Research
/Security News
Shai Hulud Strikes Again (v2)
Another wave of Shai-Hulud campaign has hit npm with more than 500 packages and 700+ versions affected.
By Socket Research Team - Nov 24, 2025
@clickup/magination
Advanced tools
An opinionated framework to build cursor-based pagination over multiple streams of hits
See also Full API documentation.
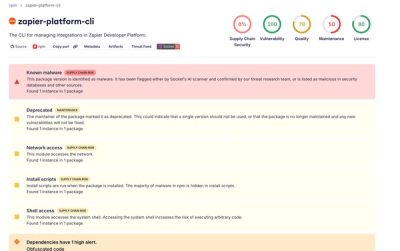
![]()
The problem: for some search request (e.g. search-by-keywords), we have multiple search queries (sources) with different performance that deliver results (hits) with different relevancy. We want to merge that search hits using "cursor based pagination pattern" (allowing the user to scroll search results with the mouse).
For example purposes, considering the following 3 kinds of sources:
When producing the cursored stream of pages, we must satisfy the following requirements:
Below is a cryptic diagram which illustrates, how it works:
source1: [b, m, n] |
source2: [a, b, c] | [d, e, f]
source3: [q, r] | [s, t]
---------------------------------------------------> time
1. Magination.load():
-> [b,m,n][a,c][q,r] + cursor
2. Magination.load(cursor):
-> [d,e,f][s,t] + cursor=null
Here, [...] means search results docs from some source, and "|" means that a search query returns a cursor which allows to re-run it from where it left off.
To guarantee that the docs are never repeated in the resulting stream of pages, the engine remembers all of the hits previously emitted; they are stored in the cache. Where possible, it saves the docs hash codes, but for the actual sources, we store the entire hits, because we may want to return to the previous pages too (plus, we do "preload-ahead" for sources).
FAQs
An opinionated framework to build cursor-based pagination over multiple streams of hits
We found that @clickup/magination demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 13 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Another wave of Shai-Hulud campaign has hit npm with more than 500 packages and 700+ versions affected.

Product
Add real-time Socket webhook events to your workflows to automatically receive software supply chain alert changes in real time.
Security News
ENISA has become a CVE Program Root, giving the EU a central authority for coordinating vulnerability reporting, disclosure, and cross-border response.