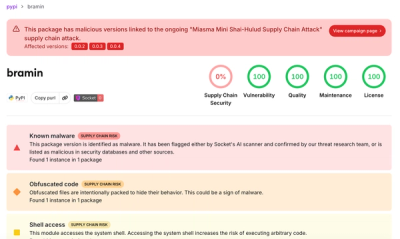
@ruvector/ruvllm v2.3
Self-learning LLM orchestration with SONA adaptive learning, HNSW memory, and SIMD inference for Node.js.
Installation
npm install @ruvector/ruvllm
Quick Start
import { RuvLLM, RuvLLMConfig } from '@ruvector/ruvllm';
const llm = new RuvLLM();
const llm = new RuvLLM({
modelPath: './models/ruvltra-small-q4km.gguf',
sonaEnabled: true,
flashAttention: true,
maxTokens: 256,
});
const response = await llm.query('Explain quantum computing');
console.log(response.text);
for await (const token of llm.stream('Write a haiku about Rust')) {
process.stdout.write(token);
}
What's New in v2.3
| RuvLTRA Models | Purpose-built 0.5B & 3B models for Claude Flow |
| Task-Specific LoRA | 5 pre-trained adapters (coder, researcher, security, architect, reviewer) |
| HuggingFace Hub | Download/upload models directly |
| Adapter Merging | TIES, DARE, SLERP strategies |
| HNSW Routing | 150x faster semantic matching |
| Evaluation Harness | SWE-Bench testing with 5 ablation modes |
| Auto-Dimension | HNSW auto-detects model embedding size |
| mistral-rs Backend | Production serving with PagedAttention, X-LoRA, ISQ (5-10x concurrent users) |
CLI Usage
ruvllm query "What is machine learning?"
ruvllm query --stream "Write a poem"
ruvllm download ruvector/ruvltra-small-q4km
ruvllm bench ./models/model.gguf
ruvllm eval --model ./models/model.gguf --subset lite --max-tasks 50
API Reference
RuvLLM Class
class RuvLLM {
constructor(config?: RuvLLMConfig);
query(prompt: string, params?: GenerateParams): Promise<Response>;
stream(prompt: string, params?: GenerateParams): AsyncIterable<string>;
loadModel(path: string): Promise<void>;
sonaStats(): SonaStats | null;
adapt(input: Float32Array, quality: number): void;
}
Configuration
interface RuvLLMConfig {
modelPath?: string;
sonaEnabled?: boolean;
flashAttention?: boolean;
maxTokens?: number;
temperature?: number;
topP?: number;
}
Generate Parameters
interface GenerateParams {
maxTokens?: number;
temperature?: number;
topP?: number;
topK?: number;
repetitionPenalty?: number;
stopSequences?: string[];
}
SIMD Module
For direct access to optimized SIMD kernels:
import { simd } from '@ruvector/ruvllm/simd';
const result = simd.dotProduct(vecA, vecB);
const output = simd.matmul(matrix, vector);
const attended = simd.flashAttention(query, key, value, scale);
simd.rmsNorm(hidden, weights, epsilon);
Performance (M4 Pro)
| Inference | 88-135 tok/s |
| Flash Attention | 320µs (seq=2048) |
| HNSW Search | 17-62µs |
| SONA Adapt | <1ms |
| Evaluation | 5 ablation modes |
Evaluation Harness
Run model evaluations with SWE-Bench integration:
import { RuvLLM, EvaluationHarness, AblationMode } from '@ruvector/ruvllm';
const harness = new EvaluationHarness({
modelPath: './models/model.gguf',
enableHnsw: true,
enableSona: true,
});
const result = await harness.evaluate(
'Fix the null pointer exception',
'def process(data): return data.split()',
AblationMode.Full
);
console.log(`Success: ${result.success}, Quality: ${result.qualityScore}`);
const report = await harness.runAblationStudy(tasks);
for (const [mode, metrics] of Object.entries(report.modeMetrics)) {
console.log(`${mode}: ${metrics.successRate * 100}% success`);
}
mistral-rs Backend (Production Serving)
For production deployments with 10-100+ concurrent users, use the mistral-rs backend:
import { RuvLLM, MistralBackend, PagedAttentionConfig } from '@ruvector/ruvllm';
const backend = new MistralBackend({
pagedAttention: {
blockSize: 16,
maxBlocks: 4096,
gpuMemoryFraction: 0.9,
prefixCaching: true,
},
xlora: {
adapters: ['./adapters/coder', './adapters/researcher'],
topK: 2,
},
isq: {
bits: 4,
method: 'awq',
},
});
const llm = new RuvLLM({ backend });
await llm.loadModel('mistralai/Mistral-7B-Instruct-v0.2');
const response = await llm.query('Write production code');
Note: mistral-rs features require the Rust backend with mistral-rs feature enabled. Native bindings will use mistral-rs when available.
Supported Models
- RuvLTRA-Small (494M) - Q4K, Q5K, Q8
- RuvLTRA-Medium (3B) - Q4K, Q5K, Q8
- Qwen 2.5 (0.5B-72B)
- Llama 3.x (8B-70B)
- Mistral (7B-22B)
- Phi-3 (3.8B-14B)
- Gemma-2 (2B-27B)
Platform Support
| macOS | arm64 (M1-M4) | ✅ Full support |
| macOS | x64 | ✅ Supported |
| Linux | x64 | ✅ Supported |
| Linux | arm64 | ✅ Supported |
| Windows | x64 | ✅ Supported |
Related Packages
Links
License
MIT OR Apache-2.0