@a_kawashiro/jendeley
Advanced tools
@a_kawashiro/jendeley - npm Package Compare versions
Comparing version 0.0.11 to 0.0.12
@@ -15,3 +15,3 @@ "use strict"; | ||
| Object.defineProperty(exports, "__esModule", { value: true }); | ||
| exports.get_title_from_url = exports.get_pdf = exports.add_pdf_from_url = exports.update_entry = exports.add_web_from_url = exports.delete_entry = exports.get_db = void 0; | ||
| exports.getTitleFromUrl = exports.getPdf = exports.addPdfFromUrl = exports.updateEntry = exports.addWebFromUrl = exports.deleteEntry = exports.getDB = void 0; | ||
| const url_1 = __importDefault(require("url")); | ||
@@ -187,3 +187,3 @@ const base_64_1 = __importDefault(require("base-64")); | ||
| } | ||
| function update_entry(request, response, db_path) { | ||
| function updateEntry(request, response, db_path) { | ||
| logger_1.logger.info("Get a update_entry request url = " + request.url); | ||
@@ -216,4 +216,4 @@ const entry_o = request.body; | ||
| } | ||
| exports.update_entry = update_entry; | ||
| function get_pdf(request, response, db_path) { | ||
| exports.updateEntry = updateEntry; | ||
| function getPdf(request, response, db_path) { | ||
| logger_1.logger.info("Get a get_pdf request", request.url); | ||
@@ -231,4 +231,4 @@ const params = url_1.default.parse(request.url, true).query; | ||
| } | ||
| exports.get_pdf = get_pdf; | ||
| function get_db(request, response, db_path) { | ||
| exports.getPdf = getPdf; | ||
| function getDB(request, response, db_path) { | ||
| logger_1.logger.info("Get a get_db request" + request.url); | ||
@@ -251,4 +251,4 @@ const json = JSON.parse(fs_1.default.readFileSync(db_path).toString()); | ||
| } | ||
| exports.get_db = get_db; | ||
| function get_title_from_url(url) { | ||
| exports.getDB = getDB; | ||
| function getTitleFromUrl(url) { | ||
| return __awaiter(this, void 0, void 0, function* () { | ||
@@ -262,4 +262,4 @@ let { got } = yield import("got"); | ||
| } | ||
| exports.get_title_from_url = get_title_from_url; | ||
| function add_web_from_url(httpRequest, response, db_path) { | ||
| exports.getTitleFromUrl = getTitleFromUrl; | ||
| function addWebFromUrl(httpRequest, response, db_path) { | ||
| return __awaiter(this, void 0, void 0, function* () { | ||
@@ -272,3 +272,3 @@ const req = httpRequest.body; | ||
| let json = JSON.parse(fs_1.default.readFileSync(db_path).toString()); | ||
| const title = req.title == "" ? yield get_title_from_url(req.url) : req.title; | ||
| const title = req.title == "" ? yield getTitleFromUrl(req.url) : req.title; | ||
| const date = new Date(); | ||
@@ -289,4 +289,4 @@ const date_tag = date.toISOString().split("T")[0]; | ||
| } | ||
| exports.add_web_from_url = add_web_from_url; | ||
| function add_pdf_from_url(httpRequest, response, db_path) { | ||
| exports.addWebFromUrl = addWebFromUrl; | ||
| function addPdfFromUrl(httpRequest, response, db_path) { | ||
| return __awaiter(this, void 0, void 0, function* () { | ||
@@ -332,4 +332,4 @@ // TODO: Handle RequestGetPdfFromUrl.isbn/doi/comments/tags | ||
| } | ||
| exports.add_pdf_from_url = add_pdf_from_url; | ||
| function delete_entry(request, response, db_path) { | ||
| exports.addPdfFromUrl = addPdfFromUrl; | ||
| function deleteEntry(request, response, db_path) { | ||
| logger_1.logger.info("Get a delete_entry request url = " + request.url); | ||
@@ -374,3 +374,3 @@ const entry_o = request.body; | ||
| } | ||
| exports.delete_entry = delete_entry; | ||
| exports.deleteEntry = deleteEntry; | ||
| //# sourceMappingURL=api.js.map |
@@ -14,9 +14,9 @@ "use strict"; | ||
| test("title from nodejs", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const title = yield (0, api_1.get_title_from_url)("https://nodejs.org/en/"); | ||
| const title = yield (0, api_1.getTitleFromUrl)("https://nodejs.org/en/"); | ||
| expect(title).toBe("Node.js"); | ||
| })); | ||
| test("title from python", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const title = yield (0, api_1.get_title_from_url)("https://www.python.org/"); | ||
| const title = yield (0, api_1.getTitleFromUrl)("https://www.python.org/"); | ||
| expect(title).toBe("Welcome to Python.org"); | ||
| })); | ||
| //# sourceMappingURL=api.test.js.map |
@@ -113,6 +113,6 @@ "use strict"; | ||
| function getDocIDManuallyWritten(pdf) { | ||
| const regexpDOI1 = new RegExp("(doi_10_[0-9]{4}_[0-9]{4,}([_-][0-9()-]{6,})?)", "g"); | ||
| const regexpDOI1 = new RegExp("\\[\\s*jendeley\\s+doi\\s+(10_[0-9]{4}_[0-9]{4,}([_-][0-9()-]{6,})?)\\s*\\]", "g"); | ||
| const foundDOI1 = [...pdf.matchAll(regexpDOI1)]; | ||
| for (const f of foundDOI1) { | ||
| let d = f[0].substring(4); | ||
| let d = f[1]; | ||
| d = | ||
@@ -127,6 +127,6 @@ d.substring(0, 2) + | ||
| } | ||
| const regexpDOI2 = new RegExp("(doi_10_[0-9]{4}_[A-Z]{1,3}[0-9]+[0-9X])", "g"); | ||
| const regexpDOI2 = new RegExp("\\[\\s*jendeley\\s+doi\\s+(10_[0-9]{4}_[A-Z]{1,3}[0-9]+[0-9X])\\s*\\]", "g"); | ||
| const foundDOI2 = [...pdf.matchAll(regexpDOI2)]; | ||
| for (const f of foundDOI2) { | ||
| let d = f[0].substring(4); | ||
| let d = f[1]; | ||
| d = | ||
@@ -141,6 +141,6 @@ d.substring(0, 2) + | ||
| } | ||
| const regexpDOI3 = new RegExp("(doi_10_[0-9]{4}_[a-zA-z]+_[0-9]+_[0-9]+)", "g"); | ||
| const regexpDOI3 = new RegExp("\\[\\s*jendeley\\s+doi\\s+(10_[0-9]{4}_[a-zA-z]+_[0-9]+_[0-9]+)\\s*\\]", "g"); | ||
| const foundDOI3 = [...pdf.matchAll(regexpDOI3)]; | ||
| for (const f of foundDOI3) { | ||
| let d = f[0].substring(4); | ||
| let d = f[1]; | ||
| d = | ||
@@ -155,6 +155,6 @@ d.substring(0, 2) + | ||
| } | ||
| const regexpDOI4 = new RegExp("(doi_10_[0-9]{4}_[0-9X-]+_[0-9]{1,})", "g"); | ||
| const regexpDOI4 = new RegExp("\\[\\s*jendeley\\s+doi\\s+(10_[0-9]{4}_[0-9X-]+_[0-9]{1,})\\s*\\]", "g"); | ||
| const foundDOI4 = [...pdf.matchAll(regexpDOI4)]; | ||
| for (const f of foundDOI4) { | ||
| let d = f[0].substring(4); | ||
| let d = f[1]; | ||
| d = | ||
@@ -168,6 +168,6 @@ d.substring(0, 2) + | ||
| } | ||
| const regexpDOI6 = new RegExp("(doi_10_[0-9]{4}_[a-zA-z]+-[0-9]+-[0-9]+)", "g"); | ||
| const regexpDOI6 = new RegExp("\\[\\s*jendeley\\s+doi\\s+(10_[0-9]{4}_[a-zA-z]+-[0-9]+-[0-9]+)\\s*\\]", "g"); | ||
| const foundDOI6 = [...pdf.matchAll(regexpDOI6)]; | ||
| for (const f of foundDOI6) { | ||
| let d = f[0].substring(4); | ||
| let d = f[1]; | ||
| d = | ||
@@ -182,6 +182,6 @@ d.substring(0, 2) + | ||
| } | ||
| const regexpDOI7 = new RegExp("(doi_10_[0-9]{4}_978-[0-9-]+)", "g"); | ||
| const regexpDOI7 = new RegExp("\\[\\s*jendeley\\s+doi\\s+(10_[0-9]{4}_978-[0-9-]+)\\s*\\]", "g"); | ||
| const foundDOI7 = [...pdf.matchAll(regexpDOI7)]; | ||
| for (const f of foundDOI7) { | ||
| let d = f[0].substring(4); | ||
| let d = f[1]; | ||
| d = | ||
@@ -196,6 +196,6 @@ d.substring(0, 2) + | ||
| } | ||
| const regexpISBN = new RegExp("(isbn_[0-9]{10,})", "g"); | ||
| const regexpISBN = new RegExp(".*\\[\\s*jendeley\\s+isbn\\s+([0-9]{10,})\\s*\\]", "g"); | ||
| const foundISBN = [...pdf.matchAll(regexpISBN)]; | ||
| for (const f of foundISBN) { | ||
| let d = f[0].substring(5); | ||
| let d = f[1]; | ||
| return { doi: null, isbn: d, arxiv: null, path: null, url: null }; | ||
@@ -202,0 +202,0 @@ } |
@@ -15,3 +15,3 @@ "use strict"; | ||
| test.skip("DOI from title", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf = "/papers/[Thomas van Noort, Peter Achten, Rinus Plasmeijer]Ad-hoc Polymorphism and Dynamic Typing in a Statically Typed Functional Language.pdf"; | ||
| const pdf = "/papers/[Thomas van Noort, Peter Achten, Rinus Plasmeijer] Ad-hoc Polymorphism and Dynamic Typing in a Statically Typed Functional Language.pdf"; | ||
| const docID = yield (0, docid_1.getDocIDFromTitle)(pdf, "hoge"); | ||
@@ -49,5 +49,5 @@ expect(docID === null || docID === void 0 ? void 0 : docID.doi).toBe("10.1145/1863495.1863505"); | ||
| test("no_id from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf4 = "hoge_no_id.pdf"; | ||
| const docID4 = yield (0, docid_1.getDocID)(pdf4, "/hoge/", false, null); | ||
| expect(docID4).toStrictEqual({ | ||
| const pdf = "hoge_no_id.pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
@@ -60,2 +60,13 @@ doi: null, | ||
| })); | ||
| test("jendeley no id from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf = "hoge [jendeley no id].pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
| doi: null, | ||
| isbn: null, | ||
| path: "hoge [jendeley no id].pdf", | ||
| url: null, | ||
| }); | ||
| })); | ||
| test("arXiv from URL", () => __awaiter(void 0, void 0, void 0, function* () { | ||
@@ -74,5 +85,5 @@ const pdf = "hoge.pdf"; | ||
| test("ISBN from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf5 = "hoge_isbn_9781467330763.pdf"; | ||
| const docID5 = yield (0, docid_1.getDocID)(pdf5, "/hoge/", false, null); | ||
| expect(docID5).toStrictEqual({ | ||
| const pdf = "hoge [jendeley isbn 9781467330763].pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
@@ -85,17 +96,19 @@ doi: null, | ||
| })); | ||
| test("DOI from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf6 = "hoge_doi_10_1145_3290364.pdf"; | ||
| const docID6 = yield (0, docid_1.getDocID)(pdf6, "/hoge/", false, null); | ||
| expect(docID6).toStrictEqual({ | ||
| test("ISBN from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf = "hoge [jendeley isbn 9781467330763].pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
| doi: "10.1145/3290364", | ||
| isbn: null, | ||
| doi: null, | ||
| isbn: "9781467330763", | ||
| path: null, | ||
| url: null, | ||
| }); | ||
| const pdf7 = "A Dependently Typed Assembly Language_doi_10_1145_507635_507657.pdf"; | ||
| const docID7 = yield (0, docid_1.getDocID)(pdf7, "/hoge/", false, null); | ||
| expect(docID7).toStrictEqual({ | ||
| })); | ||
| test("DOI from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf = "hoge [jendeley doi 10_1145_3290364].pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
| doi: "10.1145/507635.507657", | ||
| doi: "10.1145/3290364", | ||
| isbn: null, | ||
@@ -107,3 +120,3 @@ path: null, | ||
| test("Complicated doi from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf2 = "DependentType/[EDWIN BRADY] Idris, a General Purpose Dependently Typed Programming Language- Design and Implementation_doi_10_1017_S095679681300018X.pdf"; | ||
| const pdf2 = "DependentType/[EDWIN BRADY] Idris, a General Purpose Dependently Typed Programming Language- Design and Implementation [jendeley doi 10_1017_S095679681300018X].pdf"; | ||
| const docID2 = yield (0, docid_1.getDocID)(pdf2, "/hoge/", false, null); | ||
@@ -117,3 +130,3 @@ expect(docID2).toStrictEqual({ | ||
| }); | ||
| const pdf4 = "MemoryModel/[Scott Owens, Susmit Sarkar, Peter Sewell] A Better x86 Memory Model x86-TSO_doi_10_1007_978-3-642-03359-9_27.pdf"; | ||
| const pdf4 = "MemoryModel/[Scott Owens, Susmit Sarkar, Peter Sewell] A Better x86 Memory Model x86-TSO [jendeley doi 10_1007_978-3-642-03359-9_27].pdf"; | ||
| const docID4 = yield (0, docid_1.getDocID)(pdf4, "/hoge/", false, null); | ||
@@ -127,3 +140,3 @@ expect(docID4).toStrictEqual({ | ||
| }); | ||
| const pdf5 = "Riffle An Efficient Communication System with Strong Anonymity_doi_10_1515_popets-2016-0008.pdf"; | ||
| const pdf5 = "Riffle An Efficient Communication System with Strong Anonymity [jendeley doi 10_1515_popets-2016-0008].pdf"; | ||
| const docID5 = yield (0, docid_1.getDocID)(pdf5, "/hoge/", false, null); | ||
@@ -137,3 +150,3 @@ expect(docID5).toStrictEqual({ | ||
| }); | ||
| const pdf7 = "[Peter Dybjer] Inductive families_doi_10_1007_BF01211308.pdf"; | ||
| const pdf7 = "[Peter Dybjer] Inductive families [jendeley doi 10_1007_BF01211308].pdf"; | ||
| const docID7 = yield (0, docid_1.getDocID)(pdf7, "/hoge/", false, null); | ||
@@ -147,3 +160,3 @@ expect(docID7).toStrictEqual({ | ||
| }); | ||
| const pdf9 = "[Henk Barendregt] Lambda Calculus with Types_doi_10_1017_CBO9781139032636.pdf"; | ||
| const pdf9 = "[Henk Barendregt] Lambda Calculus with Types [jendeley doi 10_1017_CBO9781139032636].pdf"; | ||
| const docID9 = yield (0, docid_1.getDocID)(pdf9, "/hoge/", false, null); | ||
@@ -159,3 +172,3 @@ expect(docID9).toStrictEqual({ | ||
| test("Complicated journal-like doi from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf1 = "Call-by-name, call-by-value and the λ-calculus_doi_10_1016_0304-3975(75)90017-1.pdf"; | ||
| const pdf1 = "Call-by-name, call-by-value and the λ-calculus [jendeley doi 10_1016_0304-3975(75)90017-1].pdf"; | ||
| const docID1 = yield (0, docid_1.getDocID)(pdf1, "/hoge/", false, null); | ||
@@ -169,3 +182,3 @@ expect(docID1).toStrictEqual({ | ||
| }); | ||
| const pdf3 = "Emerging-MPEG-Standards-for-Point-Cloud-Compression_doi_10_1109_JETCAS_2018_2885981.pdf"; | ||
| const pdf3 = "Emerging-MPEG-Standards-for-Point-Cloud-Compression [jendeley doi 10_1109_JETCAS_2018_2885981].pdf"; | ||
| const docID3 = yield (0, docid_1.getDocID)(pdf3, "/hoge/", false, null); | ||
@@ -179,3 +192,3 @@ expect(docID3).toStrictEqual({ | ||
| }); | ||
| const pdf10 = "[John C. Reynolds] Separation Logic A Logic for Shared Mutable Data Structures_doi_10_1109_LICS_2002_1029817.pdf"; | ||
| const pdf10 = "[John C. Reynolds] Separation Logic A Logic for Shared Mutable Data Structures [jendeley doi 10_1109_LICS_2002_1029817].pdf"; | ||
| const docID10 = yield (0, docid_1.getDocID)(pdf10, "/hoge/", false, null); | ||
@@ -190,6 +203,35 @@ expect(docID10).toStrictEqual({ | ||
| })); | ||
| test("Complicated journal-like doi from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf1 = "Call-by-name, call-by-value and the λ-calculus [jendeley doi 10_1016_0304-3975(75)90017-1].pdf"; | ||
| const docID1 = yield (0, docid_1.getDocID)(pdf1, "/hoge/", false, null); | ||
| expect(docID1).toStrictEqual({ | ||
| arxiv: null, | ||
| doi: "10.1016/0304-3975(75)90017-1", | ||
| isbn: null, | ||
| path: null, | ||
| url: null, | ||
| }); | ||
| const pdf3 = "Emerging-MPEG-Standards-for-Point-Cloud-Compression [jendeley doi 10_1109_JETCAS_2018_2885981].pdf"; | ||
| const docID3 = yield (0, docid_1.getDocID)(pdf3, "/hoge/", false, null); | ||
| expect(docID3).toStrictEqual({ | ||
| arxiv: null, | ||
| doi: "10.1109/JETCAS.2018.2885981", | ||
| isbn: null, | ||
| path: null, | ||
| url: null, | ||
| }); | ||
| const pdf10 = "[John C. Reynolds] Separation Logic A Logic for Shared Mutable Data Structures [jendeley doi 10_1109_LICS_2002_1029817].pdf"; | ||
| const docID10 = yield (0, docid_1.getDocID)(pdf10, "/hoge/", false, null); | ||
| expect(docID10).toStrictEqual({ | ||
| arxiv: null, | ||
| doi: "10.1109/LICS.2002.1029817", | ||
| isbn: null, | ||
| path: null, | ||
| url: null, | ||
| }); | ||
| })); | ||
| test("Complicated book-like doi from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf6 = "MultistageProgramming/[Oleg Kiselyov] The Design and Implementation of BER MetaOCaml_doi_10_1007_978-3-319-07151-0_6.pdf"; | ||
| const docID6 = yield (0, docid_1.getDocID)(pdf6, "/hoge/", false, null); | ||
| expect(docID6).toStrictEqual({ | ||
| const pdf = "MultistageProgramming/[Oleg Kiselyov] The Design and Implementation of BER MetaOCaml [jendeley doi 10_1007_978-3-319-07151-0_6].pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
@@ -201,5 +243,7 @@ doi: "10.1007/978-3-319-07151-0_6", | ||
| }); | ||
| const pdf11 = "[Paul Blain Levy] Call By Push Value_doi_10_1007_978-94-007-0954-6.pdf"; | ||
| const docID11 = yield (0, docid_1.getDocID)(pdf11, "/hoge/", false, null); | ||
| expect(docID11).toStrictEqual({ | ||
| })); | ||
| test("Complicated book-like doi from path", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf = "[Paul Blain Levy] Call By Push Value [jendeley doi 10_1007_978-94-007-0954-6].pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
@@ -213,5 +257,5 @@ doi: "10.1007/978-94-007-0954-6", | ||
| test.skip("Lonely planet China", () => __awaiter(void 0, void 0, void 0, function* () { | ||
| const pdf8 = "lonelyplanet-china-15-full-book.pdf"; | ||
| const docID8 = yield (0, docid_1.getDocID)(pdf8, "/hoge/", false, null); | ||
| expect(docID8).toStrictEqual({ | ||
| const pdf = "lonelyplanet-china-15-full-book.pdf"; | ||
| const docID = yield (0, docid_1.getDocID)(pdf, "/hoge/", false, null); | ||
| expect(docID).toStrictEqual({ | ||
| arxiv: null, | ||
@@ -224,2 +268,59 @@ doi: null, | ||
| })); | ||
| // test("ISBN from path", async () => { | ||
| // const pdf = "hoge_isbn_9781467330763.pdf"; | ||
| // const docID = await getDocID(pdf, "/hoge/", false, null); | ||
| // expect(docID).toStrictEqual({ | ||
| // arxiv: null, | ||
| // doi: null, | ||
| // isbn: "9781467330763", | ||
| // path: null, | ||
| // url: null, | ||
| // }); | ||
| // }); | ||
| // | ||
| // test("DOI from path", async () => { | ||
| // const pdf6 = "hoge_doi_10_1145_3290364.pdf"; | ||
| // const docID6 = await getDocID(pdf6, "/hoge/", false, null); | ||
| // expect(docID6).toStrictEqual({ | ||
| // arxiv: null, | ||
| // doi: "10.1145/3290364", | ||
| // isbn: null, | ||
| // path: null, | ||
| // url: null, | ||
| // }); | ||
| // | ||
| // const pdf7 = | ||
| // "A Dependently Typed Assembly Language_doi_10_1145_507635_507657.pdf"; | ||
| // const docID7 = await getDocID(pdf7, "/hoge/", false, null); | ||
| // expect(docID7).toStrictEqual({ | ||
| // arxiv: null, | ||
| // doi: "10.1145/507635.507657", | ||
| // isbn: null, | ||
| // path: null, | ||
| // url: null, | ||
| // }); | ||
| // }); | ||
| // test("Complicated book-like doi from path", async () => { | ||
| // const pdf6 = | ||
| // "MultistageProgramming/[Oleg Kiselyov] The Design and Implementation of BER MetaOCaml_doi_10_1007_978-3-319-07151-0_6.pdf"; | ||
| // const docID6 = await getDocID(pdf6, "/hoge/", false, null); | ||
| // expect(docID6).toStrictEqual({ | ||
| // arxiv: null, | ||
| // doi: "10.1007/978-3-319-07151-0_6", | ||
| // isbn: null, | ||
| // path: null, | ||
| // url: null, | ||
| // }); | ||
| // | ||
| // const pdf11 = | ||
| // "[Paul Blain Levy] Call By Push Value_doi_10_1007_978-94-007-0954-6.pdf"; | ||
| // const docID11 = await getDocID(pdf11, "/hoge/", false, null); | ||
| // expect(docID11).toStrictEqual({ | ||
| // arxiv: null, | ||
| // doi: "10.1007/978-94-007-0954-6", | ||
| // isbn: null, | ||
| // path: null, | ||
| // url: null, | ||
| // }); | ||
| // }); | ||
| //# sourceMappingURL=gen.test.js.map |
@@ -19,3 +19,3 @@ #!/usr/bin/env node | ||
| const program = new commander_1.Command(); | ||
| program.name("jendeley"); | ||
| program.name("jendeley").version("0.0.11", "-v, --version"); | ||
| program | ||
@@ -41,5 +41,6 @@ .command("scan") | ||
| .option("--no_browser", "Don't launch browser") | ||
| .option("--use_dev_port", "Only for developpers") | ||
| .option("--port <port>", "Use if the default port 5000 is used.", "5000") | ||
| .action((cmd, options) => { | ||
| (0, server_1.startServer)(options._optionValues.db, options._optionValues.no_browser, options._optionValues.use_dev_port); | ||
| const port_n = parseInt(options._optionValues.port, 10); | ||
| (0, server_1.startServer)(options._optionValues.db, options._optionValues.no_browser, port_n); | ||
| }); | ||
@@ -46,0 +47,0 @@ program |
@@ -24,6 +24,5 @@ "use strict"; | ||
| const api_1 = require("./api"); | ||
| function startServer(db_path, no_browser, use_dev_port) { | ||
| function startServer(db_path, no_browser, port) { | ||
| if (fs_1.default.existsSync(db_path)) { | ||
| const app = (0, express_1.default)(); | ||
| const port = use_dev_port ? 5001 : 5000; | ||
| app.use((0, cors_1.default)()); | ||
@@ -36,19 +35,19 @@ const built_frontend_dir = path_1.default.join(__dirname, "..", "built-frontend"); | ||
| app.get("/api/get_db", (request, response) => { | ||
| (0, api_1.get_db)(request, response, db_path); | ||
| (0, api_1.getDB)(request, response, db_path); | ||
| }); | ||
| app.get("/api/get_pdf", (request, response) => { | ||
| (0, api_1.get_pdf)(request, response, db_path); | ||
| (0, api_1.getPdf)(request, response, db_path); | ||
| }); | ||
| let jsonParser = body_parser_1.default.json(); | ||
| app.put("/api/add_pdf_from_url", jsonParser, (httpRequest, response) => __awaiter(this, void 0, void 0, function* () { | ||
| (0, api_1.add_pdf_from_url)(httpRequest, response, db_path); | ||
| (0, api_1.addPdfFromUrl)(httpRequest, response, db_path); | ||
| })); | ||
| app.put("/api/add_web_from_url", jsonParser, (httpRequest, response) => __awaiter(this, void 0, void 0, function* () { | ||
| (0, api_1.add_web_from_url)(httpRequest, response, db_path); | ||
| (0, api_1.addWebFromUrl)(httpRequest, response, db_path); | ||
| })); | ||
| app.put("/api/update_entry", jsonParser, (request, response) => { | ||
| (0, api_1.update_entry)(request, response, db_path); | ||
| (0, api_1.updateEntry)(request, response, db_path); | ||
| }); | ||
| app.delete("/api/delete_entry", jsonParser, (request, response) => { | ||
| (0, api_1.delete_entry)(request, response, db_path); | ||
| (0, api_1.deleteEntry)(request, response, db_path); | ||
| }); | ||
@@ -55,0 +54,0 @@ app.listen(port, () => { |
@@ -6,3 +6,3 @@ { | ||
| }, | ||
| "version": "0.0.11", | ||
| "version": "0.0.12", | ||
| "description": "", | ||
@@ -18,3 +18,3 @@ "main": "index.js", | ||
| "profile_scan_test_pdfs": "npm run build && node --require source-map-support/register --prof dist/index.js scan --papers_dir test_pdfs", | ||
| "scan_test_pdfs_and_launch": "npm run build && node --require source-map-support/register dist/index.js scan --papers_dir test_pdfs && node --require source-map-support/register dist/index.js launch --db test_pdfs/jendeley_db.json --use_dev_port --no_browser", | ||
| "scan_test_pdfs_and_launch": "npm run build && node --require source-map-support/register dist/index.js scan --papers_dir test_pdfs && node --require source-map-support/register dist/index.js launch --db test_pdfs/jendeley_db.json --port 5001 --no_browser", | ||
| "fix:prettier": "prettier --write src", | ||
@@ -21,0 +21,0 @@ "check:prettier": "prettier --check src" |
| # jendeley | ||
| `jendeley` is a JSON-based paper organizing software. | ||
| `jendeley` is a JSON-based PDF paper organizing software. | ||
| - `jendeley` is JSON-based. You can see and edit your database easily. | ||
@@ -7,3 +7,3 @@ - `jendeley` is working locally. Your important database is owned only by you. Not cloud. | ||
| ## Install | ||
| ## How to install | ||
| ``` | ||
@@ -14,2 +14,3 @@ npm install @a_kawashiro/jendeley -g | ||
| ## How to scan your PDFs | ||
| This command emits the database to `<YOUR PDFs DIR>/jendeley_db.json`. When `jendeley` failed to scan some PDFs, it emit a shellscript `edit_and_run.sh`. Please read the next subsection and rename files using it. | ||
| ``` | ||
@@ -19,3 +20,8 @@ jendeley scan --papers_dir <YOUR PDFs DIR> | ||
| #### When failed to scan your PDFs | ||
| `jendeley` is heavily dependent on [Digital Object Identifier System](https://www.doi.org/)(DOI) or [ISBN](https://en.wikipedia.org/wiki/ISBN) to find title, authors and published year of PDFs. So `jendeley` try to find DOI of given PDFs in many ways. But sometimes all of them fails to find DOI. In that case, you can specify DOI of PDF manually using filename. | ||
| - To specify DOI, change the filename to include `[jendeley doi <DOI replaced all delimiters with underscore>]`. For example, `cyclone [jendeley doi 10_1145_512529_512563].pdf`. | ||
| - To specify ISBN, change the filename to include `[jendeley isbn <ISBN>]`. For example, `hoge [jendeley isbn 9781467330763].pdf`. | ||
| ## Launch jendeley UI | ||
@@ -26,7 +32,7 @@ ``` | ||
| Then you can see a screen like this! | ||
| 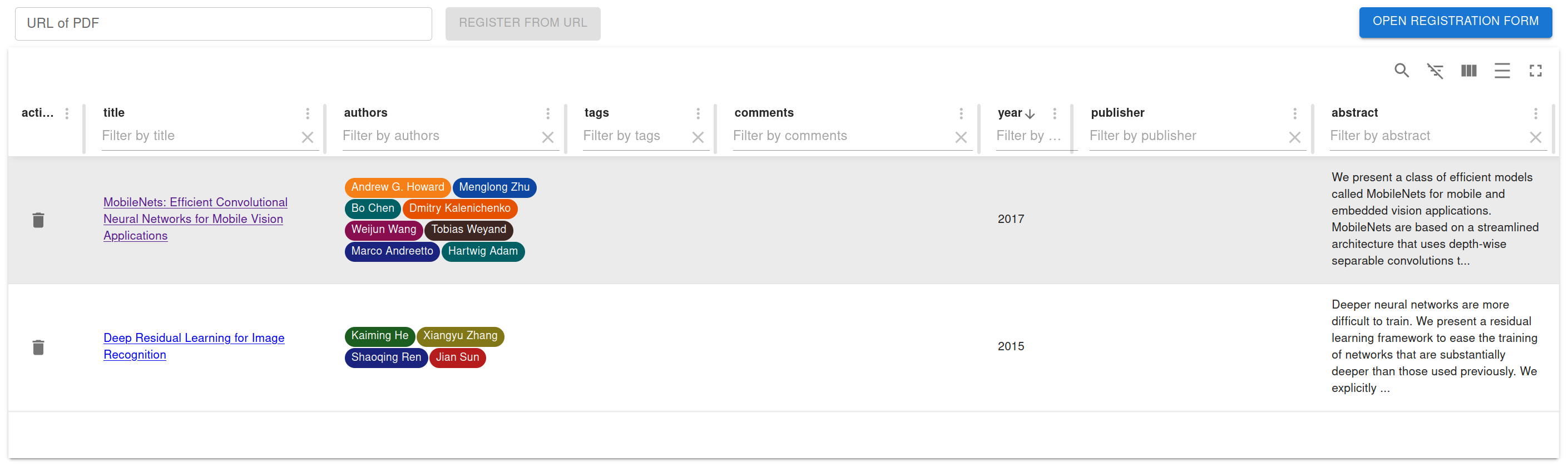 | ||
| 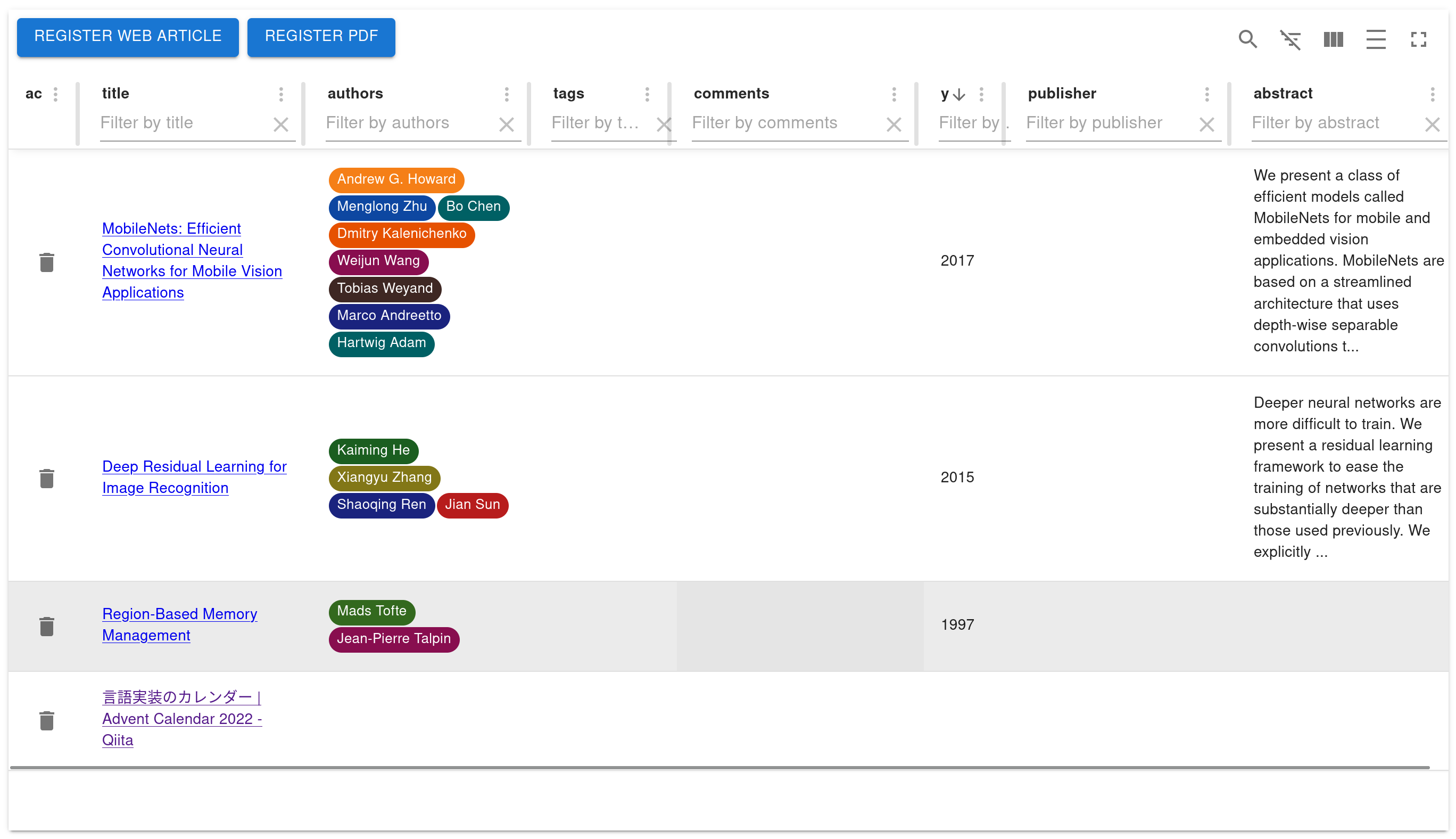 | ||
| If you don't have any PDFs, please use [Deep Residual Learning for Image Recognition](https://arxiv.org/pdf/1512.03385.pdf). | ||
| ## Launch automatically | ||
| #### If you want to launch `jendeley` automatically | ||
| When you are using Linux, you can launch `jendeley` automatically using `systemd`. Please make `~/.config/systemd/user/jendeley.service` with the following contents, run `systemctl --user enable jendeley && systemctl --user start jendeley` and access [http://localhost:5000](http://localhost:5000). You can check log with `journalctl --user -f -u jendeley.service`. | ||
@@ -33,0 +39,0 @@ ``` |
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
New alerts
License Policy Violation
LicenseThis package is not allowed per your license policy. Review the package's license to ensure compliance.
Found 1 instance in 1 package
Major refactor
Supply chain riskPackage has recently undergone a major refactor. It may be unstable or indicate significant internal changes. Use caution when updating to versions that include significant changes.
Found 1 instance in 1 package
Unidentified License
License(Experimental) Something that seems like a license was found, but its contents could not be matched with a known license.
Found 1 instance in 1 package
Fixed alerts
License Policy Violation
LicenseThis package is not allowed per your license policy. Review the package's license to ensure compliance.
Found 1 instance in 1 package
Major refactor
Supply chain riskPackage has recently undergone a major refactor. It may be unstable or indicate significant internal changes. Use caution when updating to versions that include significant changes.
Found 1 instance in 1 package
Unidentified License
License(Experimental) Something that seems like a license was found, but its contents could not be matched with a known license.
Found 1 instance in 1 package
Improved metrics
- Total package byte prevSize
- increased by0.16%
4226352
- Lines of code
- increased by2.09%
4944
- Number of lines in readme file
- increased by12%
56