Research
/Security News
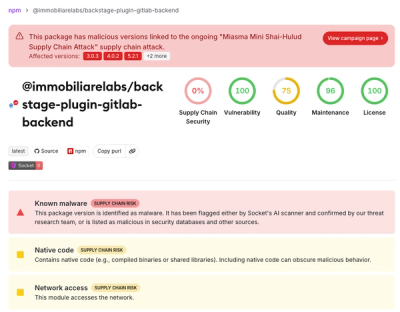
Miasma Mini Shai-Hulud Hits ImmobiliareLabs npm Packages
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.
By Socket Research Team - Jun 26, 2026
@qvac/tts-ggml
Advanced tools
Text to Speech (TTS) addon for qvac (ggml backend, wrapping the chatterbox + supertonic engines from tts-cpp)
Text-to-speech Bare addon backed by the qvac-tts.cpp
GGML library. Currently ships the Chatterbox Turbo English model;
additional engines will land under the same package as the upstream
library grows.
Runs in-process with a persistent native engine — the GGUFs, the S3Gen
preload, the ggml backend, and any voice-conditioning tensors are
loaded once and reused across every synthesis call. GPU acceleration
(Metal on macOS/iOS, Vulkan / OpenCL on Linux/Windows)
is opt-in via config: { useGPU: true }; the default is CPU. On
Android useGPU flows through to tts-cpp, which picks the GPU
backend per its own per-vendor allowlist (Supertonic on Adreno/OpenCL,
Xclipse/Vulkan, Mali/Vulkan; Chatterbox on Adreno/Xclipse, declined to
CPU on Mali) (see
Backends & GPU acceleration).
run({ input }) → single PCM buffer).runStreaming(asyncIterable):
yields one audio chunk per input sentence.streamChunkTokens and audio
flows out of the C++ engine chunk-by-chunk as T3 tokens produce
S3Gen+HiFT output; sub-second first-audio-out inside a single
utterance.config.useGPU: true on GPU-capable hosts — including Android, where
tts-cpp selects the GPU backend per its per-vendor allowlist (see
Backends & GPU acceleration)..so files ship under prebuilds/<bare-target>/qvac__tts-ggml/
and are picked up at runtime via the new backendsDir option (see
Backends & GPU acceleration).model.cancel() — stops T3 decode on the next
token; in-flight S3Gen chunk runs to completion.npm install @qvac/tts-ggml
Requires Bare >=1.19.0.
Prebuilds are published for darwin-arm64, android-arm64, ios-arm64;
Linux x64 / Windows prebuilds coming as demand warrants. If your
platform has no prebuild the package falls back to a local build via
bare-make + cmake-vcpkg (see Build from source).
Two engines are wrapped, each with its own GGUF layout under models/:
# Chatterbox turbo (English)
chatterbox-t3-turbo.gguf (~742 MB) — T3 GPT-2 Medium + BPE + VoiceEncoder
chatterbox-s3gen.gguf (~1.0 GB) — S3Gen encoder/CFM + HiFT + CAMPPlus + S3TokenizerV2
# Chatterbox multilingual (en/es/fr/de/pt/it/zh/ja/ko/...)
chatterbox-t3-mtl.gguf (~1.0 GB)
chatterbox-s3gen-mtl.gguf (~1.0 GB)
# Supertonic English (Supertone/supertonic; 44.1 kHz, voice baked in)
supertonic.gguf (~263 MB)
# Supertonic multilingual (Supertone/supertonic-2; en/ko/es/pt/fr)
supertonic2.gguf (~263 MB)
The package converts these from upstream Resemble Chatterbox / Supertone checkpoints via a Python venv pipeline:
npm run setup-models # creates ./venv, installs requirements.txt, runs convert-models.sh
Or step-by-step:
npm run setup:venv
npm run convert-models
Point the addon at a custom location via files.modelDir (engine
auto-detected from the gguf filenames present), or pass explicit
files.t3Model + files.s3genModel (Chatterbox) /
files.supertonicModel (Supertonic).
const TTSGgml = require('@qvac/tts-ggml')
const model = new TTSGgml({
files: { modelDir: './models' }, // contains chatterbox-{t3-turbo,s3gen}.gguf
config: { language: 'en' },
opts: { stats: true }
})
await model.load()
const response = await model.run({
type: 'text',
input: 'Hello from qvac tts ggml.'
})
let pcm = []
await response
.onUpdate(data => {
if (data && data.outputArray) pcm = pcm.concat(Array.from(data.outputArray))
})
.await()
// pcm is Int16 mono @ 24 kHz
await model.unload()
runStreaming(asyncIter)Use when your text arrives as discrete sentences (e.g. buffered LLM
output) and you want the audio to flow sentence-by-sentence. One
onUpdate event per input yield.
async function * sentencesOverTime () {
yield 'First sentence.'
await new Promise(r => setTimeout(r, 200))
yield 'The second arrives shortly after.'
}
const response = await model.runStreaming(sentencesOverTime())
await response.onUpdate(data => {
// data.outputArray — Int16 PCM for this sentence's audio
// data.chunkIndex — 0-based index of the yielded sentence
// data.sentenceChunk — the sentence text that produced this audio
}).await()
Full runnable demo (with streaming playback):
bare examples/chatterbox-sentence-stream-tts.js
streamChunkTokensUse when you want the fastest possible first-audio-out within a
single utterance. The C++ engine splits each synthesis into chunks
of streamChunkTokens speech tokens (25 ≈ 1 s of audio) and emits
audio per chunk, keeping HiFT's source cache phase-continuous across
seams so the joins are inaudible.
const model = new TTSGgml({
files: { modelDir: './models' },
referenceAudio: './voices/jfk.wav', // optional
streamChunkTokens: 25, // ~1 s of audio per chunk
streamFirstChunkTokens: 10, // smaller first chunk = faster first-audio-out
cfmSteps: 1, // 1-step meanflow: halves CFM cost
config: { language: 'en' }
})
await model.load()
const response = await model.run({ input: 'A long sentence produces many chunks...' })
await response.onUpdate(data => {
if (data && data.outputArray) playPcmChunk(data.outputArray)
}).await()
Full runnable demo (with gapless playback via sox or ffplay):
bare examples/chatterbox-chunk-stream-tts.js
Pass a mono wav ≥ 5 s of clean speech — the engine does the loudness
normalisation (−27 LUFS), resampling, and all conditioning (VoiceEncoder,
CAMPPlus, S3TokenizerV2, mel extraction) natively at load() time:
const model = new TTSGgml({
files: { modelDir: './models' },
referenceAudio: './voices/me.wav',
config: { language: 'en' }
})
Alternatively point at a pre-baked profile directory produced by the
upstream CLI's --save-voice DIR (loads .npy tensors; skips the
preprocessing entirely):
new TTSGgml({
files: { modelDir: './models' },
voiceDir: './voices/me/',
})
When both are supplied, missing tensors in voiceDir are backfilled
from referenceAudio.
The addon delegates backend selection to tts-cpp's registry-only
init path. At load() time the engine walks the ggml-backend registry
once and picks the first available accelerator that matches the
host's policy:
| Platform | Default backend when useGPU: true |
|---|---|
| macOS / iOS | Metal |
| Linux / Windows | Vulkan |
| Android — Adreno 700+ | OpenCL |
| Android — Mali / others | Vulkan |
| Everything else / CPU-only build | CPU |
Chatterbox on ARM Mali is the one exception to the table:
tts-cppdeclines Mali for the Chatterbox / S3Gen graph (allow_arm_mali=false) and runs it on CPU there (reported viastats.gpuUnsupported). Supertonic runs on Mali via Vulkan.
Android prebuilds enable GGML_BACKEND_DL=ON and ship per-arch
backend .so files under
prebuilds/<bare-target>/qvac__tts-ggml/.
The engine dlopen()s the highest-tier CPU variant the device's
HWCAPs support and one of the GPU .so files based on the policy
table above. Hosts must pass backendsDir: path.join(__dirname, 'prebuilds') (or rely on the default fallback the package ships)
so the runtime knows where to look. openclCacheDir is also
Android-specific; setting it to a writable path lets the OpenCL
backend persist its compiled program cache across launches.
new TTSGgml(options)| Option | Type | Default | Notes |
|---|---|---|---|
files.modelDir | string | — | Dir containing the two GGUFs |
files.t3Model | string | — | Overrides modelDir for T3 |
files.s3genModel | string | — | Overrides modelDir for S3Gen |
referenceAudio | string | — | Mono wav ≥ 5 s for voice cloning |
voiceDir | string | — | Pre-baked voice profile |
seed | number | 42 | RNG seed (CFM noise + sampling) |
nGpuLayers | number | 0 | Layers offloaded to GPU (mirrors useGPU; pass 99 to offload all) |
nCtx | number | 4096 | Cap on the T3 context (prompt + generated speech tokens; 25 tokens ≈ 1 s of audio). The KV cache is allocated up-front at this length, so it directly bounds memory: the Turbo GGUF's native n_ctx=8196 would cost ~1.6 GB of f32 KV vs ~390 MB at the defaults (4096 + f16). Pass 0 to use the GGUF's full context |
kvCacheType | string | f16 | T3 KV-cache dtype: f32 | f16 | q8_0. f16 (~50% of f32) is the safe cross-backend default. q8_0 stores the cache at ~27% of f32 and decodes 20-30% faster on Metal, but only works on backends with a q8_0 CONT op (CPU, CUDA) — it hard-aborts the multilingual model on Metal, so it is opt-in. Turbo greedy decoding is byte-identical across all three (upstream-validated). Pass f32 for bit-exact pre-quantisation behaviour |
threads | number | hw.concurrency capped at 4 | |
streamChunkTokens | number | 0 | >0 enables native chunk streaming |
streamFirstChunkTokens | number | = streamChunkTokens | Smaller first chunk for low first-audio-out |
cfmSteps | number | 2 | 1 = faster (halved CFM cost) |
backendsDir | string | path.join(__dirname, 'prebuilds') | Root dir the addon scans for dynamically-loaded ggml backend .so files. Required on Android (host should pass path.join(__dirname, 'prebuilds')); ignored on platforms that statically link the backend |
openclCacheDir | string | unset | Android-only: directory where the OpenCL backend persists its compiled program-binary cache. Setting it across runs avoids re-JITing the kernels on every fresh process |
config.language | string | "en" | Chatterbox MTL accepts es/fr/de/pt/it/zh/ja/ko/...; turbo & Supertonic are English |
config.useGPU | boolean | false | Set to true to route through Metal / Vulkan / CUDA / OpenCL if available. Honored for both engines on GPU-capable hosts, including Android, where tts-cpp selects the GPU backend per its per-vendor allowlist (Chatterbox falls back to CPU on Mali) |
config.outputSampleRate | number | 24000 | Resample native 24 kHz output |
opts.stats | boolean | false | Populate response.stats with RTF, backendDevice (0=CPU, 1=GPU), backendId (0=CPU, 1=Metal, 3=Vulkan, 4=OpenCL, 99=other) etc. |
opts.exclusiveRun | boolean | false | Serialize overlapping streaming runs |
await model.load() — construct the native engine (loads T3, preloads
S3Gen, bakes voice conditioning). Subsequent run() calls reuse all
of it.await model.unload() — release everything. Idempotent.await model.reload(newConfig) — re-create the engine with a new
config (language, useGPU, outputSampleRate, …).await model.destroy() — unload() + mark this instance dead.await model.cancel() — best-effort cancel of any in-flight run.model.run({ input, type: 'text' }) → QvacResponse.model.run({ input, streamOutput: true }) → sentence-chunked
synthesis driven by the JS-side sentence splitter (see
lib/textChunker.js). Equivalent to runStream(input).model.runStream(text, { locale?, maxChunkScalars? }) → same as
above, but the options read more naturally for the "split this long
string" use case.model.runStreaming(textStream, opts) → streaming input + streaming
output (see Sentence streaming).All run* methods return a QvacResponse (from @qvac/infer-base):
response.onUpdate(data => {
data.outputArray // Int16Array — 24 kHz mono PCM
data.sampleRate // 24000
data.chunkIndex // present on sentence-streaming events only
data.sentenceChunk // present on sentence-streaming events only
})
await response.await()
// response.stats — only when constructor had `opts: { stats: true }`
response.stats.totalTime // seconds
response.stats.realTimeFactor // synthesis time / audio duration
response.stats.audioDurationMs
response.stats.totalSamples
response.stats.tokensPerSecond
Runnable demos under examples/:
| Script | Demonstrates |
|---|---|
chatterbox-tts.js | Batch synth + wav dump. bare examples/chatterbox-tts.js "Hello" |
chatterbox-sentence-stream-tts.js | runStreaming() over an async iterator of sentences, with gapless streaming playback |
chatterbox-chunk-stream-tts.js | Native per-chunk PCM streaming via streamChunkTokens, with gapless streaming playback |
The two streaming examples feed PCM into a single long-running
sox play / ffplay process so chunks play back-to-back without any
per-chunk spawn gaps — install one of them (brew install sox or
brew install ffmpeg on macOS) to enable playback. Absent a player
the demos still run and write the concatenated wav.
npm run test:unit # mocked binding; fast
npm run test:integration # spins up the real engine; needs models
npm run test # both
Integration tests scan a few candidate models/ directories for the
required GGUFs (see test/utils/downloadModel.js) and skip cleanly when
files are absent. They cover, across both engines:
runStream / run({ streamOutput: true })
/ runStreaming over async iterators),streamChunkTokens),response.stats.backendDevice +
backendId (set NO_GPU=true to skip on CPU-only runners,
QVAC_TTS_GPU_SMOKE_RELAX=1 to downgrade the strict gate to a
warning),chatterbox-mtl.test.js,To stress-test long inputs, set INPUT_SENTENCES=medium (or long)
and re-run the integration suite — addon.test.js reads the env var to
pick its sentence corpus from test/data/sentences-{medium,long}.js.
Prerequisites: clang with C++20 support, CMake ≥ 3.25,
vcpkg (set VCPKG_ROOT), bare-make.
npm install
npx bare-make generate # configures + fetches the tts-cpp port
npx bare-make build
npx bare-make install # copies the .bare into prebuilds/<triple>/
The vcpkg port is hosted in
tetherto/qvac-registry-vcpkg and pulls
qvac-tts.cpp at a pinned REF. See
vcpkg-configuration.json for the
baseline commit.
GPU backends are controlled by the tts-cpp port's vcpkg features:
metal (default on osx/ios), vulkan (default on
linux/windows/android), opencl (default on android).
On Android the port is configured with
GGML_BACKEND_DL=ON + GGML_CPU_ALL_VARIANTS=ON, so the build
produces per-arch CPU + Vulkan + OpenCL .so files alongside the
.bare module instead of statically linking; the resulting prebuilds
layout is what the backendsDir option expects (see
Backends & GPU acceleration).
t3 model not found / supertonic model not found — the paths in
files are wrong or the GGUFs weren't generated. Run
npm run setup-models (creates the Python venv and converts the
upstream checkpoints into the four / five expected GGUF files).
VoiceEncoder forward failed when passing referenceAudio** —
the reference wav is likely < 5 s of clean speech. Make it longer
(10–15 s gives the best similarity).
Crash on process exit with Metal's [rsets->data count] == 0
assertion — you're running on a build before the s3gen_unload()
teardown fix; bump the tts-cpp port to >= 2026-04-21 port-version.
Slower-than-expected RTF on darwin — set config: { useGPU: true }
(the default is now CPU; see Constructor
metal feature. Also confirm
your reference wav's mel was baked (Using C++ VoiceEncoder /
C++ S3TokenizerV2 messages in the log) — if voice conditioning
falls back to CPU, a chunk of the first-call overhead is visible in
RTF.Slow-but-otherwise-fine RTF on Android — set config: { useGPU: true } (the default is CPU; see
Backends & GPU acceleration) and confirm
your device's GPU is on tts-cpp's per-vendor allowlist. Chatterbox is
declined to CPU on ARM Mali, so on a Mali device that engine stays on
CPU regardless; Supertonic runs on the GPU there.
Apache-2.0. See LICENSE.
FAQs
Text to Speech (TTS) addon for qvac (ggml backend, wrapping the chatterbox + supertonic engines from tts-cpp)
We found that @qvac/tts-ggml demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.

Security News
Rolldown paused Rust React Compiler integration after a 5MB binary size increase raised concerns about shipping React-specific code to all Vite users.

Security News
/Research
Mini Shai-Hulud expands into the Go ecosystem after hitting LeoPlatform npm packages and targeting GitHub Actions workflows.