — they are structured character sheets (current range 156-472 lines) with deep expertise, communication styles, hard rules, and personality quirks across 9 divisions. Legion builds orchestration, planning, and review workflows on top of this personality foundation.
Took: The conversation engine and state management philosophy.
GSD's adaptive questioning flow is the gold standard for understanding what a user actually wants before jumping to implementation. We adopted its 3-stage pattern (vision → requirements → constraints) where the conversation explores the why before the what, targeting 5-8 natural exchanges rather than rigid checklists. GSD's .planning/ directory with human-readable markdown state files (PROJECT.md, ROADMAP.md, STATE.md) became our foundation — no databases, no JSON blobs, just files you can read with cat.
We also adopted GSD's orchestrator/subagent split: a coordinator manages the workflow while specialized agents do the actual work, each in a fresh context window so they don't get confused by accumulated state.
Left behind: GSD's 33+ workflow files, custom CLI tooling (gsd-tools.cjs), complex configuration system, and heavyweight milestone management. GSD is powerful but requires significant setup. We wanted the patterns without the infrastructure.
Took: The evaluate-loop and quality gate architecture.
Conductor's build → review → fix cycle is the right way to ensure quality. Our review-loop.md skill implements this as a structured dev-QA loop: review agents provide specific, actionable feedback (not vague "looks good"), fixes are applied, and re-review confirms the fix — with a hard cap of 3 cycles before escalating to the user. No infinite retry loops.
Conductor's parallel dispatch pattern — spawning multiple specialized evaluators simultaneously — became our wave execution model. And its concept of typed evaluators (different reviewers for different work) became our phase-type mapping: code gets the QA Verification Specialist, design gets the three-lens review (brand + accessibility + usability), marketing gets Workflow Optimizer, and so on.
Left behind: Conductor's board-of-directors governance model (5 directors debating is overkill for most projects), file-based message bus IPC, 50+ iteration limits, and metadata.json state tracking. Conductor optimizes for correctness through redundancy; we optimize for shipping through focused review.
Took: Wave-based execution, plan constraints, and atomic commits.
Shipyard's wave model is elegant: organize plans into dependency waves, execute everything within a wave in parallel, then advance to the next wave. This gives you maximum parallelism without dependency conflicts. We adopted it directly in wave-executor.md.
Shipyard's small-plan discipline keeps work focused and reviewable. Legion keeps that as a configurable per-plan task cap, but does not cap how many plans a phase may contain; additional plans improve traceability when dependency or verification boundaries require them.
Atomic commits per completed plan (from Shipyard's execution-tracker) means every unit of work is independently revertable. If Plan 2 breaks something, you can roll back without losing Plan 1's progress.
Left behind: Shipyard's 29 commands, checkpoint/rollback system, and complex hook infrastructure. Shipyard is a full project management platform; we just wanted its execution discipline.
Took: The plugin architecture and agent contract.
Best Practice's .claude/ directory structure (commands → skills → agents) is the canonical way to build Claude Code plugins. We adopted it wholesale: commands are entry points, skills are reusable logic, agents are personalities. Clean separation of concerns.
Best Practice's agent frontmatter schema (YAML with name, description, color, division) became our agent contract. Every one of our 49 agents follows this structure, which means the agent-registry.md can programmatically catalog and recommend agents based on structured metadata rather than parsing free-form text.
Left behind: Best Practice's RPI workflow (too domain-specific) and custom hooks infrastructure. We kept the architecture patterns and dropped the opinionated workflows.
Took: The semantic memory architecture.
Daem0n-MCP proved that AI agents can learn across sessions through structured outcome tracking with importance scoring and time-based decay. We adopted its core memory primitives — store, recall, and decay — as our memory-manager.md skill. After each build/review cycle, outcomes are recorded with agent ID, task type, success/failure, and importance score. During future planning, past outcomes are queried to boost agent recommendations, weighted by a 4-bracket decay curve (1.0 for recent, down to 0.1 for old) so the system improves over time without getting stuck in historical patterns.
The key insight from Daem0n was computing decay at recall time rather than destructively aging stored data. This means the full outcome history is always preserved — you can audit every decision — while relevance scoring adapts naturally as time passes.
Left behind: Daem0n's hook-driven architecture (memory operations triggered automatically on every tool call) and MCP server dependency. Our memory layer is called explicitly by Legion workflows and stored as a single markdown table at .planning/memory/OUTCOMES.md — no server process, no hooks, no background sync. Everything degrades gracefully if the memory file doesn't exist.
Took: Confidence-based review filtering and competing architecture proposals.
Feature-dev's review system uses 80%+ confidence thresholds — reviewers only report findings they're genuinely confident about, avoiding the noise of speculative warnings. We adopted this principle in our review agents' instructions: report specific, actionable findings, not vague "looks good" or hedged suggestions. Feature-dev's competing architecture designs (2-3 approaches evaluated before implementation) became our architecture proposals in /legion:plan step 3.5, where read-only Explore agents with Minimal, Clean, and Pragmatic philosophies present trade-offs for the user to evaluate.
Left behind: Feature-dev's 3-agent-only model (explorer, architect, reviewer), lack of state persistence between sessions, and no quick/ad-hoc task mode.
Took: Anti-rationalization discipline and evidence-backed verification.
Code-foundations' anti-rationalization tables — explicit boundaries for what agents decide autonomously vs. what requires human approval — became our Authority Matrix. The principle that agents should never rationalize "it's a small change" to bypass approval is baked into our escalation protocol. Evidence-backed checklists (every claim must be verifiable) became our plan verification commands: each task in a plan file has a <verify> block with specific commands to run, so completion is provable, not asserted.
Left behind: The 614-check pipeline (our agents run focused verification per task, not exhaustive checklists), the heavy token consumption from running every check on every file, and the rigid pipeline structure that doesn't adapt to project type.
Took: Git-native state and actor-based audit trails.
Beads proved that git is the right state management layer for AI agent systems — not SQLite, not JSON, not custom databases. All Legion state lives in .planning/ as markdown files tracked by git: every state change is a commit, every decision is auditable via git log, and rollback is just git revert. Beads' actor-based audit trails — tracking which agent did what and why — became our SUMMARY.md files (per-plan execution reports) and OUTCOMES.md (cross-session agent performance tracking).
Left behind: Beads' scope creep (it tries to be a full development framework), the MEOW naming convention, and the $100+/hour cost profile that makes it impractical for most projects.
Took: Multi-stage spec pipeline and environment auto-remediation.
Auto-Claude's spec pipeline — a structured multi-stage process that produces detailed specifications before code generation — became our spec-pipeline skill available as an optional step in /legion:plan. The 5-stage process (gather → research → write → critique → assess) ensures agents build against a validated spec rather than vague requirements. Auto-Claude's environment auto-remediation patterns — detecting and fixing missing dependencies, wrong versions, and missing directories during execution — were adopted directly in our wave-executor agent prompts as the BLOCKER/ENVIRONMENT error classification system.
Left behind: The 1,751-file codebase, the Python-Electron architecture split, the 50-iteration QA cycles, and the complex worktree isolation system. We kept the spec discipline and resilience patterns without the infrastructure weight.
Took: Verification points and stale loop detection.
Bjarne's verification points — mandatory checks after each step that prevent agents from proceeding on broken state — became our <verify> blocks in plan task definitions. Every task has a verify command that must pass before the agent moves to the next task. Bjarne's stale loop detection — recognizing when an agent is retrying the same failing action — informed our hard cap of 3 review cycles: if the dev-QA loop hasn't resolved blockers after 3 rounds, the problem is systemic and gets escalated to the user rather than spinning indefinitely. Bjarne's verbose output redirection (redirect noisy build output to temp files, show only on failure) is adopted in our agent execution resilience instructions.
Left behind: The 2,500 lines of Bash (we use zero shell scripts), the absence of any test suite, and the single-file architecture that made it hard to extend.
Took: Preference extraction and debate-with-winner-tracking.
Puzld.ai's DPO (Direct Preference Optimization) extraction pattern — capturing which of several competing options the user prefers — became our preference capture system in memory-manager Section 13. When the user selects an architecture proposal, overrides a review finding, or manually edits agent output, Legion records the decision as a preference signal (positive, corrective, or negative) that informs future recommendations. Puzld.ai's debate-with-winner-tracking — presenting multiple approaches and recording which one wins — maps directly to our competing architecture proposals and agent selection confirmation, where the user's choice is stored as a signal.
Left behind: The near-zero test coverage, the 95 releases in 3 months (velocity without stability), and the DPO-specific terminology that made the system harder to understand.
What Legion Added
Beyond combining these twelve projects, Legion introduced several original patterns:
-
Personality-first agents: The 49 agent personalities are not role labels — they are 156-472 line character sheets with expertise, communication style, hard rules, and personality quirks, all in a standardized emoji-headed format. When an agent is spawned, it receives its complete personality as system instructions, not a generic "you are a backend developer" prompt.
-
Hybrid agent selection: The workflow recommends agents based on task analysis (keyword matching, division affinity, past performance), but the user always confirms or overrides. No black-box assignment.
-
Lean core + conditional loading: The always-load surface is intentionally small (workflow-common-core), while domain, GitHub, critique, panel, and codebase-map skills only load when their preconditions are met. This keeps the orchestration path lighter on large models without flattening Legion's feature set.
-
Domain-specific workflow detection: When /legion:plan encounters marketing requirements (MKT-) or design requirements (DSN-), it automatically switches to domain-specific wave patterns and team assembly — campaign planning with content calendars for marketing, design systems with three-lens review for design — instead of forcing engineering patterns onto non-engineering work.
-
Graceful degradation everywhere: GitHub integration, cross-session memory, codebase mapping, marketing workflows, and design workflows are all opt-in features that activate when their prerequisites exist and skip silently when they don't. The core workflow (start → plan → build → review) works identically with or without any optional feature.
-
Audit-hardened interaction contracts (v7.3.3): A Claude Opus 4.7 audit drove 226 fixes across 91 files. User gates are now closed-set AskUserQuestion flows, activation triggers are concrete, dispatch tables spell out when, why, how many, and by what mechanism, and critical skills declare explicit completion gates.
-
Cross-session memory with decay: After each build/review cycle, outcomes are recorded with importance scores and task_type classification. During future planning, past outcomes boost agent recommendations — with time-based decay (recent outcomes matter more) and archetype-weighted boosts (agents that succeed at similar task types get priority).
-
Plan contracts (v6.0): files_forbidden, expected_artifacts, and mandatory verification_commands in plan frontmatter enforce discipline at planning time. File overlap detection and sequential_files prevent parallel execution conflicts.
-
Control modes (v6.0): Four presets (autonomous, guarded, advisory, surgical) adjust authority enforcement per-project, from full agent freedom to maximum restriction where agents only touch explicitly listed files.
-
Structured agent metadata (v6.0): All 49 agents include languages, frameworks, artifact_types, and review_strengths in frontmatter, enabling metadata-aware recommendation scoring instead of keyword-only matching.
-
Design discovery (v6.0, redesigned in v8.0.3): /legion:explore researches an idea, asks focused clarification questions, compares approaches, and saves a design doc before optional project initialization.
Design Choices and Tradeoffs
Legion intentionally optimizes for orchestration ergonomics (few commands, markdown-first state, personality injection) and, after the v7.3.3 audit pass, lower hot-path context cost on literal models over strict uniformity across all runtimes. The table below summarizes the tradeoffs against other orchestration systems:
| Command surface | 15-33+ command sets | 19 commands | Faster onboarding, but less granular command specialization |
| State storage | JSON/DB/hybrid state | Markdown-only .planning/ | Human-readable and git-native, but less strict schema enforcement |
| Setup model | CLI bootstrap + config | npx installer | Simpler install path, but runtime capabilities can vary more |
| Always-load context | Monolithic shared instructions | Lean workflow-common-core + optional extensions | Lower prompt cost on hot paths, but activation rules must stay accurate |
| Agent model | Generic role prompts | 49 full personalities + retrieval-led loading | Higher specificity without preloading the full roster, but prompt discipline still matters for large agents |
| User interaction gates | Free-form confirmations | Closed-set AskUserQuestion flows | More deterministic on literal models, but less conversational looseness |
| Runtime coverage | Single-runtime focus | 11 runtime adapters | Broader portability, but feature parity differs by runtime tier |
| Memory strategy | Hook-based/global memory | Project-local explicit memory | Better project isolation, but requires explicit integration points |
Current repository metrics: 19 commands, 33 skills, 49 agent personalities, 11 runtime adapters, and 4 control mode presets.
The 49 Agents
Agents are organized across 9 divisions, each with deep specialist personalities:
| Engineering | 9 | Full-stack, backend, frontend, AI, infrastructure/DevOps, mobile, prototyping, Laravel, security |
| Design | 6 | UI/UX, branding, visual storytelling, research |
| Marketing | 4 | Content & social strategy, platform execution, growth, ASO |
| Testing | 7 | QA verification, performance, API testing, tool evaluation, code polish |
| Product | 4 | Sprint planning, feedback synthesis, trends, technical writing |
| Project Management | 5 | Coordination, portfolio, operations, experiments |
| Support | 4 | Finance, legal, executive summaries, support |
| Spatial Computing | 6 | VisionOS, XR, Metal, terminal integration |
| Specialized | 4 | Orchestration, data analytics, LSP indexing, exploration (Polymath) |
Browse the full roster in the agents/ directory.
Architecture
legion/ <- Project root
├── package.json <- npm package manifest (name, version, engines)
├── bin/
│ └── install.js <- Cross-runtime installer (npx entry point)
├── CLAUDE.md <- Project instructions (injected into Claude Code context)
├── commands/ <- 19 /legion: command entry points
│ ├── start.md
│ ├── plan.md
│ ├── build.md
│ ├── review.md
│ ├── polish.md
│ ├── status.md
│ ├── quick.md
│ ├── advise.md
│ ├── portfolio.md
│ ├── milestone.md
│ ├── agent.md
│ ├── map.md
│ ├── explore.md
│ ├── board.md
│ ├── retro.md
│ ├── ship.md
│ ├── learn.md
│ ├── update.md
│ └── validate.md
├── skills/ <- 33 reusable workflow skills
│ ├── workflow-common-core/SKILL.md <- Lean always-load core conventions
│ ├── workflow-common/SKILL.md <- Compatibility shim for legacy references
│ ├── agent-registry/
│ │ ├── SKILL.md <- Recommendation algorithm + team patterns
│ │ └── CATALOG.md <- 49 agent catalog + task-type index
│ ├── questioning-flow/SKILL.md <- 3-stage adaptive conversation
│ ├── phase-decomposer/SKILL.md <- Phase decomposition with domain detection
│ ├── wave-executor/SKILL.md <- Parallel execution with personality injection
│ ├── execution-tracker/SKILL.md <- Progress tracking + atomic commits
│ ├── review-loop/SKILL.md <- Dev-QA loop with structured feedback
│ ├── review-panel/SKILL.md <- Dynamic multi-reviewer composition with rubrics
│ ├── plan-critique/SKILL.md <- Pre-mortem analysis + assumption hunting
│ ├── hooks-integration/SKILL.md <- Claude Code hooks for lifecycle automation
│ └── + 22 more (portfolio, milestone, memory, agents, GitHub, codebase mapping, marketing, design, spec pipeline, ship pipeline, security review, code polish, Legion bridge integration, and workflow-common extensions)
├── agents/ <- 49 personality .md files (flat, with division in frontmatter)
│ ├── engineering-senior-developer.md
│ ├── design-ui-designer.md
│ ├── marketing-content-social-strategist.md
│ ├── testing-qa-verification-specialist.md
│ └── ... (45 more)
├── adapters/ <- Per-CLI adapter files (claude-code.md, codex-cli.md, etc.)
├── docs/
│ ├── control-modes.md <- Control mode usage guide (v6.0)
│ ├── schemas/ <- JSON Schema validation (plan frontmatter, summaries, outcomes, review findings)
│ ├── security/ <- Install integrity verification docs
│ └── settings.schema.json <- Settings JSON schema
└── .planning/ <- Project state (generated per-project, not part of package)
├── PROJECT.md
├── ROADMAP.md
├── STATE.md
├── config/ <- Authority matrix, control modes, escalation protocol, agent communication
├── phases/ <- Active phase plans and summaries
├── memory/ <- OUTCOMES.md (optional cross-session memory)
└── archive/ <- Archived phases from completed milestones
Design Principles
- Personality-first: Agent .md files are the source of truth for behavior
- Runtime-agnostic: Works with 10 AI CLI runtimes plus Kilo Code plugin support — skills, commands, and agents adapt via per-runtime adapters (support tiers listed below)
- Human-readable state: All planning files are markdown, readable without tools
- Full personality injection: Agents are spawned with their complete .md as instructions
- Standardized format: All 49 agents use Format A — emoji section headings, "Your" pronouns, current range 156-472 lines (minimum 80)
- Budget-aware orchestration: Heavier reasoning is reserved for planning and governance when the adapter supports it; execution stays on faster defaults, optional skills stay unloaded until needed, and prompt ceilings prevent oversized spawns
- Configurable per-plan task cap: Keeps individual plans focused while allowing any number of plans per phase
- Hybrid selection: Workflow recommends agents, user confirms or overrides
- Plan contracts:
files_forbidden, expected_artifacts, and mandatory verification_commands enforce discipline at planning time
- Wave execution: Plans grouped by dependency; parallel within waves, sequential between. File overlap detection and
sequential_files prevent conflicts
- Control modes: Four presets (autonomous, guarded, advisory, surgical) adjust authority enforcement per-project
- Deterministic gates: User-facing decisions use closed-set AskUserQuestion flows and explicit trigger rules, reducing ambiguity on literal models such as Claude Opus 4.7
- Observability: Decision logging in SUMMARY.md and cycle-over-cycle diffs in REVIEW.md provide agent decision audit trails
- Retrieval-led reasoning: A compressed Dynamic Knowledge Index in AGENTS.md maps every agent and skill file by division/category. Combined with a "prefer retrieval over pre-training" directive, this eliminates LLM laziness during agent spawning while keeping the coordinator's hot path lighter — agents read the exact files they need instead of hallucinating personas. Based on Vercel's Context Engineering research.
- Graceful degradation: Optional features (GitHub, memory, codebase mapping, marketing, design, panels, critique) activate when available, skip silently when not
- Read-only advisory: Consultation agents explore but never modify — tool-level enforcement via Explore subagent type
- Domain-weighted review: Each reviewer evaluates against non-overlapping criteria scoped to their expertise, not generic checklists
Optional Features
These activate automatically when their prerequisites are met:
| GitHub Integration | gh CLI authenticated + git remote exists | Links phases to issues, creates PRs, syncs milestones |
| Cross-Session Memory | .planning/memory/OUTCOMES.md exists | Boosts agent recommendations based on past performance |
| Codebase Map | /legion:map or existing codebase detected during /legion:start | Maps architecture, functionality, risks, semantic index, and directory mappings before planning |
| Marketing Workflows | MKT-* phase requirements OR workflow_type: marketing in CONTEXT.md | Campaign planning, content calendars, channel coordination |
| Design Workflows | DSN-* phase requirements OR workflow_type: design in CONTEXT.md | Design systems, UX research, three-lens review (brand + accessibility + usability) |
| Plan Critique | User selects critique during /legion:plan | Pre-mortem analysis, assumption hunting, PASS/CAUTION/REWORK verdicts |
| Review Panels | User selects panel mode in /legion:review | 2-4 domain-weighted reviewers with non-overlapping rubrics |
| Control Modes | control_mode set in settings.json | Adjusts authority enforcement: autonomous, guarded, advisory, surgical |
| Intent Routing | Ambiguous input to any command | Natural language parsing routes to the right command + flags |
| Design Discovery | /legion:explore | Research-first brainstorming that saves a design doc before optional /legion:start |
| Board of Directors | /legion:board meet <topic> or /legion:board review | Governance deliberation with dynamic agent panels, voting, and audit trail |
| Cross-CLI Dispatch | dispatch.enabled in settings.json + external CLI installed | Routes work to Gemini/Codex/Copilot via capability matching |
| Multi-Pass Evaluators | review.evaluator_depth: "multi-pass" in settings | Deep evaluation with 4 specialized evaluator types (6-7 passes each) |
| Git Worktrees | execution.use_worktrees: true in settings.json | Filesystem isolation during parallel waves with automatic merge and conflict detection |
| Hooks Integration | Claude Code hooks configured per hooks-integration skill | Pre-build validation, post-build notification, pre-ship security gate |
| Extended Thinking | models.planning_reasoning: true in settings.json | Deeper requirement analysis and wave ordering rationale in planning |
| Memory Pruning | memory.auto_prune: true in settings.json | Automatic archiving of old OUTCOMES.md entries to keep active memory lean |
| Code Polish | review.polish: true in settings.json (default) | 4-pass post-review cleanup: comments, simplification, readability, consistency. Non-blocking with safety rails |
| State Validation | /legion:validate command | Schema conformance, cross-reference checking, integrity verification for .planning/ files |
- Commands: 19
- Skills: 33
- Agents: 49
- Agent personality line range (current): 156-472
Requirements
- Node.js 18+ (install-time only; the installer lazy-loads
yaml for safe Kilo Code mode merges)
- One of the 11 supported AI CLI runtimes or the Kilo Code plugin:
Claude Code, OpenAI Codex CLI, Cursor, GitHub Copilot CLI, Google Gemini CLI, Antigravity CLI, Kiro CLI, Windsurf, OpenCode, Kilo CLI, Aider, or Kilo Code Plugin
Contributing
See CONTRIBUTING.md for development setup and agent design guidelines.
License
MIT