@u4/opencv4nodejs
Advanced tools
@u4/opencv4nodejs - npm Package Compare versions
Comparing version 6.1.0 to 6.1.1
@@ -26,2 +26,3 @@ "use strict"; | ||
| function getTextSize(text, opts) { | ||
| opts = opts || {}; | ||
| const fontType = opts.fontSize || DefaultTextParams.fontType; | ||
@@ -28,0 +29,0 @@ const fontSize = opts.fontSize || DefaultTextParams.fontSize; |
@@ -52,3 +52,4 @@ import type * as openCV from '../..'; | ||
| */ | ||
| function getTextSize(text: string, opts: Partial<TextParams>): TextDimention { | ||
| function getTextSize(text: string, opts?: Partial<TextParams>): TextDimention { | ||
| opts = opts || {}; | ||
| const fontType = opts.fontSize || DefaultTextParams.fontType; | ||
@@ -55,0 +56,0 @@ const fontSize = opts.fontSize || DefaultTextParams.fontSize; |
| { | ||
| "name": "@u4/opencv4nodejs", | ||
| "version": "6.1.0", | ||
| "version": "6.1.1", | ||
| "description": "Asynchronous OpenCV 3.x / 4.x nodejs bindings with JavaScript and TypeScript API.", | ||
@@ -37,14 +37,2 @@ "keywords": [ | ||
| "typings": "./typings/index.d.ts", | ||
| "scripts": { | ||
| "prepack": "tsc", | ||
| "install_macm1": "tsc && node bin/install.js --version 4.5.4 --flag=\"-DCMAKE_SYSTEM_PROCESSOR=arm64 -DCMAKE_OSX_ARCHITECTURES=arm64\" rebuild", | ||
| "install_4.5.5_cuda": "tsc && node bin/install.js --version 4.5.5 --flags=\"-DWITH_CUDA=ON -DWITH_CUDNN=ON -DOPENCV_DNN_CUDA=ON -DCUDA_FAST_MATH=ON\" rebuild", | ||
| "samples": "tsc && node ./examples/templateMatching.js && node ./examples/applyColorMap.js && node ./examples/asyncMatchFeatures.js && node ./examples/faceDetect/asyncFaceDetection.js", | ||
| "do-build": "tsc && node bin/install.js --jobs 4 build", | ||
| "do-rebuild": "tsc && node bin/install.js --jobs 4 rebuild", | ||
| "lint": "eslint examples/**/*.ts lib/**/*.ts typings/**/*.ts ", | ||
| "clean": "node-gyp clean", | ||
| "cleanjs": "rimraf {install,lib,examples}/**/*.{d.ts,js,map}", | ||
| "build-debug": "tsc && BINDINGS_DEBUG=true node bin/install.js rebuild" | ||
| }, | ||
| "dependencies": { | ||
@@ -82,3 +70,15 @@ "@u4/opencv-build": "^0.4.3", | ||
| "_binding.gyp" | ||
| ] | ||
| } | ||
| ], | ||
| "scripts": { | ||
| "install_macm1": "tsc && node bin/install.js --version 4.5.4 --flag=\"-DCMAKE_SYSTEM_PROCESSOR=arm64 -DCMAKE_OSX_ARCHITECTURES=arm64 -DWITH_FFMPEG=ON\" rebuild", | ||
| "install_cuda": "tsc && node bin/install.js --version 4.5.5 --flags=\"-DWITH_CUDA=ON -DWITH_CUDNN=ON -DOPENCV_DNN_CUDA=ON -DCUDA_FAST_MATH=ON -DWITH_FFMPEG=ON\" rebuild", | ||
| "samples": "tsc && node ./examples/templateMatching.js && node ./examples/applyColorMap.js && node ./examples/asyncMatchFeatures.js && node ./examples/faceDetect/asyncFaceDetection.js", | ||
| "do-build": "tsc && node bin/install.js --flags=\"-DWITH_FFMPEG=ON\" --jobs 4 build", | ||
| "do-rebuild": "tsc && node bin/install.js --flags=\"-DWITH_FFMPEG=ON\" --jobs 4 rebuild", | ||
| "lint": "eslint examples/**/*.ts lib/**/*.ts typings/**/*.ts ", | ||
| "clean": "node-gyp clean", | ||
| "cleanjs": "rimraf {install,lib,examples}/**/*.{d.ts,js,map}", | ||
| "build-debug": "tsc && BINDINGS_DEBUG=true node bin/install.js rebuild" | ||
| }, | ||
| "readme": "# @u4/opencv4nodejs\r\n\r\n[](https://www.npmjs.org/package/@u4/opencv4nodejs)\r\n\r\n## Fork changes\r\n\r\n- I recomand you to only define an global OPENCV_BUILD_ROOT=~/opencv to boost you develepoment speed and reduce you hard disk usage.\r\n- `node-gyp` is not run during `npm install`, It must be launch from the project with `build-opencv`. (if you forgot to do so some help message will assis you :wink:)\r\n- All javascript code had been converted to Typesscript.\r\n- This version depend on [@u4/opencv-build](https://www.npmjs.com/package/@u4/opencv-build).\r\n- This version had been test under windows / MacOs X / Debian environnement.\r\n- This version **Works** with new elecron.\r\n\r\n\r\n\r\n[](https://www.npmjs.com/package/@u4/opencv4nodejs)\r\n[](http://nodejs.org/download/)\r\n\r\n**opencv4nodejs allows you to use the native OpenCV library in nodejs. Besides a synchronous API the package provides an asynchronous API, which allows you to build non-blocking and multithreaded computer vision tasks. opencv4nodejs supports OpenCV 3 and OpenCV 4.**\r\n\r\n**The ultimate goal of this project is to provide a comprehensive collection of nodejs bindings to the API of OpenCV and the OpenCV-contrib modules. To get an overview of the currently implemented bindings, have a look at the [type declarations](https://github.com/urielch/opencv4nodejs/tree/master/typings) of this package. Furthermore, contribution is highly appreciated. If you want to add missing bindings check out the [contribution guide](https://github.com/urielch/opencv4nodejs/tree/master/CONTRIBUTING.md).**\r\n\r\n- **[Examples](#examples)**\r\n- **[How to install](#how-to-install)**\r\n- **[Usage with Docker](#usage-with-docker)**\r\n- **[Usage with Electron](#usage-with-electron)**\r\n- **[Usage with NW.js](#usage-with-nwjs)**\r\n- **[Quick Start](#quick-start)**\r\n- **[Async API](#async-api)**\r\n- **[With TypeScript](#with-typescript)**\r\n- **[External Memory Tracking (v4.0.0)](#external-mem-tracking)**\r\n<a name=\"examples\"></a>\r\n\r\n## Examples\r\n\r\nSee [examples](https://github.com/UrielCh/opencv4nodejs/tree/master/examples) for implementation.\r\n\r\n### Face Detection\r\n\r\n\r\n\r\n\r\n### Face Recognition with the OpenCV face module\r\n\r\nCheck out [Node.js + OpenCV for Face Recognition](https://medium.com/@muehler.v/node-js-opencv-for-face-recognition-37fa7cb860e8)</b></a>.\r\n\r\n\r\n\r\n### Face Landmarks with the OpenCV face module\r\n\r\n\r\n\r\n### Face Recognition with [face-recognition.js](https://github.com/justadudewhohacks/face-recognition.js)\r\n\r\nCheck out [Node.js + face-recognition.js : Simple and Robust Face Recognition using Deep Learning](https://medium.com/@muehler.v/node-js-face-recognition-js-simple-and-robust-face-recognition-using-deep-learning-ea5ba8e852).\r\n\r\n[](https://www.youtube.com/watch?v=ArcFHpX-usQ \"Nodejs Face Recognition using face-recognition.js and opencv4nodejs\")\r\n\r\n### Hand Gesture Recognition\r\n\r\nCheck out [Simple Hand Gesture Recognition using OpenCV and JavaScript](https://medium.com/@muehler.v/simple-hand-gesture-recognition-using-opencv-and-javascript-eb3d6ced28a0).\r\n\r\n\r\n\r\n### Object Recognition with Deep Neural Networks\r\n\r\nCheck out [Node.js meets OpenCV’s Deep Neural Networks — Fun with Tensorflow and Caffe](https://medium.com/@muehler.v/node-js-meets-opencvs-deep-neural-networks-fun-with-tensorflow-and-caffe-ff8d52a0f072).\r\n\r\n#### Tensorflow Inception\r\n\r\n\r\n\r\n\r\n\r\n#### Single Shot Multibox Detector with COCO\r\n\r\n\r\n\r\n\r\n### Machine Learning\r\n\r\nCheck out [Machine Learning with OpenCV and JavaScript: Recognizing Handwritten Letters using HOG and SVM](https://medium.com/@muehler.v/machine-learning-with-opencv-and-javascript-part-1-recognizing-handwritten-letters-using-hog-and-88719b70efaa).\r\n\r\n\r\n\r\n### Object Tracking\r\n\r\n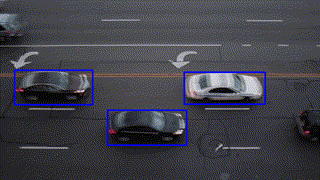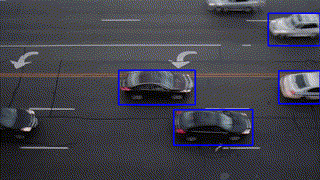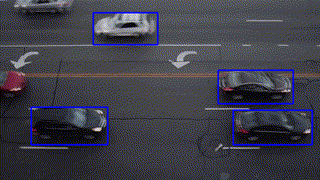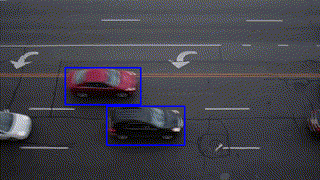\r\n\r\n\r\n### Feature Matching\r\n\r\n\r\n\r\n### Image Histogram\r\n\r\n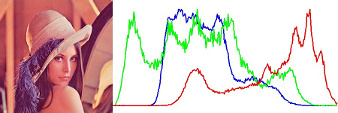\r\n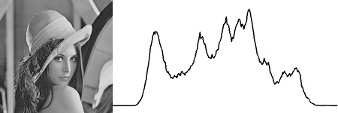\r\n\r\n### Boiler plate for combination of opencv4nodejs, express and websockets\r\n\r\n[opencv4nodejs-express-websockets](https://github.com/Mudassir-23/opencv4nodejs-express-websockets) - Boilerplate express app for getting started on opencv with nodejs and to live stream the video through websockets.\r\n\r\n### Automating lights by people detection through classifier\r\n\r\nCheck out [Automating lights with Computer Vision & NodeJS](https://medium.com/softway-blog/automating-lights-with-computer-vision-nodejs-fb9b614b75b2).\r\n\r\n\r\n\r\n<a name=\"how-to-install\"></a>\r\n\r\n## How to install\r\n\r\n``` bash\r\nnpm install --save @u4/opencv4nodejs\r\n```\r\n\r\nNative node modules are built via node-gyp, which already comes with npm by default. However, node-gyp requires you to have python installed. If you are running into node-gyp specific issues have a look at known issues with [node-gyp](https://github.com/nodejs/node-gyp) first.\r\n\r\n**Important note:** node-gyp won't handle whitespaces properly, thus make sure, that the path to your project directory does **not contain any whitespaces**. Installing opencv4nodejs under \"C:\\Program Files\\some_dir\" or similar will not work and will fail with: \"fatal error C1083: Cannot open include file: 'opencv2/core.hpp'\"!**\r\n\r\nOn Windows you will furthermore need Windows Build Tools to compile OpenCV and opencv4nodejs. If you don't have Visual Studio or Windows Build Tools installed, you can easily install the VS2015 build tools:\r\n\r\n``` bash\r\nnpm install --global windows-build-tools\r\n```\r\n\r\nOnce the @u4/opencv4nodejs is installed, prepare a compilation task in your `package.json`\r\n\r\n```json\r\n{\r\n \"scripts\": {\r\n \"install_arm64\": \"build-opencv --version 4.5.4 --flag=\\\"-DCMAKE_SYSTEM_PROCESSOR=arm64 -DCMAKE_OSX_ARCHITECTURES=arm64\\\" build\",\r\n \"install_4.5.5_cuda\": \"build-opencv --version 4.5.5 --flags=\\\"-DWITH_CUDA=ON -DWITH_CUDNN=ON -DOPENCV_DNN_CUDA=ON -DCUDA_FAST_MATH=ON\\\" build\",\r\n \"do-install\": \"build-opencv build\",\r\n }\r\n}\r\n```\r\n\r\nthen call it to build the mapping\r\n\r\n```bash\r\nnpm run install_4.5.5_cuda\r\n```\r\n\r\nAll build param can be append to the `build-opencv` build command line (see `build-opencv --help`) the opencv4nodejs part of package.json are still read but you yould not use it for new project.\r\n\r\n## Installing OpenCV Manually\r\n\r\nSetting up OpenCV on your own will require you to set an environment variable to prevent the auto build script to run:\r\n\r\n``` bash\r\n# linux and osx:\r\nexport OPENCV4NODEJS_DISABLE_AUTOBUILD=1\r\n# on windows:\r\nset OPENCV4NODEJS_DISABLE_AUTOBUILD=1\r\n```\r\n\r\n### Windows\r\n\r\nYou can install any of the OpenCV 3 or OpenCV 4 [releases](https://github.com/opencv/opencv/releases/) manually or via the [Chocolatey](https://chocolatey.org/) package manager:\r\n\r\n``` bash\r\n# to install OpenCV 4.1.0\r\nchoco install OpenCV -y -version 4.1.0\r\n```\r\n\r\nNote, this will come without contrib modules. To install OpenCV under windows with contrib modules you have to build the library from source or you can use the auto build script.\r\n\r\nBefore installing opencv4nodejs with an own installation of OpenCV you need to expose the following environment variables:\r\n\r\n- *OPENCV_INCLUDE_DIR* pointing to the directory with the subfolder *opencv2* containing the header files\r\n- *OPENCV_LIB_DIR* pointing to the lib directory containing the OpenCV .lib files\r\n\r\nAlso you will need to add the OpenCV binaries to your system path:\r\n\r\n- add an environment variable *OPENCV_BIN_DIR* pointing to the binary directory containing the OpenCV .dll files\r\n- append `;%OPENCV_BIN_DIR%;` to your system path variable\r\n\r\nNote: Restart your current console session after making changes to your environment.\r\n\r\n### MacOSX\r\n\r\nUnder OSX we can simply install OpenCV via brew:\r\n\r\n``` bash\r\nbrew update\r\nbrew install opencv@4\r\nbrew link --force opencv@4\r\n```\r\n\r\n### Linux\r\n\r\nUnder Linux we have to build OpenCV from source manually or using the auto build script.\r\n\r\n## Installing OpenCV via Auto Build Script\r\n\r\nThe auto build script comes in form of the [opencv-build](https://github.com/urielch/npm-opencv-build) npm package, which will run by default when installing opencv4nodejs. The script requires you to have git and a recent version of cmake installed.\r\n\r\n### Auto Build Flags\r\n\r\nYou can customize the autobuild flags using *OPENCV4NODEJS_AUTOBUILD_FLAGS=<flags>*.\r\nFlags must be space-separated.\r\n\r\nThis is an advanced customization and you should have knowledge regarding the OpenCV compilation flags. Flags added by default are listed [here](https://github.com/urielch/npm-opencv-build/blob/master/src/constants.ts#L44-L82).\r\n\r\n### Installing a Specific Version of OpenCV\r\n\r\nYou can specify the Version of OpenCV you want to install via the script by setting an environment variable:\r\n`export OPENCV4NODEJS_AUTOBUILD_OPENCV_VERSION=4.1.0`\r\n\r\n### Installing only a Subset of OpenCV modules\r\n\r\nIf you only want to build a subset of the OpenCV modules you can pass the *-DBUILD_LIST* cmake flag via the *OPENCV4NODEJS_AUTOBUILD_FLAGS* environment variable. For example `export OPENCV4NODEJS_AUTOBUILD_FLAGS=-DBUILD_LIST=dnn` will build only modules required for `dnn` and reduces the size and compilation time of the OpenCV package.\r\n\r\n## Configuring Environments via package.json (deprecated)\r\n\r\nIt's possible to specify build environment variables by inserting them into the `package.json` as follows:\r\n\r\n```json\r\n{\r\n \"name\": \"my-project\",\r\n \"version\": \"0.0.0\",\r\n \"dependencies\": {\r\n \"@u4/opencv4nodejs\": \"^X.X.X\"\r\n },\r\n \"opencv4nodejs\": {\r\n \"disableAutoBuild\": 1,\r\n \"opencvIncludeDir\": \"C:\\\\tools\\\\opencv\\\\build\\\\include\",\r\n \"opencvLibDir\": \"C:\\\\tools\\\\opencv\\\\build\\\\x64\\\\vc14\\\\lib\",\r\n \"opencvBinDir\": \"C:\\\\tools\\\\opencv\\\\build\\\\x64\\\\vc14\\\\bin\"\r\n }\r\n}\r\n```\r\n\r\nThe following environment variables can be passed:\r\n\r\n- autoBuildBuildCuda\r\n- autoBuildFlags\r\n- autoBuildOpencvVersion\r\n- autoBuildWithoutContrib\r\n- disableAutoBuild\r\n- opencvIncludeDir\r\n- opencvLibDir\r\n- opencvBinDir\r\n\r\n<a name=\"usage-with-docker\"></a>\r\n\r\n## Usage with Docker\r\n\r\n### [opencv-express](https://github.com/justadudewhohacks/opencv-express) - example for opencv4nodejs with express.js and docker\r\n\r\nOr simply pull from [justadudewhohacks/opencv-nodejs](https://hub.docker.com/r/justadudewhohacks/opencv-nodejs/) for opencv-3.2 + contrib-3.2 with opencv4nodejs globally installed:\r\n\r\n``` docker\r\nFROM justadudewhohacks/opencv-nodejs\r\n```\r\n\r\n**Note**: The aforementioned Docker image already has ```opencv4nodejs``` installed globally. In order to prevent build errors during an ```npm install```, your ```package.json``` should not include ```opencv4nodejs```, and instead should include/require the global package either by requiring it by absolute path or setting the ```NODE_PATH``` environment variable to ```/usr/lib/node_modules``` in your Dockerfile and requiring the package as you normally would.\r\n\r\nDifferent OpenCV 3.x base images can be found here: <https://hub.docker.com/r/justadudewhohacks/>.\r\n\r\n<a name=\"usage-with-electron\"></a>\r\n\r\n## Usage with Electron\r\n\r\n### [opencv-electron](https://github.com/urielch/opencv-electron) - example for opencv4nodejs with electron\r\n\r\nAdd the following script to your package.json:\r\n\r\n```python\r\n\"electron-rebuild\": \"build-opencv --electron --version 4.5.4 build\"\r\n```\r\n\r\nRun the script:\r\n\r\n```bash\r\nnpm run electron-rebuild\r\n```\r\n\r\nRequire it in the application:\r\n\r\n``` javascript\r\nconst cv = require('@u4/opencv4nodejs');\r\n```\r\n\r\n<a name=\"usage-with-nwjs\"></a>\r\n\r\n## Usage with NW.js\r\n\r\nAny native modules, including opencv4nodejs, must be recompiled to be used with [NW.js](https://nwjs.io/). Instructions on how to do this are available in the **[Use Native Modules](http://docs.nwjs.io/en/latest/For%20Users/Advanced/Use%20Native%20Node%20Modules/)** section of the the NW.js documentation.\r\n\r\nOnce recompiled, the module can be installed and required as usual:\r\n\r\n``` javascript\r\nconst cv = require('@u4/opencv4nodejs');\r\n```\r\n\r\n<a name=\"quick-start\"></a>\r\n\r\n## Quick Start\r\n\r\n``` javascript\r\nconst cv = require('@u4/opencv4nodejs');\r\n```\r\n\r\n### Initializing Mat (image matrix), Vec, Point\r\n\r\n``` javascript\r\nconst rows = 100; // height\r\nconst cols = 100; // width\r\n\r\n// empty Mat\r\nconst emptyMat = new cv.Mat(rows, cols, cv.CV_8UC3);\r\n\r\n// fill the Mat with default value\r\nconst whiteMat = new cv.Mat(rows, cols, cv.CV_8UC1, 255);\r\nconst blueMat = new cv.Mat(rows, cols, cv.CV_8UC3, [255, 0, 0]);\r\n\r\n// from array (3x3 Matrix, 3 channels)\r\nconst matData = [\r\n [[255, 0, 0], [255, 0, 0], [255, 0, 0]],\r\n [[0, 0, 0], [0, 0, 0], [0, 0, 0]],\r\n [[255, 0, 0], [255, 0, 0], [255, 0, 0]]\r\n];\r\nconst matFromArray = new cv.Mat(matData, cv.CV_8UC3);\r\n\r\n// from node buffer\r\nconst charData = [255, 0, ...];\r\nconst matFromArray = new cv.Mat(Buffer.from(charData), rows, cols, cv.CV_8UC3);\r\n\r\n// Point\r\nconst pt2 = new cv.Point(100, 100);\r\nconst pt3 = new cv.Point(100, 100, 0.5);\r\n\r\n// Vector\r\nconst vec2 = new cv.Vec(100, 100);\r\nconst vec3 = new cv.Vec(100, 100, 0.5);\r\nconst vec4 = new cv.Vec(100, 100, 0.5, 0.5);\r\n```\r\n\r\n### Mat and Vec operations\r\n\r\n``` javascript\r\nconst mat0 = new cv.Mat(...);\r\nconst mat1 = new cv.Mat(...);\r\n\r\n// arithmetic operations for Mats and Vecs\r\nconst matMultipliedByScalar = mat0.mul(0.5); // scalar multiplication\r\nconst matDividedByScalar = mat0.div(2); // scalar division\r\nconst mat0PlusMat1 = mat0.add(mat1); // addition\r\nconst mat0MinusMat1 = mat0.sub(mat1); // subtraction\r\nconst mat0MulMat1 = mat0.hMul(mat1); // elementwise multiplication\r\nconst mat0DivMat1 = mat0.hDiv(mat1); // elementwise division\r\n\r\n// logical operations Mat only\r\nconst mat0AndMat1 = mat0.and(mat1);\r\nconst mat0OrMat1 = mat0.or(mat1);\r\nconst mat0bwAndMat1 = mat0.bitwiseAnd(mat1);\r\nconst mat0bwOrMat1 = mat0.bitwiseOr(mat1);\r\nconst mat0bwXorMat1 = mat0.bitwiseXor(mat1);\r\nconst mat0bwNot = mat0.bitwiseNot();\r\n```\r\n\r\n### Accessing Mat data\r\n\r\n``` javascript\r\nconst matBGR = new cv.Mat(..., cv.CV_8UC3);\r\nconst matGray = new cv.Mat(..., cv.CV_8UC1);\r\n\r\n// get pixel value as vector or number value\r\nconst vec3 = matBGR.at(200, 100);\r\nconst grayVal = matGray.at(200, 100);\r\n\r\n// get raw pixel value as array\r\nconst [b, g, r] = matBGR.atRaw(200, 100);\r\n\r\n// set single pixel values\r\nmatBGR.set(50, 50, [255, 0, 0]);\r\nmatBGR.set(50, 50, new Vec(255, 0, 0));\r\nmatGray.set(50, 50, 255);\r\n\r\n// get a 25x25 sub region of the Mat at offset (50, 50)\r\nconst width = 25;\r\nconst height = 25;\r\nconst region = matBGR.getRegion(new cv.Rect(50, 50, width, height));\r\n\r\n// get a node buffer with raw Mat data\r\nconst matAsBuffer = matBGR.getData();\r\n\r\n// get entire Mat data as JS array\r\nconst matAsArray = matBGR.getDataAsArray();\r\n```\r\n\r\n### IO\r\n\r\n``` javascript\r\n// load image from file\r\nconst mat = cv.imread('./path/img.jpg');\r\ncv.imreadAsync('./path/img.jpg', (err, mat) => {\r\n ...\r\n})\r\n\r\n// save image\r\ncv.imwrite('./path/img.png', mat);\r\ncv.imwriteAsync('./path/img.jpg', mat,(err) => {\r\n ...\r\n})\r\n\r\n// show image\r\ncv.imshow('a window name', mat);\r\ncv.waitKey();\r\n\r\n// load base64 encoded image\r\nconst base64text='data:image/png;base64,R0lGO..';//Base64 encoded string\r\nconst base64data =base64text.replace('data:image/jpeg;base64','')\r\n .replace('data:image/png;base64','');//Strip image type prefix\r\nconst buffer = Buffer.from(base64data,'base64');\r\nconst image = cv.imdecode(buffer); //Image is now represented as Mat\r\n\r\n// convert Mat to base64 encoded jpg image\r\nconst outBase64 = cv.imencode('.jpg', croppedImage).toString('base64'); // Perform base64 encoding\r\nconst htmlImg='<img src=data:image/jpeg;base64,'+outBase64 + '>'; //Create insert into HTML compatible <img> tag\r\n\r\n// open capture from webcam\r\nconst devicePort = 0;\r\nconst wCap = new cv.VideoCapture(devicePort);\r\n\r\n// open video capture\r\nconst vCap = new cv.VideoCapture('./path/video.mp4');\r\n\r\n// read frames from capture\r\nconst frame = vCap.read();\r\nvCap.readAsync((err, frame) => {\r\n ...\r\n});\r\n\r\n// loop through the capture\r\nconst delay = 10;\r\nlet done = false;\r\nwhile (!done) {\r\n let frame = vCap.read();\r\n // loop back to start on end of stream reached\r\n if (frame.empty) {\r\n vCap.reset();\r\n frame = vCap.read();\r\n }\r\n\r\n // ...\r\n\r\n const key = cv.waitKey(delay);\r\n done = key !== 255;\r\n}\r\n```\r\n\r\n### Useful Mat methods\r\n\r\n``` javascript\r\nconst matBGR = new cv.Mat(..., cv.CV_8UC3);\r\n\r\n// convert types\r\nconst matSignedInt = matBGR.convertTo(cv.CV_32SC3);\r\nconst matDoublePrecision = matBGR.convertTo(cv.CV_64FC3);\r\n\r\n// convert color space\r\nconst matGray = matBGR.bgrToGray();\r\nconst matHSV = matBGR.cvtColor(cv.COLOR_BGR2HSV);\r\nconst matLab = matBGR.cvtColor(cv.COLOR_BGR2Lab);\r\n\r\n// resize\r\nconst matHalfSize = matBGR.rescale(0.5);\r\nconst mat100x100 = matBGR.resize(100, 100);\r\nconst matMaxDimIs100 = matBGR.resizeToMax(100);\r\n\r\n// extract channels and create Mat from channels\r\nconst [matB, matG, matR] = matBGR.splitChannels();\r\nconst matRGB = new cv.Mat([matR, matB, matG]);\r\n```\r\n\r\n### Drawing a Mat into HTML Canvas\r\n\r\n``` javascript\r\nconst img = ...\r\n\r\n// convert your image to rgba color space\r\nconst matRGBA = img.channels === 1\r\n ? img.cvtColor(cv.COLOR_GRAY2RGBA)\r\n : img.cvtColor(cv.COLOR_BGR2RGBA);\r\n\r\n// create new ImageData from raw mat data\r\nconst imgData = new ImageData(\r\n new Uint8ClampedArray(matRGBA.getData()),\r\n img.cols,\r\n img.rows\r\n);\r\n\r\n// set canvas dimensions\r\nconst canvas = document.getElementById('myCanvas');\r\ncanvas.height = img.rows;\r\ncanvas.width = img.cols;\r\n\r\n// set image data\r\nconst ctx = canvas.getContext('2d');\r\nctx.putImageData(imgData, 0, 0);\r\n```\r\n\r\n### Method Interface\r\n\r\nOpenCV method interface from official docs or src:\r\n\r\n``` c++\r\nvoid GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY = 0, int borderType = BORDER_DEFAULT);\r\n```\r\n\r\ntranslates to:\r\n\r\n``` javascript\r\nconst src = new cv.Mat(...);\r\n// invoke with required arguments\r\nconst dst0 = src.gaussianBlur(new cv.Size(5, 5), 1.2);\r\n// with optional paramaters\r\nconst dst2 = src.gaussianBlur(new cv.Size(5, 5), 1.2, 0.8, cv.BORDER_REFLECT);\r\n// or pass specific optional parameters\r\nconst optionalArgs = {\r\n borderType: cv.BORDER_CONSTANT\r\n};\r\nconst dst2 = src.gaussianBlur(new cv.Size(5, 5), 1.2, optionalArgs);\r\n```\r\n\r\n<a name=\"async-api\"></a>\r\n\r\n## Async API\r\n\r\nThe async API can be consumed by passing a callback as the last argument of the function call. By default, if an async method is called without passing a callback, the function call will yield a Promise.\r\n\r\n### Async Face Detection\r\n\r\n``` javascript\r\nconst classifier = new cv.CascadeClassifier(cv.HAAR_FRONTALFACE_ALT2);\r\n\r\n// by nesting callbacks\r\ncv.imreadAsync('./faceimg.jpg', (err, img) => {\r\n if (err) { return console.error(err); }\r\n\r\n const grayImg = img.bgrToGray();\r\n classifier.detectMultiScaleAsync(grayImg, (err, res) => {\r\n if (err) { return console.error(err); }\r\n\r\n const { objects, numDetections } = res;\r\n ...\r\n });\r\n});\r\n\r\n// via Promise\r\ncv.imreadAsync('./faceimg.jpg')\r\n .then(img =>\r\n img.bgrToGrayAsync()\r\n .then(grayImg => classifier.detectMultiScaleAsync(grayImg))\r\n .then((res) => {\r\n const { objects, numDetections } = res;\r\n ...\r\n })\r\n )\r\n .catch(err => console.error(err));\r\n\r\n// using async await\r\ntry {\r\n const img = await cv.imreadAsync('./faceimg.jpg');\r\n const grayImg = await img.bgrToGrayAsync();\r\n const { objects, numDetections } = await classifier.detectMultiScaleAsync(grayImg);\r\n ...\r\n} catch (err) {\r\n console.error(err);\r\n}\r\n```\r\n\r\n<a name=\"with-typescript\"></a>\r\n\r\n## With TypeScript\r\n\r\n``` javascript\r\nimport * as cv from '@u4/opencv4nodejs'\r\n```\r\n\r\nCheck out the TypeScript [examples](https://github.com/urielch/opencv4nodejs/tree/master/examples).\r\n\r\n<a name=\"external-mem-tracking\"></a>\r\n\r\n## External Memory Tracking (v4.0.0)\r\n\r\nSince version 4.0.0 was released, external memory tracking has been enabled by default. Simply put, the memory allocated for Matrices (cv.Mat) will be manually reported to the node process. This solves the issue of inconsistent Garbage Collection, which could have resulted in spiking memory usage of the node process eventually leading to overflowing the RAM of your system, prior to version 4.0.0.\r\n\r\nNote, that in doubt this feature can be **disabled** by setting an environment variable `OPENCV4NODEJS_DISABLE_EXTERNAL_MEM_TRACKING` before requiring the module:\r\n\r\n``` bash\r\nexport OPENCV4NODEJS_DISABLE_EXTERNAL_MEM_TRACKING=1 // linux\r\nset OPENCV4NODEJS_DISABLE_EXTERNAL_MEM_TRACKING=1 // windows\r\n```\r\n\r\nOr directly in your code:\r\n\r\n``` javascript\r\nprocess.env.OPENCV4NODEJS_DISABLE_EXTERNAL_MEM_TRACKING = 1\r\nconst cv = require('@u4/opencv4nodejs')\r\n```\r\n" | ||
| } |
@@ -16,2 +16,3 @@ export const xmodules: { | ||
| machinelearning: boolean; | ||
| video: boolean; | ||
| } | ||
@@ -25,2 +26,2 @@ | ||
| export const modules: typeof cv.xmodules; | ||
| export const modules: typeof xmodules; |
@@ -66,6 +66,16 @@ export const CV_8U: number; | ||
| export const CONTOURS_MATCH_I1: number; | ||
| export const CONTOURS_MATCH_I2: number; | ||
| export const CONTOURS_MATCH_I3: number; | ||
| export const DNN_BACKEND_OPENCV: number; | ||
| export const DNN_BACKEND_INFERENCE_ENGINE: number; | ||
| export const DNN_BACKEND_HALIDE: number; | ||
| export const DNN_BACKEND_CUDA: number; | ||
| export const DNN_TARGET_CPU: number; | ||
| export const DNN_TARGET_OPENCL: number; | ||
| export const DNN_TARGET_OPENCL_FP16: number; | ||
| export const DNN_TARGET_MYRIAD: number; | ||
| export const DNN_TARGET_FPGA: number; | ||
| export const DNN_TARGET_CUDA: number; | ||
| export const DNN_TARGET_CUDA_FP16: number; | ||
| export const DNN_TARGET_HDDL: number; | ||
| export const ADAPTIVE_THRESH_GAUSSIAN_C: number; | ||
@@ -110,16 +120,52 @@ export const ADAPTIVE_THRESH_MEAN_C: number; | ||
| export const CALIB_ZERO_TANGENT_DIST: number; | ||
| /** | ||
| * Android - not used. | ||
| */ | ||
| export const CAP_ANDROID: number; | ||
| /** | ||
| * Auto detect == 0. | ||
| */ | ||
| export const CAP_ANY: number; | ||
| /** | ||
| * Aravis SDK. | ||
| */ | ||
| export const CAP_ARAVIS: number; | ||
| /** | ||
| * AVFoundation framework for iOS (OS X Lion will have the same API) | ||
| */ | ||
| export const CAP_AVFOUNDATION: number; | ||
| export const CAP_CMU1394: number; | ||
| export const CAP_DC1394: number; | ||
| /** | ||
| * DirectShow (via videoInput) | ||
| */ | ||
| export const CAP_DSHOW: number; | ||
| /** | ||
| * Open and record video file or stream using the FFMPEG library. | ||
| */ | ||
| export const CAP_FFMPEG: number; | ||
| /** | ||
| * IEEE 1394 drivers. | ||
| */ | ||
| export const CAP_FIREWIRE: number; | ||
| /** | ||
| * Smartek Giganetix GigEVisionSDK. | ||
| */ | ||
| export const CAP_GIGANETIX: number; | ||
| /** | ||
| * gPhoto2 connection | ||
| */ | ||
| export const CAP_GPHOTO2: number; | ||
| /** | ||
| * GStreamer. | ||
| */ | ||
| export const CAP_GSTREAMER: number; | ||
| export const CAP_IEEE1394: number; | ||
| /** | ||
| * OpenCV Image Sequence (e.g. img_%02d.jpg) | ||
| */ | ||
| export const CAP_IMAGES: number; | ||
| /** | ||
| * RealSense (former Intel Perceptual Computing SDK) | ||
| */ | ||
| export const CAP_INTELPERC: number; | ||
@@ -130,38 +176,120 @@ export const CAP_MODE_BGR: number; | ||
| export const CAP_MODE_YUYV: number; | ||
| /** | ||
| * Microsoft Media Foundation (via videoInput) | ||
| */ | ||
| export const CAP_MSMF: number; | ||
| /** | ||
| * OpenNI (for Kinect) | ||
| */ | ||
| export const CAP_OPENNI: number; | ||
| /** | ||
| * OpenNI2 (for Kinect) | ||
| */ | ||
| export const CAP_OPENNI2: number; | ||
| /** | ||
| * OpenNI2 (for Asus Xtion and Occipital Structure sensors) | ||
| */ | ||
| export const CAP_OPENNI2_ASUS: number; | ||
| /** | ||
| * OpenNI (for Asus Xtion) | ||
| */ | ||
| export const CAP_OPENNI_ASUS: number; | ||
| export const CAP_PROP_AUTOFOCUS: number; | ||
| /** | ||
| * DC1394: exposure control done by camera, user can adjust reference level using this feature. | ||
| */ | ||
| export const CAP_PROP_AUTO_EXPOSURE: number; | ||
| export const CAP_PROP_BACKLIGHT: number; | ||
| /** | ||
| * Brightness of the image (only for those cameras that support). | ||
| */ | ||
| export const CAP_PROP_BRIGHTNESS: number; | ||
| export const CAP_PROP_BUFFERSIZE: number; | ||
| /** | ||
| * Contrast of the image (only for cameras). | ||
| */ | ||
| export const CAP_PROP_CONTRAST: number; | ||
| /** | ||
| * Boolean flags indicating whether images should be converted to RGB. | ||
| * GStreamer note: The flag is ignored in case if custom pipeline is used. It's user responsibility to interpret pipeline output. | ||
| */ | ||
| export const CAP_PROP_CONVERT_RGB: number; | ||
| /** | ||
| * Exposure (only for those cameras that support). | ||
| */ | ||
| export const CAP_PROP_EXPOSURE: number; | ||
| export const CAP_PROP_FOCUS: number; | ||
| /** | ||
| * Format of the Mat objects (see Mat::type()) returned by VideoCapture::retrieve(). Set value -1 to fetch undecoded RAW video streams (as Mat 8UC1). | ||
| */ | ||
| export const CAP_PROP_FORMAT: number; | ||
| /** | ||
| * 4-character code of codec. see VideoWriter::fourcc . | ||
| */ | ||
| export const CAP_PROP_FOURCC: number; | ||
| /** | ||
| * Frame rate. | ||
| */ | ||
| export const CAP_PROP_FPS: number; | ||
| /** | ||
| * Number of frames in the video file. | ||
| */ | ||
| export const CAP_PROP_FRAME_COUNT: number; | ||
| /** | ||
| * Height of the frames in the video stream. | ||
| */ | ||
| export const CAP_PROP_FRAME_HEIGHT: number; | ||
| /** | ||
| * Width of the frames in the video stream. | ||
| */ | ||
| export const CAP_PROP_FRAME_WIDTH: number; | ||
| /** | ||
| * Gain of the image (only for those cameras that support). | ||
| */ | ||
| export const CAP_PROP_GAIN: number; | ||
| export const CAP_PROP_GAMMA: number; | ||
| export const CAP_PROP_GUID: number; | ||
| /** | ||
| * Hue of the image (only for cameras). | ||
| */ | ||
| export const CAP_PROP_HUE: number; | ||
| export const CAP_PROP_IRIS: number; | ||
| export const CAP_PROP_ISO_SPEED: number; | ||
| /** | ||
| * Backend-specific value indicating the current capture mode. | ||
| */ | ||
| export const CAP_PROP_MODE: number; | ||
| /** | ||
| * | ||
| */ | ||
| export const CAP_PROP_MONOCHROME: number; | ||
| export const CAP_PROP_PAN: number; | ||
| /** | ||
| * Relative position of the video file: 0=start of the film, 1=end of the film. | ||
| */ | ||
| export const CAP_PROP_POS_AVI_RATIO: number; | ||
| /** | ||
| * 0-based index of the frame to be decoded/captured next. | ||
| */ | ||
| export const CAP_PROP_POS_FRAMES: number; | ||
| /** | ||
| * Current position of the video file in milliseconds. | ||
| */ | ||
| export const CAP_PROP_POS_MSEC: number; | ||
| /** | ||
| * Rectification flag for stereo cameras (note: only supported by DC1394 v 2.x backend currently). | ||
| */ | ||
| export const CAP_PROP_RECTIFICATION: number; | ||
| export const CAP_PROP_ROLL: number; | ||
| /** | ||
| * Saturation of the image (only for cameras). | ||
| */ | ||
| export const CAP_PROP_SATURATION: number; | ||
| /** | ||
| * Pop up video/camera filter dialog (note: only supported by DSHOW backend currently. The property value is ignored) | ||
| */ | ||
| export const CAP_PROP_SETTINGS: number; | ||
| /** | ||
| * | ||
| */ | ||
| export const CAP_PROP_SHARPNESS: number; | ||
@@ -172,12 +300,39 @@ export const CAP_PROP_TEMPERATURE: number; | ||
| export const CAP_PROP_TRIGGER_DELAY: number; | ||
| /** | ||
| * Currently unsupported. | ||
| */ | ||
| export const CAP_PROP_WHITE_BALANCE_BLUE_U: number; | ||
| export const CAP_PROP_WHITE_BALANCE_RED_V: number; | ||
| export const CAP_PROP_ZOOM: number; | ||
| /** | ||
| * PvAPI, Prosilica GigE SDK. | ||
| */ | ||
| export const CAP_PVAPI: number; | ||
| /** | ||
| * QuickTime (obsolete, removed) | ||
| */ | ||
| export const CAP_QT: number; | ||
| /** | ||
| * Unicap drivers (obsolete, removed) | ||
| */ | ||
| export const CAP_UNICAP: number; | ||
| /** | ||
| * V4L/V4L2 capturing support. | ||
| */ | ||
| export const CAP_V4L: number; | ||
| /** | ||
| * Same as CAP_V4L. | ||
| */ | ||
| export const CAP_V4L2: number; | ||
| /** | ||
| * Video For Windows (obsolete, removed) | ||
| */ | ||
| export const CAP_VFW: number; | ||
| /** | ||
| * Microsoft Windows Runtime using Media Foundation. | ||
| */ | ||
| export const CAP_WINRT: number; | ||
| /** | ||
| * XIMEA Camera API. | ||
| */ | ||
| export const CAP_XIAPI: number; | ||
@@ -184,0 +339,0 @@ export const CC_STAT_AREA: number; |
@@ -27,2 +27,3 @@ import { Mat } from './Mat.d'; | ||
| export * from './group/core_cluster'; | ||
| export * from './group/core_utils'; | ||
| export * from './group/imgproc_motion'; | ||
@@ -35,2 +36,3 @@ export * from './group/dnn'; | ||
| export * from './group/imgproc_motion'; | ||
| // export * from './group/imgproc_draw'; | ||
@@ -147,2 +149,6 @@ /** @deprecated */ | ||
| export function isCustomMatAllocatorEnabled(): boolean; | ||
| export function dangerousEnableCustomMatAllocator(): boolean; | ||
| export function dangerousDisableCustomMatAllocator(): boolean; | ||
| export function getMemMetrics(): { TotalAlloc: number, TotalKnownByJS: number, NumAllocations: number, NumDeAllocations: number }; | ||
@@ -168,8 +174,8 @@ export type DrawParams = { | ||
| // non Natif | ||
| export function drawDetection(img: Mat, inputRect: Rect, opts?: DrawDetectionParams): Rect; | ||
| // non Natif | ||
| export function drawTextBox(img: Mat, upperLeft: { x: number, y: number }, textLines: TextLine[], alpha: number): Mat; | ||
| export function isCustomMatAllocatorEnabled(): boolean; | ||
| export function dangerousEnableCustomMatAllocator(): boolean; | ||
| export function dangerousDisableCustomMatAllocator(): boolean; | ||
| export function getMemMetrics(): { TotalAlloc: number, TotalKnownByJS: number, NumAllocations: number, NumDeAllocations: number }; |
@@ -7,25 +7,49 @@ import { Mat } from '../Mat.d'; | ||
| //Mat cv::dnn::blobFromImage (InputArray image, double scalefactor=1.0, const Size &size=Size(), const Scalar &mean=Scalar(), bool swapRB=false, bool crop=false, int ddepth=CV_32F) | ||
| //Creates 4-dimensional blob from image. Optionally resizes and crops image from center, subtract mean values, scales values by scalefactor, swap Blue and Red channels. More... | ||
| // | ||
| //void cv::dnn::blobFromImage (InputArray image, OutputArray blob, double scalefactor=1.0, const Size &size=Size(), const Scalar &mean=Scalar(), bool swapRB=false, bool crop=false, int ddepth=CV_32F) | ||
| //Creates 4-dimensional blob from image. More... | ||
| /** | ||
| * Creates 4-dimensional blob from image. Optionally resizes and crops image from center, subtract mean values, scales values by scalefactor, swap Blue and Red channels. | ||
| * | ||
| * if crop is true, input image is resized so one side after resize is equal to corresponding dimension in size and another one is equal or larger. Then, crop from the center is performed. If crop is false, direct resize without cropping and preserving aspect ratio is performed. | ||
| * | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#ga29f34df9376379a603acd8df581ac8d7 | ||
| * | ||
| * @pram image input image (with 1-, 3- or 4-channels). | ||
| * @pram scalefactor multiplier for image values. | ||
| * @pram size spatial size for output image | ||
| * @pram mean scalar with mean values which are subtracted from channels. Values are intended to be in (mean-R, mean-G, mean-B) order if image has BGR ordering and swapRB is true. | ||
| * @pram swapRB flag which indicates that swap first and last channels in 3-channel image is necessary. | ||
| * @pram crop flag which indicates whether image will be cropped after resize or not | ||
| * @pram ddepth Depth of output blob. Choose CV_32F or CV_8U. | ||
| * | ||
| * | ||
| * @return 4-dimensional Mat with NCHW dimensions order. | ||
| */ | ||
| export function blobFromImage(image: Mat, scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number): Mat; | ||
| export function blobFromImage(image: Mat, opts: { scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number }): Mat; | ||
| export function blobFromImageAsync(image: Mat, scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number): Promise<Mat>; | ||
| export function blobFromImageAsync(image: Mat, opts: { scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number }): Promise<Mat>; | ||
| /** | ||
| * Creates 4-dimensional blob from series of images. Optionally resizes and crops images from center, subtract mean values, scales values by scalefactor, swap Blue and Red channels. | ||
| * | ||
| * if crop is true, input image is resized so one side after resize is equal to corresponding dimension in size and another one is equal or larger. Then, crop from the center is performed. If crop is false, direct resize without cropping and preserving aspect ratio is performed. | ||
| * | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#ga0b7b7c3c530b747ef738178835e1e70f | ||
| * | ||
| * @param images input images (all with 1-, 3- or 4-channels). | ||
| * @param scalefactor multiplier for images values. | ||
| * @param size spatial size for output image | ||
| * @param mean scalar with mean values which are subtracted from channels. Values are intended to be in (mean-R, mean-G, mean-B) order if image has BGR ordering and swapRB is true. | ||
| * @param swapRB flag which indicates that swap first and last channels in 3-channel image is necessary. | ||
| * @param crop flag which indicates whether image will be cropped after resize or not | ||
| * @param ddepth Depth of output blob. Choose CV_32F or CV_8U. | ||
| * | ||
| * @returns 4-dimensional Mat with NCHW dimensions order. | ||
| */ | ||
| export function blobFromImages(images: Mat[], scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number): Mat; | ||
| export function blobFromImages(images: Mat[], opts: { scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number }): Mat; | ||
| export function blobFromImagesAsync(images: Mat[], scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number): Promise<Mat>; | ||
| export function blobFromImagesAsync(images: Mat[], opts: { scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number }): Promise<Mat>; | ||
| //Mat cv::dnn::blobFromImages (InputArrayOfArrays images, double scalefactor=1.0, Size size=Size(), const Scalar &mean=Scalar(), bool swapRB=false, bool crop=false, int ddepth=CV_32F) | ||
| //Creates 4-dimensional blob from series of images. Optionally resizes and crops images from center, subtract mean values, scales values by scalefactor, swap Blue and Red channels. More... | ||
| // | ||
| //void cv::dnn::blobFromImages (InputArrayOfArrays images, OutputArray blob, double scalefactor=1.0, Size size=Size(), const Scalar &mean=Scalar(), bool swapRB=false, bool crop=false, int ddepth=CV_32F) | ||
| //Creates 4-dimensional blob from series of images. More... | ||
| export function blobFromImages(image: Mat[], scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number): Mat; | ||
| export function blobFromImagesAsync(image: Mat[], scaleFactor?: number, size?: Size, mean?: Vec3, swapRB?: boolean, crop?: boolean, ddepth?: number): Promise<Mat>; | ||
| //void cv::dnn::enableModelDiagnostics (bool isDiagnosticsMode) | ||
@@ -52,33 +76,62 @@ //Enables detailed logging of the DNN model loading with CV DNN API. More... | ||
| //void cv::dnn::NMSBoxes (const std::vector< RotatedRect > &bboxes, const std::vector< float > &scores, const float score_threshold, const float nms_threshold, std::vector< int > &indices, const float eta=1.f, const int top_k=0) | ||
| export function NMSBoxes(bboxes: Rect[], scores: number[], scoreThreshold: number, nmsThreshold: number): number[]; | ||
| /** | ||
| * Performs non maximum suppression given boxes and corresponding scores. | ||
| * | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#ga9d118d70a1659af729d01b10233213ee | ||
| * | ||
| * | ||
| * @param bboxes a set of bounding boxes to apply NMS. | ||
| * @param scores a set of corresponding confidences. | ||
| * @param scoreThreshold a threshold used to filter boxes by score. | ||
| * @param nmsThreshold a threshold used in non maximum suppression. | ||
| * @param eta a coefficient in adaptive threshold formula: nms_thresholdi+1=eta⋅nms_thresholdi. | ||
| * @param top_k if >0, keep at most top_k picked indices. | ||
| * | ||
| * @return the kept indices of bboxes after NMS. | ||
| */ | ||
| export function NMSBoxes(bboxes: Rect[], scores: number[], scoreThreshold: number, nmsThreshold: number, eta?: number, topK?: number): number[]; | ||
| export function NMSBoxes(bboxes: Rect[], scores: number[], scoreThreshold: number, nmsThreshold: number, opts: { eta?: number, topK?: number }): number[]; | ||
| /** | ||
| * Read deep learning network represented in one of the supported formats. | ||
| * | ||
| * https://docs.opencv.org/3.4.17/d6/d0f/group__dnn.html#ga3b34fe7a29494a6a4295c169a7d32422 | ||
| * | ||
| * @param model Binary file contains trained weights. The following file extensions are expected for models from different frameworks: | ||
| * *.caffemodel (Caffe, http://caffe.berkeleyvision.org/), | ||
| * *.pb (TensorFlow, https://www.tensorflow.org/), | ||
| * *.t7 | *.net (Torch, http://torch.ch/), | ||
| * *.weights (Darknet, https://pjreddie.com/darknet/), | ||
| * *.bin (DLDT, https://software.intel.com/openvino-toolkit), | ||
| * *.onnx (ONNX, https://onnx.ai/) | ||
| * @param modelPath Text file contains network configuration. It could be a file with the following extensions: | ||
| * *.prototxt (Caffe, http://caffe.berkeleyvision.org/), | ||
| * *.pbtxt (TensorFlow, https://www.tensorflow.org/), | ||
| * *.cfg (Darknet, https://pjreddie.com/darknet/), | ||
| * *.xml (DLDT, https://software.intel.com/openvino-toolkit) | ||
| */ | ||
| export function readNet(model: string, config?: string, framework?: string): Net; | ||
| export function readNet(model: string, opts: { config?: string, framework?: string }): Net; | ||
| export function readNetAsync(model: string, config?: string, framework?: string): Promise<Net>; | ||
| export function readNetAsync(model: string, opts: { config?: string, framework?: string }): Promise<Net>; | ||
| //Net cv::dnn::readNet (const String &model, const String &config="", const String &framework="") | ||
| //Read deep learning network represented in one of the supported formats. More... | ||
| // | ||
| //Net cv::dnn::readNet (const String &framework, const std::vector< uchar > &bufferModel, const std::vector< uchar > &bufferConfig=std::vector< uchar >()) | ||
| //Read deep learning network represented in one of the supported formats. More... | ||
| // | ||
| //Net cv::dnn::readNetFromCaffe (const String &prototxt, const String &caffeModel=String()) | ||
| //Reads a network model stored in Caffe framework's format. More... | ||
| /** | ||
| * Reads a network model stored in Caffe framework's format. | ||
| * | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#ga29d0ea5e52b1d1a6c2681e3f7d68473a | ||
| * @param prototxt path to the .prototxt file with text description of the network architecture. | ||
| * @param modelPath path to the .caffemodel file with learned network. | ||
| */ | ||
| export function readNetFromCaffe(prototxt: string, modelPath?: string): Net; | ||
| export function readNetFromCaffeAsync(prototxt: string, modelPath?: string): Promise<Net>; | ||
| //Net cv::dnn::readNetFromCaffe (const std::vector< uchar > &bufferProto, const std::vector< uchar > &bufferModel=std::vector< uchar >()) | ||
| //Reads a network model stored in Caffe model in memory. More... | ||
| // | ||
| //Net cv::dnn::readNetFromCaffe (const char *bufferProto, size_t lenProto, const char *bufferModel=NULL, size_t lenModel=0) | ||
| //Reads a network model stored in Caffe model in memory. More... | ||
| // | ||
| //Net cv::dnn::readNetFromDarknet (const String &cfgFile, const String &darknetModel=String()) | ||
| //Reads a network model stored in Darknet model files. More... | ||
| // | ||
| //Net cv::dnn::readNetFromDarknet (const std::vector< uchar > &bufferCfg, const std::vector< uchar > &bufferModel=std::vector< uchar >()) | ||
| //Reads a network model stored in Darknet model files. More... | ||
| // | ||
| //Net cv::dnn::readNetFromDarknet (const char *bufferCfg, size_t lenCfg, const char *bufferModel=NULL, size_t lenModel=0) | ||
| //Reads a network model stored in Darknet model files. More... | ||
| /** | ||
| * Reads a network model stored in Darknet model files. | ||
| * | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#gafde362956af949cce087f3f25c6aff0d | ||
| * | ||
| * @param cfgPath path to the .cfg file with text description of the network architecture. (should be an absolute path) | ||
| * @param modelPath to the .weights file with learned network. (should be an absolute path) | ||
| */ | ||
| export function readNetFromDarknet(cfgPath: string, modelPath: string): Net; | ||
@@ -97,25 +150,19 @@ export function readNetFromDarknetAsync(cfgPath: string, modelPath: string): Promise<Net>; | ||
| //Net cv::dnn::readNetFromONNX (const String &onnxFile) | ||
| //Reads a network model ONNX. More... | ||
| // | ||
| //Net cv::dnn::readNetFromONNX (const char *buffer, size_t sizeBuffer) | ||
| //Reads a network model from ONNX in-memory buffer. More... | ||
| // | ||
| //Net cv::dnn::readNetFromONNX (const std::vector< uchar > &buffer) | ||
| //Reads a network model from ONNX in-memory buffer. More... | ||
| /** | ||
| * Reads a network model ONNX. | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#ga7faea56041d10c71dbbd6746ca854197 | ||
| * | ||
| * @param onnxFile path to the .onnx file with text description of the network architecture. | ||
| */ | ||
| export function readNetFromONNX(onnxFile: string): Net; | ||
| export function readNetFromONNXAsync(onnxFile: string): Promise<Net>; | ||
| //Net cv::dnn::readNetFromTensorflow (const String &model, const String &config=String()) | ||
| //Reads a network model stored in TensorFlow framework's format. More... | ||
| // | ||
| //Net cv::dnn::readNetFromTensorflow (const std::vector< uchar > &bufferModel, const std::vector< uchar > &bufferConfig=std::vector< uchar >()) | ||
| //Reads a network model stored in TensorFlow framework's format. More... | ||
| // | ||
| //Net cv::dnn::readNetFromTensorflow (const char *bufferModel, size_t lenModel, const char *bufferConfig=NULL, size_t lenConfig=0) | ||
| //Reads a network model stored in TensorFlow framework's format. More... | ||
| /** | ||
| * Reads a network model stored in TensorFlow framework's format. | ||
| * | ||
| * https://docs.opencv.org/4.x/d6/d0f/group__dnn.html#gad820b280978d06773234ba6841e77e8d | ||
| * | ||
| * @param modelPath path to the .pb file with binary protobuf description of the network architecture | ||
| * @param config path to the .pbtxt file that contains text graph definition in protobuf format. Resulting Net object is built by text graph using weights from a binary one that let us make it more flexible. | ||
| */ | ||
| export function readNetFromTensorflow(modelPath: string, config?: string): Net; | ||
@@ -122,0 +169,0 @@ export function readNetFromTensorflowAsync(modelPath: string): Promise<Net>; |
@@ -48,5 +48,16 @@ import { Mat } from '../Mat'; | ||
| // | ||
| // void cv::namedWindow (const String &winname, int flags=WINDOW_AUTOSIZE) | ||
| // Creates a window. More... | ||
| // | ||
| /** | ||
| * Creates a window. | ||
| * | ||
| * The function namedWindow creates a window that can be used as a placeholder for images and trackbars. Created windows are referred to by their names. | ||
| * If a window with the same name already exists, the function does nothing. | ||
| * | ||
| * https://docs.opencv.org/4.x/d7/dfc/group__highgui.html#ga5afdf8410934fd099df85c75b2e0888b | ||
| * | ||
| * @param winname Name of the window in the window caption that may be used as a window identifier. default: cv.WINDOW_AUTOSIZE | ||
| * @param flags Flags of the window. The supported flags are: (cv::WindowFlags) | ||
| */ | ||
| export function namedWindow(winname: string, flags?: number) | ||
| // int cv::pollKey () | ||
@@ -53,0 +64,0 @@ // Polls for a pressed key. More... |
@@ -13,5 +13,14 @@ import { Size } from './Size.d'; | ||
| export class Mat { | ||
| /** | ||
| * Mat height like python .shape[0] | ||
| */ | ||
| readonly rows: number; | ||
| /** | ||
| * Mat width like python .shape[1] | ||
| */ | ||
| readonly cols: number; | ||
| readonly type: number; | ||
| /** | ||
| * Mat channels like python .shape[2] | ||
| */ | ||
| readonly channels: number; | ||
@@ -26,5 +35,17 @@ readonly depth: number; | ||
| constructor(channels: Mat[]); | ||
| /** | ||
| * @param type CV_8U, CV_8S, CV_16U, CV_16S, CV_32S, CV_32F, CV_64F ... | ||
| */ | ||
| constructor(rows: number, cols: number, type: number, fillValue?: number | number[]); | ||
| /** | ||
| * @param type CV_8U, CV_8S, CV_16U, CV_16S, CV_32S, CV_32F, CV_64F ... | ||
| */ | ||
| constructor(dataArray: number[][], type: number); | ||
| /** | ||
| * @param type CV_8U, CV_8S, CV_16U, CV_16S, CV_32S, CV_32F, CV_64F ... | ||
| */ | ||
| constructor(dataArray: number[][][], type: number); | ||
| /** | ||
| * @param type CV_8U, CV_8S, CV_16U, CV_16S, CV_32S, CV_32F, CV_64F ... | ||
| */ | ||
| constructor(data: Buffer, rows: number, cols: number, type?: number); | ||
@@ -118,2 +139,11 @@ abs(): Mat; | ||
| dilateAsync(kernel: Mat, anchor?: Point2, iterations?: number, borderType?: number): Promise<Mat>; | ||
| /** | ||
| * Calculates the distance to the closest zero pixel for each pixel of the source image. | ||
| * | ||
| * https://docs.opencv.org/4.x/d7/d1b/group__imgproc__misc.html#ga8a0b7fdfcb7a13dde018988ba3a43042 | ||
| * | ||
| * @param distanceType Type of distance, see DistanceTypes | ||
| * @param maskSize Size of the distance transform mask, see DistanceTransformMasks. DIST_MASK_PRECISE is not supported by this variant. In case of the DIST_L1 or DIST_C distance type, the parameter is forced to 3 because a 3×3 mask gives the same result as 5×5 or any larger aperture. | ||
| * @param dstType Type of output image. It can be CV_8U or CV_32F. Type CV_8U can be used only for the first variant of the function and distanceType == DIST_L1. | ||
| */ | ||
| distanceTransform(distanceType: number, maskSize: number, dstType?: number): Mat; | ||
@@ -142,3 +172,3 @@ distanceTransformAsync(distanceType: number, maskSize: number, dstType?: number): Promise<Mat>; | ||
| drawEllipse(center: Point2, axes: Size, angle: number, startAngle: number, endAngle: number, color?: Vec3, thickness?: number, lineType?: number, shift?: number): void; | ||
| drawFillConvexPoly(pts: Point2[], color?: Vec3, lineType?: number, shift?: number): void; | ||
@@ -179,6 +209,22 @@ drawFillPoly(pts: Point2[][], color?: Vec3, lineType?: number, shift?: number, offset?: Point2): void; | ||
| flipAsync(flipCode: number): Promise<Mat>; | ||
| floodFill(seedPoint: Point2, newVal: number, mask?: Mat, loDiff?: number, upDiff?: number, flags?: number): { returnValue: number, rect: Rect }; | ||
| floodFill(seedPoint: Point2, newVal: Vec3, mask?: Mat, loDiff?: Vec3, upDiff?: Vec3, flags?: number): { returnValue: number, rect: Rect }; | ||
| floodFillAsync(seedPoint: Point2, newVal: number, mask?: Mat, loDiff?: number, upDiff?: number, flags?: number): Promise<{ returnValue: number, rect: Rect }>; | ||
| floodFillAsync(seedPoint: Point2, newVal: Vec3, mask?: Mat, loDiff?: Vec3, upDiff?: Vec3, flags?: number): Promise<{ returnValue: number, rect: Rect }>; | ||
| /** | ||
| * Fills a connected component with the given color. | ||
| * | ||
| * The function cv::floodFill fills a connected component starting from the seed point with the specified color. The connectivity is determined by the color/brightness closeness of the neighbor pixels. The pixel at (x,y) is considered to belong to the repainted domain if: | ||
| * | ||
| * https://docs.opencv.org/4.x/d7/d1b/group__imgproc__misc.html#ga366aae45a6c1289b341d140839f18717 | ||
| * | ||
| * @param seedPoint Starting point. | ||
| * @param newVal New value of the repainted domain pixels. | ||
| * @param mask Operation mask that should be a single-channel 8-bit image, 2 pixels wider and 2 pixels taller than image. Since this is both an input and output parameter, you must take responsibility of initializing it. Flood-filling cannot go across non-zero pixels in the input mask. For example, an edge detector output can be used as a mask to stop filling at edges. On output, pixels in the mask corresponding to filled pixels in the image are set to 1 or to the a value specified in flags as described below. Additionally, the function fills the border of the mask with ones to simplify internal processing. It is therefore possible to use the same mask in multiple calls to the function to make sure the filled areas do not overlap. | ||
| * @param loDiff Maximal lower brightness/color difference between the currently observed pixel and one of its neighbors belonging to the component, or a seed pixel being added to the component. | ||
| * @param upDiff Maximal upper brightness/color difference between the currently observed pixel and one of its neighbors belonging to the component, or a seed pixel being added to the component. | ||
| * @param flags Operation flags. The first 8 bits contain a connectivity value. The default value of 4 means that only the four nearest neighbor pixels (those that share an edge) are considered. A connectivity value of 8 means that the eight nearest neighbor pixels (those that share a corner) will be considered. The next 8 bits (8-16) contain a value between 1 and 255 with which to fill the mask (the default value is 1). For example, 4 | ( 255 << 8 ) will consider 4 nearest neighbours and fill the mask with a value of 255. The following additional options occupy higher bits and therefore may be further combined with the connectivity and mask fill values using bit-wise or (|), see FloodFillFlags. | ||
| */ | ||
| floodFill<T extends number | Vec3>(seedPoint: Point2, newVal: T, mask?: Mat, loDiff?: T, upDiff?: T, flags?: T): { returnValue: number, rect: Rect }; | ||
| floodFill<T extends number | Vec3>(seedPoint: Point2, newVal: T, opts: { mask?: Mat, loDiff?: T, upDiff?: T, flags?: T }): { returnValue: number, rect: Rect }; | ||
| floodFillAsync<T extends number | Vec3>(seedPoint: Point2, newVal: T, mask?: Mat, loDiff?: T, upDiff?: T, flags?: number): Promise<{ returnValue: number, rect: Rect }>; | ||
| floodFillAsync<T extends number | Vec3>(seedPoint: Point2, newVal: T, opts: { mask?: Mat, loDiff?: T, upDiff?: T, flags?: number }): Promise<{ returnValue: number, rect: Rect }>; | ||
| gaussianBlur(kSize: Size, sigmaX: number, sigmaY?: number, borderType?: number): Mat; | ||
@@ -188,6 +234,17 @@ gaussianBlurAsync(kSize: Size, sigmaX: number, sigmaY?: number, borderType?: number): Promise<Mat>; | ||
| getDataAsync(): Promise<Buffer>; | ||
| /** | ||
| * if Mat.dims <= 2 | ||
| */ | ||
| getDataAsArray(): number[][]; | ||
| /** | ||
| * if Mat.dims > 2 (3D) | ||
| */ | ||
| getDataAsArray(): number[][][]; | ||
| getOptimalNewCameraMatrix(distCoeffs: number[], imageSize: Size, alpha: number, newImageSize?: Size, centerPrincipalPoint?: boolean): { out: Mat, validPixROI: Rect }; | ||
| getOptimalNewCameraMatrixAsync(distCoeffs: number[], imageSize: Size, alpha: number, newImageSize?: Size, centerPrincipalPoint?: boolean): Promise<{ out: Mat, validPixROI: Rect }>; | ||
| /** | ||
| * crop a region from the image | ||
| * like python Mat[x1,y1,x2,y2] | ||
| * @param region | ||
| */ | ||
| getRegion(region: Rect): Mat; | ||
@@ -216,4 +273,14 @@ goodFeaturesToTrack(maxCorners: number, qualityLevel: number, minDistance: number, mask?: Mat, blockSize?: number, gradientSize?: number, useHarrisDetector?: boolean, harrisK?: number): Point2[]; | ||
| inRangeAsync(lower: Vec3, upper: Vec3): Promise<Mat>; | ||
| /** | ||
| * Calculates the integral of an image. | ||
| * | ||
| * https://docs.opencv.org/4.x/d7/d1b/group__imgproc__misc.html#ga97b87bec26908237e8ba0f6e96d23e28 | ||
| * | ||
| * @param sdepth desired depth of the integral and the tilted integral images, CV_32S, CV_32F, or CV_64F. | ||
| * @param sqdepth desired depth of the integral image of squared pixel values, CV_32F or CV_64F. | ||
| */ | ||
| integral(sdepth?: number, sqdepth?: number): { sum: Mat, sqsum: Mat, tilted: Mat }; | ||
| integral(opts: { sdepth?: number, sqdepth?: number }): { sum: Mat, sqsum: Mat, tilted: Mat }; | ||
| integralAsync(sdepth?: number, sqdepth?: number): Promise<{ sum: Mat, sqsum: Mat, tilted: Mat }>; | ||
| integralAsync(opts: { sdepth?: number, sqdepth?: number }): Promise<{ sum: Mat, sqsum: Mat, tilted: Mat }>; | ||
| inv(): Mat; | ||
@@ -225,2 +292,16 @@ laplacian(ddepth: number, ksize?: number, scale?: number, delta?: number, borderType?: number): Mat; | ||
| matMulDerivAsync(B: Mat): Promise<{ dABdA: Mat, dABdB: Mat }>; | ||
| /** | ||
| * Compares a template against overlapped image regions. | ||
| * | ||
| * The function slides through image , compares the overlapped patches of size w×h against templ using the specified method and stores the comparison results in result . TemplateMatchModes describes the formulae for the available comparison methods ( I denotes image, T template, R result, M the optional mask ). The summation is done over template and/or the image patch: x′=0...w−1,y′=0...h−1 | ||
| * After the function finishes the comparison, the best matches can be found as global minimums (when TM_SQDIFF was used) or maximums (when TM_CCORR or TM_CCOEFF was used) using the minMaxLoc function. In case of a color image, template summation in the numerator and each sum in the denominator is done over all of the channels and separate mean values are used for each channel. That is, the function can take a color template and a color image. The result will still be a single-channel image, which is easier to analyze. | ||
| * | ||
| * https://docs.opencv.org/4.x/df/dfb/group__imgproc__object.html#ga586ebfb0a7fb604b35a23d85391329be | ||
| * | ||
| * @param template Searched template. It must be not greater than the source image and have the same data type. | ||
| * @param method Parameter specifying the comparison method, see TemplateMatchModes | ||
| * @param mask Optional mask. It must have the same size as templ. It must either have the same number of channels as template or only one channel, which is then used for all template and image channels. If the data type is CV_8U, the mask is interpreted as a binary mask, meaning only elements where mask is nonzero are used and are kept unchanged independent of the actual mask value (weight equals 1). For data tpye CV_32F, the mask values are used as weights. The exact formulas are documented in TemplateMatchModes. | ||
| * | ||
| * @return Map of comparison results. It must be single-channel 32-bit floating-point. If image is W×H and templ is w×h , then result is (W−w+1)×(H−h+1) . | ||
| */ | ||
| matchTemplate(template: Mat, method: number, mask?: Mat): Mat; | ||
@@ -234,2 +315,13 @@ matchTemplateAsync(template: Mat, method: number, mask?: Mat): Promise<Mat>; | ||
| medianBlurAsync(kSize: number): Promise<Mat>; | ||
| /** | ||
| * Finds the global minimum and maximum in an array. | ||
| * | ||
| * The function cv::minMaxLoc finds the minimum and maximum element values and their positions. The extremums are searched across the whole array or, if mask is not an empty array, in the specified array region. | ||
| * | ||
| * The function do not work with multi-channel arrays. If you need to find minimum or maximum elements across all the channels, use Mat::reshape first to reinterpret the array as single-channel. Or you may extract the particular channel using either extractImageCOI , or mixChannels , or split . | ||
| * | ||
| * https://docs.opencv.org/4.x/d2/de8/group__core__array.html#gab473bf2eb6d14ff97e89b355dac20707 | ||
| * | ||
| * @param mask optional mask used to select a sub-array. | ||
| */ | ||
| minMaxLoc(mask?: Mat): { minVal: number, maxVal: number, minLoc: Point2, maxLoc: Point2 }; | ||
@@ -246,18 +338,18 @@ minMaxLocAsync(mask?: Mat): Promise<{ minVal: number, maxVal: number, minLoc: Point2, maxLoc: Point2 }>; | ||
| norm(normType?: number, mask?: Mat): number; | ||
| normalize(alpha?: number, beta?: number, normType?: number, dtype?: number, mask?: Mat): Mat; | ||
| normalize(opt: {alpha?: number, beta?: number, normType?: number, dtype?: number, mask?: Mat}): Mat; | ||
| normalize(opt: { alpha?: number, beta?: number, normType?: number, dtype?: number, mask?: Mat }): Mat; | ||
| normalizeAsync(alpha?: number, beta?: number, normType?: number, dtype?: number, mask?: Mat): Promise<Mat>; | ||
| normalizeAsync(opt: {alpha?: number, beta?: number, normType?: number, dtype?: number, mask?: Mat}): Promise<Mat>; | ||
| normalizeAsync(opt: { alpha?: number, beta?: number, normType?: number, dtype?: number, mask?: Mat }): Promise<Mat>; | ||
| or(otherMat: Mat): Mat; | ||
| padToSquare(color: Vec3): Mat; | ||
| perspectiveTransform(m: Mat): Mat; | ||
| perspectiveTransformAsync(m: Mat): Promise<Mat>; | ||
| pop_back(numRows?: number): Mat; | ||
| pop_backAsync(numRows?: number): Promise<Mat>; | ||
| popBack(numRows?: number): Mat; | ||
@@ -271,36 +363,36 @@ popBackAsync(numRows?: number): Promise<Mat>; | ||
| pushBackAsync(mat: Mat): Promise<Mat>; | ||
| putText(text: string, origin: Point2, fontFace: number, fontScale: number, color?: Vec3, thickness?: number, lineType?: number, bottomLeftOrigin?: boolean | 0): void; | ||
| putText(text: string, origin: Point2, fontFace: number, fontScale: number, opts?: { color?: Vec3, thickness?: number, lineType?: number, bottomLeftOrigin?: boolean | 0 }): void; | ||
| putTextAsync(text: string, origin: Point2, fontFace: number, fontScale: number, color?: Vec3, thickness?: number, lineType?: number, bottomLeftOrigin?: boolean | 0): Promise<void>; | ||
| putTextAsync(text: string, origin: Point2, fontFace: number, fontScale: number, opts?: { color?: Vec3, thickness?: number, lineType?: number, bottomLeftOrigin?: boolean | 0 }): Promise<void>; | ||
| pyrDown(size?: Size, borderType?: number): Mat; | ||
| pyrDownAsync(size?: Size, borderType?: number): Promise<Mat>; | ||
| pyrUp(size?: Size, borderType?: number): Mat; | ||
| pyrUpAsync(size?: Size, borderType?: number): Promise<Mat>; | ||
| recoverPose(E: Mat, points1: Point2[], points2: Point2[], mask?: Mat): { returnValue: number, R: Mat, T: Vec3 }; | ||
| recoverPoseAsync(E: Mat, points1: Point2[], points2: Point2[], mask?: Mat): Promise<{ returnValue: number, R: Mat, T: Vec3 }>; | ||
| rectify3Collinear(distCoeffs1: number[], cameraMatrix2: Mat, distCoeffs2: number[], cameraMatrix3: Mat, distCoeffs3: number[], imageSize: Size, R12: Mat, T12: Vec3, R13: Mat, T13: Vec3, alpha: number, newImageSize: Size, flags: number): { returnValue: number, R1: Mat, R2: Mat, R3: Mat, P1: Mat, P2: Mat, P3: Mat, Q: Mat, roi1: Rect, roi2: Rect }; | ||
| rectify3CollinearAsync(distCoeffs1: number[], cameraMatrix2: Mat, distCoeffs2: number[], cameraMatrix3: Mat, distCoeffs3: number[], imageSize: Size, R12: Mat, T12: Vec3, R13: Mat, T13: Vec3, alpha: number, newImageSize: Size, flags: number): Promise<{ returnValue: number, R1: Mat, R2: Mat, R3: Mat, P1: Mat, P2: Mat, P3: Mat, Q: Mat, roi1: Rect, roi2: Rect }>; | ||
| reduce(dim: number, rtype: number, dtype?: number): Mat; | ||
| reduceAsync(dim: number, rtype: number, dtype?: number): Promise<Mat>; | ||
| reprojectImageTo3D(Q: Mat, handleMissingValues?: boolean, ddepth?: number): Mat; | ||
| reprojectImageTo3DAsync(Q: Mat, handleMissingValues?: boolean, ddepth?: number): Promise<Mat>; | ||
| rescale(factor: number): Mat; | ||
| rescaleAsync(factor: number): Promise<Mat>; | ||
| resize(rows: number, cols: number, fx?: number, fy?: number, interpolation?: number): Mat; | ||
| resize(dsize: Size, fx?: number, fy?: number, interpolation?: number): Mat; | ||
| resizeAsync(rows: number, cols: number, fx?: number, fy?: number, interpolation?: number): Promise<Mat>; | ||
| resizeAsync(dsize: Size, fx?: number, fy?: number, interpolation?: number): Promise<Mat>; | ||
| resizeToMax(maxRowsOrCols: number): Mat; | ||
@@ -319,9 +411,41 @@ resizeToMaxAsync(maxRowsOrCols: number): Promise<Mat>; | ||
| seamlessCloneAsync(dst: Mat, mask: Mat, p: Point2, flags: number): Promise<Mat>; | ||
| /** | ||
| * Applies a separable linear filter to an image. | ||
| * | ||
| * The function applies a separable linear filter to the image. That is, first, every row of src is filtered with the 1D kernel kernelX. Then, every column of the result is filtered with the 1D kernel kernelY. The final result shifted by delta is stored in dst . | ||
| * | ||
| * https://docs.opencv.org/4.x/d4/d86/group__imgproc__filter.html#ga910e29ff7d7b105057d1625a4bf6318d | ||
| * | ||
| * @param ddepth Destination image depth, see combinations | ||
| * @param kernelX Coefficients for filtering each row. | ||
| * @param kernelY Coefficients for filtering each column. | ||
| * @param anchor Anchor position within the kernel. The default value (−1,−1) means that the anchor is at the kernel center. | ||
| * @param delta Value added to the filtered results before storing them. | ||
| * @param borderType Pixel extrapolation method, see BorderTypes. BORDER_WRAP is not supported. | ||
| */ | ||
| sepFilter2D(ddepth: number, kernelX: Mat, kernelY: Mat, anchor?: Point2, delta?: number, borderType?: number): Mat; | ||
| sepFilter2D(ddepth: number, kernelX: Mat, kernelY: Mat, opts: { anchor?: Point2, delta?: number, borderType?: number }): Mat; | ||
| sepFilter2DAsync(ddepth: number, kernelX: Mat, kernelY: Mat, anchor?: Point2, delta?: number, borderType?: number): Promise<Mat>; | ||
| sepFilter2DAsync(ddepth: number, kernelX: Mat, kernelY: Mat, opts: { anchor?: Point2, delta?: number, borderType?: number }): Promise<Mat>; | ||
| set(row: number, col: number, value: number | Vec2 | Vec3 | Vec4 | number[]): void; | ||
| setTo(value: number | Vec2 | Vec3 | Vec4, mask?: Mat): Mat; | ||
| setToAsync(value: number | Vec2 | Vec3 | Vec4, mask?: Mat): Promise<Mat>; | ||
| sobel(ddepth: number, dx: number, dy: number, ksize?: number, scale?: number, delta?: number, borderType?: number): Mat; | ||
| sobelAsync(ddepth: number, dx: number, dy: number, ksize?: number, scale?: number, delta?: number, borderType?: number): Promise<Mat>; | ||
| /** | ||
| * | ||
| * https://docs.opencv.org/4.x/d4/d86/group__imgproc__filter.html#gacea54f142e81b6758cb6f375ce782c8d | ||
| * | ||
| * @param ddepth output image depth, see combinations; in the case of 8-bit input images it will result in truncated derivatives. | ||
| * @param dx order of the derivative x. | ||
| * @param dy order of the derivative y. | ||
| * @param ksize size of the extended Sobel kernel; it must be 1, 3, 5, or 7. | ||
| * @param scale optional scale factor for the computed derivative values; by default, no scaling is applied (see getDerivKernels for details). | ||
| * @param delta optional delta value that is added to the results prior to storing them in dst. | ||
| * @param borderType pixel extrapolation method, see BorderTypes. BORDER_WRAP is not supported. | ||
| */ | ||
| sobel(ddepth: number, dx: number, dy: number, ksize?: 1 | 3 | 5 | 7, scale?: number, delta?: number, borderType?: number): Mat; | ||
| sobel(ddepth: number, dx: number, dy: number, opts: { ksize?: 1 | 3 | 5 | 7, scale?: number, delta?: number, borderType?: number }): Mat; | ||
| sobelAsync(ddepth: number, dx: number, dy: number, ksize?: 1 | 3 | 5 | 7, scale?: number, delta?: number, borderType?: number): Promise<Mat>; | ||
| sobelAsync(ddepth: number, dx: number, dy: number, opts: { ksize?: 1 | 3 | 5 | 7, scale?: number, delta?: number, borderType?: number }): Promise<Mat>; | ||
| solve(mat2: Mat, flags?: number): Mat; | ||
@@ -339,11 +463,58 @@ solveAsync(mat2: Mat, flags?: number): Promise<Mat>; | ||
| sub(otherMat: Mat): Mat; | ||
| /** | ||
| * Calculates the sum of array elements. | ||
| * The function cv::sum calculates and returns the sum of array elements, independently for each channel. | ||
| * https://docs.opencv.org/4.x/d2/de8/group__core__array.html#ga716e10a2dd9e228e4d3c95818f106722 | ||
| * Mat must have from 1 to 4 channels. | ||
| */ | ||
| sum(): number | Vec2 | Vec3 | Vec4; | ||
| sumAsync(): Promise<number | Vec2 | Vec3 | Vec4>; | ||
| /** | ||
| * Applies a fixed-level threshold to each array element. | ||
| * | ||
| * The function applies fixed-level thresholding to a multiple-channel array. The function is typically used to get a bi-level (binary) image out of a grayscale image ( compare could be also used for this purpose) or for removing a noise, that is, filtering out pixels with too small or too large values. There are several types of thresholding supported by the function. They are determined by type parameter. | ||
| * | ||
| * Also, the special values THRESH_OTSU or THRESH_TRIANGLE may be combined with one of the above values. In these cases, the function determines the optimal threshold value using the Otsu's or Triangle algorithm and uses it instead of the specified thresh. | ||
| * | ||
| * Note: Currently, the Otsu's and Triangle methods are implemented only for 8-bit single-channel images. | ||
| * https://docs.opencv.org/4.x/d7/d1b/group__imgproc__misc.html#gae8a4a146d1ca78c626a53577199e9c57 | ||
| * @param thresh threshold value. | ||
| * @param maxVal maximum value to use with the THRESH_BINARY and THRESH_BINARY_INV thresholding types | ||
| * @param type thresholding type (see ThresholdTypes). | ||
| */ | ||
| threshold(thresh: number, maxVal: number, type: number): Mat; | ||
| thresholdAsync(thresh: number, maxVal: number, type: number): Promise<Mat>; | ||
| transform(m: Mat): Mat; | ||
| transformAsync(m: Mat): Promise<Mat>; | ||
| transpose(): Mat; | ||
| /** | ||
| * This function reconstructs 3-dimensional points (in homogeneous coordinates) by using their observations with a stereo camera. | ||
| * | ||
| * https://docs.opencv.org/4.x/d9/d0c/group__calib3d.html#gad3fc9a0c82b08df034234979960b778c | ||
| * @param projPoints1 2xN array of feature points in the first image. In the case of the c++ version, it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1. | ||
| * @param projPoints2 2xN array of corresponding points in the second image. In the case of the c++ version, it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1. | ||
| */ | ||
| triangulatePoints(projPoints1: Point2[], projPoints2: Point2[]): Mat; | ||
| triangulatePointsAsync(projPoints1: Point2[], projPoints2: Point2[]): Promise<Mat>; | ||
| /** | ||
| * Transforms an image to compensate for lens distortion. | ||
| * | ||
| * The function transforms an image to compensate radial and tangential lens distortion. | ||
| * | ||
| * The function is simply a combination of initUndistortRectifyMap (with unity R ) and remap (with bilinear interpolation). See the former function for details of the transformation being performed. | ||
| * | ||
| * Those pixels in the destination image, for which there is no correspondent pixels in the source image, are filled with zeros (black color). | ||
| * | ||
| * A particular subset of the source image that will be visible in the corrected image can be regulated by newCameraMatrix. You can use getOptimalNewCameraMatrix to compute the appropriate newCameraMatrix depending on your requirements. | ||
| * | ||
| * The camera matrix and the distortion parameters can be determined using calibrateCamera. If the resolution of images is different from the resolution used at the calibration stage, fx,fy,cx and cy need to be scaled accordingly, while the distortion coefficients remain the same. | ||
| * | ||
| * https://docs.opencv.org/4.x/d9/d0c/group__calib3d.html#ga69f2545a8b62a6b0fc2ee060dc30559d | ||
| * | ||
| * @param cameraMatrix Input camera matrix | ||
| * @param distCoeffs Input vector of distortion coefficients (k1,k2,p1,p2[,k3[,k4,k5,k6[,s1,s2,s3,s4[,τx,τy]]]]) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. | ||
| */ | ||
| undistort(cameraMatrix: Mat, distCoeffs: Mat): Mat; | ||
@@ -360,4 +531,17 @@ undistortAsync(cameraMatrix: Mat, distCoeffs: Mat): Promise<Mat>; | ||
| release(): void; | ||
| /** | ||
| * Returns an identity matrix of the specified size and type. | ||
| * | ||
| * The method returns a Matlab-style identity matrix initializer, similarly to Mat::zeros. Similarly to Mat::ones, you can use a scale operation to create a scaled identity matrix efficiently: | ||
| * | ||
| * // make a 4x4 diagonal matrix with 0.1's on the diagonal. | ||
| * Mat A = Mat::eye(4, 4, CV_32F)*0.1; | ||
| * | ||
| * Note: In case of multi-channels type, identity matrix will be initialized only for the first channel, the others will be set to 0's | ||
| * https://docs.opencv.org/4.x/d3/d63/classcv_1_1Mat.html#a458874f0ab8946136254da37ba06b78b | ||
| * @param rows Number of rows. | ||
| * @param cols Number of columns. | ||
| * @param type Created matrix type. | ||
| */ | ||
| static eye(rows: number, cols: number, type: number): Mat; | ||
| } |
@@ -33,4 +33,14 @@ import { Mat } from './Mat.d'; | ||
| // forward(outputName: string[]): Mat[]; | ||
| /** | ||
| * Runs forward pass to compute output of layer with name outputName. | ||
| * | ||
| * https://docs.opencv.org/3.4/db/d30/classcv_1_1dnn_1_1Net.html#a98ed94cb6ef7063d3697259566da310b | ||
| * | ||
| * @param inputName name for layer which output is needed to get | ||
| */ | ||
| forward(inputName?: string): Mat; | ||
| /** | ||
| * | ||
| * @param outBlobNames names for layers which outputs are needed to get | ||
| */ | ||
| forward(outBlobNames?: string[]): Mat[]; | ||
@@ -43,2 +53,29 @@ forwardAsync(inputName?: string): Promise<Mat>; | ||
| /** | ||
| * Ask network to use specific computation backend where it supported. | ||
| * | ||
| * @param backendId backend identifier. | ||
| */ | ||
| setPreferableBackend(backendId: number): void; | ||
| /** | ||
| * Ask network to make computations on specific target device. | ||
| * @param targetId target identifier. | ||
| */ | ||
| setPreferableTarget(targetId: number): void; | ||
| /** | ||
| * Returns overall time for inference and timings (in ticks) for layers. | ||
| * | ||
| * Indexes in returned vector correspond to layers ids. Some layers can be fused with others, in this case zero ticks count will be return for that skipped layers. Supported by DNN_BACKEND_OPENCV on DNN_TARGET_CPU only. | ||
| * | ||
| * https://docs.opencv.org/4.x/db/d30/classcv_1_1dnn_1_1Net.html#a06ce946f675f75d1c020c5ddbc78aedc | ||
| * | ||
| * [out] timings vector for tick timings for all layers. | ||
| * Returns | ||
| * overall ticks for model inference. | ||
| * WARN retval is a int64, which can overflow nodejs number | ||
| */ | ||
| getPerfProfile(): { retval: number, timings: number[] }; | ||
| } |
@@ -12,2 +12,3 @@ import { Mat } from './Mat.d'; | ||
| setAsync(property: number, value: number): Promise<boolean>; | ||
| // see VideoWriter for fourcc function | ||
| } |
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is not supported yet
New alerts
License Policy Violation
LicenseThis package is not allowed per your license policy. Review the package's license to ensure compliance.
Found 1 instance in 1 package
Fixed alerts
License Policy Violation
LicenseThis package is not allowed per your license policy. Review the package's license to ensure compliance.
Found 1 instance in 1 package
Improved metrics
- Total package byte prevSize
- increased by0.32%
16509676
- Number of package files
- increased by0.27%
372
- Lines of code
- increased by10.97%
4874