Research
/Security News
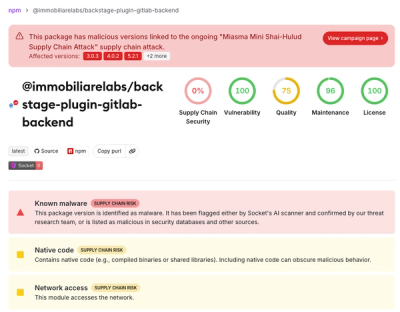
Miasma Mini Shai-Hulud Hits ImmobiliareLabs npm Packages
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.
By Socket Research Team - Jun 26, 2026
@qvac/vla-ggml
Advanced tools
Technology Stack: C++20, CMake, vcpkg, Bare Runtime, ggml Package Type: Native Bare addon
A vision-language-action (VLA) inference addon for the Bare runtime, running
SmolVLA and Physical
Intelligence π₀.₅ on
ggml. Given camera frames and a natural-language instruction, it produces a
chunk of robot actions ready to dispatch to a manipulator. The model
architecture is selected automatically from the GGUF general.architecture
key, so the same VlaModel API serves both.
IVlaModel interface dispatches on the
GGUF general.architecture key; legacy weights without the key load as
SmolVLA. Every sub-graph of both models is parity-tested against a PyTorch
reference at cos > 0.999.addon/src/utils/BackendSelection.cpp.Both architectures ship as a single unified GGUF (vision tower, language
model, action expert, and flow-matching projections in one file) and are
loaded through the same VlaModel API; getVlaHparams() reports the
per-architecture shape so callers can adapt.
| Model | GGUF general.architecture | Cameras | Robot state | Default fixture |
|---|---|---|---|---|
| SmolVLA | smolvla (or no key — legacy) | 2 | continuous (state Float32Array) | HuggingFaceVLA/smolvla_libero, ~1.9 GB |
| π₀.₅ | pi05 | 3 | discrete — encoded as text in the prompt (state arg ignored) | pi05_base.gguf |
For π₀.₅ the prompt is not just the instruction: following the openpi /
PaliGemma-VLA convention, the caller builds a templated prompt
(Task: <instruction>, State: <state>;\nAction:) where the quantile-normalised
robot state is discretised and rendered as text into the State: segment, then
tokenises the whole string. That token array is passed as the usual
tokens/mask input; the addon's separate state argument is ignored for
π₀.₅ (pass an empty Float32Array). SmolVLA, by contrast, takes the instruction
as the prompt and the robot state as the continuous state vector. For
converting LeRobot / openpi π₀.₅ checkpoints to GGUF and the quantization
profiles, see scripts/README-pi05-converter.md.
npm install @qvac/vla-ggml
The package ships prebuilt native binaries for linux-x64, linux-arm64, darwin-arm64, darwin-x64, ios-arm64 (+ simulator), android-arm64, and win32-x64. No build step required for consumers.
const { VlaModel, preprocessImage, padState } = require('@qvac/vla-ggml')
const model = new VlaModel({
files: { model: ['/path/to/smolvla-libero-vision-q8.gguf'] },
opts: { stats: true } // populate per-stage timings on the response
})
await model.load() // backend defaults to 'auto' (GPU when available, CPU otherwise)
const { hparams } = model
const size = hparams.visionImageSize // 512
// Note: `imgWidth` and `imgHeight` passed to `model.run` MUST equal
// `hparams.visionImageSize`. Resize / letterbox up front with
// `preprocessImage(..., { size })`; the addon rejects mismatches.
const front = preprocessImage(frontPixels, frontW, frontH, { size })
const wrist = preprocessImage(wristPixels, wristW, wristH, { size })
const tokens = new Int32Array(hparams.tokenizerMaxLength)
const mask = new Uint8Array(hparams.tokenizerMaxLength)
// ... tokenize the instruction with SmolVLM2 tokenizer (consumer-side) ...
const state = padState(robotEefAndGripperState, hparams.maxStateDim)
const noise = new Float32Array(hparams.chunkSize * hparams.maxActionDim)
crypto.getRandomValues(new Uint8Array(noise.buffer)) // or your seeded prior
const response = await model.run({
images: [front, wrist],
imgWidth: size,
imgHeight: size,
state,
tokens,
mask,
noise
})
const { actions, stats } = await response.await()
// actions: Float32Array, length = chunkSize * actionDim (50 × 7 by default)
The example above is SmolVLA (2 cameras, continuous state vector). π₀.₅ takes
up to 3 images and ignores the state argument — the caller instead encodes
robot state as text inside the prompt (Task: …, State: …;\nAction:) before
tokenising (see Models). Check hparams.numCameras /
hparams.stateInputMode after load() rather than hard-coding the input shape.
| Export | What |
|---|---|
VlaModel | Async model wrapper. Constructor takes { files, config?, logger?, opts? }. Call await model.load({ backend? }) then await (await model.run(input)).await(). |
preprocessImage(pixels, w, h, { size, layout, scale }) | Resize + letterbox + normalize a camera frame to (3, size, size) Float32 in [-1, 1]. scale accepts 1 (already 0..1), 1/255 (input is 0..255), or 'auto' (default heuristic). |
padState(state, targetDim) | Zero-pad a robot-state vector to the model's maxStateDim. |
Full TypeScript types in index.d.ts. |
The addon picks a GPU at load time when backend: 'auto' (the default).
Non-Adreno GPUs are accepted. On Adreno hardware:
When no acceptable GPU is found the addon falls back to CPU; to force CPU
regardless, pass backend: 'cpu' to load().
Build from source:
npm install
bare-make generate
bare-make build
bare-make install
Tests:
npm run test:unit # brittle JS unit tests
npm run test:integration # end-to-end with a real GGUF (set QVAC_VLA_MODEL)
npm run test:cpp # GoogleTest C++ unit tests
LIBERO closed-loop simulation eval (PyTorch reference vs QVAC GGUF):
see sim/README.md.
@qvac/vla-ggml itself is Apache-2.0. Bundled third-party components are governed
by their respective licenses; see NOTICE.
FAQs
VLA vision-language-action inference addon for QVAC (ggml backend)
The npm package @qvac/vla-ggml receives a total of 9,033 weekly downloads. As such, @qvac/vla-ggml popularity was classified as popular.
We found that @qvac/vla-ggml demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.

Security News
Rolldown paused Rust React Compiler integration after a 5MB binary size increase raised concerns about shipping React-specific code to all Vite users.

Security News
/Research
Mini Shai-Hulud expands into the Go ecosystem after hitting LeoPlatform npm packages and targeting GitHub Actions workflows.