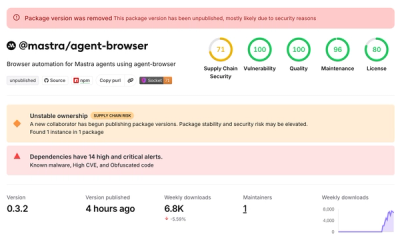
benchmark — Deterministic Agent Evaluation
This package exposes a consistent MCP workflow for deterministic benchmark-driven agent evaluation.
The rebuilt core is organized around challenge catalogs, typed task assets, and explicit checker kinds so coding, web, and OS-style tasks can share one MCP surface without relying on LLM judges.
Tools
list_challenges | List deterministic benchmark suites with family, runner, and checker metadata |
get_catalog_status | Inspect catalog source configuration, cache state, and availability |
sync_catalog | Fetch and cache the remote benchmark catalog when a URL source is configured |
start_challenge | Start an attempt and return the first task |
submit_solution | Grade one task and return checker evidence plus the next task or final score |
get_asset | Read an attached benchmark asset by asset_id |
get_attempt | Inspect attempt status, current task, and paginated evaluation history |
cancel_attempt | Cancel an active attempt |
Workflow
- Call
list_challenges
- Pick a
challenge_id
- Call
start_challenge
- If the task has assets, call
get_asset
- Call
submit_solution
- Repeat until
done: true
Each response includes machine-readable guidance for the most likely next tool call.
Fallback benchmark families
- Code — deterministic JSON/text answers backed by explicit checkers
- Web — DOM snapshot extraction tasks with JSON field assertions
- OS — filesystem/log review tasks with deterministic text grading
Zero-config run
Run with the bundled fallback catalog and no extra configuration:
npx @fre4x/benchmark
Or from this repo:
cd /home/fritzprix/my_works/b1te
npm run inspector -w @fre4x/benchmark
Mock Mode
Run with the same bundled fallback catalog in mock mode:
MOCK=true npx @fre4x/benchmark
Optional environment
BENCHMARK_CATALOG_FILE=/absolute/path/to/benchmark-catalog.json
BENCHMARK_CATALOG_URL=https://example.com/benchmark-catalog.json
BENCHMARK_CACHE_DIR=/absolute/path/to/catalog-cache
BENCHMARK_CACHE_TTL_SECONDS=3600
BENCHMARK_STATE_DIR=/absolute/path/to/store-attempt-json
BENCHMARK_MOCK=true
BENCHMARK_CATALOG_FILE: Optional JSON file with challenge definitions in the rebuilt deterministic catalog formatBENCHMARK_CATALOG_URL: Optional remote JSON catalog URL for fetch/cache based ingestionBENCHMARK_CACHE_DIR: Optional cache directory for remote catalog snapshotsBENCHMARK_CACHE_TTL_SECONDS: Freshness window for remote catalog cache reuseBENCHMARK_STATE_DIR: Where attempt files and lock directories are persistedBENCHMARK_MOCK: Alternate mock-mode flag
BENCHMARK_GAIA_DATA_FILE is still accepted as a backward-compatible alias, but the rebuilt package is no longer GAIA-first.
When BENCHMARK_CATALOG_URL is set, the package will reuse a fresh cached copy when available and can be explicitly refreshed with sync_catalog.
Catalog shape
External catalogs must be a JSON array of challenge definitions shaped like:
[
{
"challenge_id": "custom_suite",
"benchmark_id": "custom",
"family": "code",
"runner_kind": "code_runner",
"title": "Custom Challenge",
"description": "Deterministic single-task suite",
"version": "v1",
"source": "external",
"tasks": [
{
"task_id": "custom-1",
"title": "Return yes",
"prompt": "Return only yes.",
"response_format": "text",
"difficulty": 1,
"assets": [],
"checkers": [
{
"checker_id": "custom-yes",
"kind": "exact_text",
"expected": "yes"
}
]
}
]
}
]
Supported checker kinds today:
exact_textnormalized_textregex_matchcontains_all_textjson_field_equalsrunner_fact_equalsrunner_log_contains_text
Each submission now also records runner execution metadata:
- workspace directory
- materialized asset and submission artifacts
- runner facts
- runner logs
Example external catalog
The repo includes the bundled fallback catalog source at:
benchmark/catalogs/expanded-catalog.json
Use it like this:
cd /home/fritzprix/my_works/b1te
BENCHMARK_CATALOG_FILE=/home/fritzprix/my_works/b1te/benchmark/catalogs/expanded-catalog.json npm run inspector -w @fre4x/benchmark
If no catalog env is provided at runtime, the published package falls back to the bundled copy of this catalog automatically.
Claude Desktop
{
"mcpServers": {
"benchmark": {
"command": "npx",
"args": ["-y", "@fre4x/benchmark"],
"env": {
"BENCHMARK_CATALOG_URL": "https://example.com/benchmark-catalog.json",
"BENCHMARK_CACHE_DIR": "/absolute/path/to/benchmark-cache"
}
}
}
}
Development
npm install
npm run build -w @fre4x/benchmark
npm run typecheck -w @fre4x/benchmark
npm test -w @fre4x/benchmark
MOCK=true npm run inspector -w @fre4x/benchmark