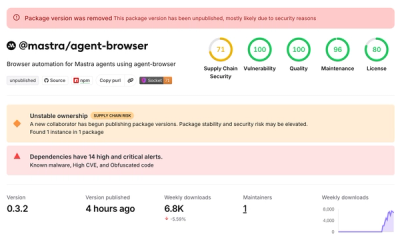
26 web scraping, crawling, deep-research & autonomous-extraction tools for Claude, Cursor & any MCP client.
Clean Markdown & structured JSON from any site. Get started with 1,000 free credits — no credit card required.






⭐ Star us on GitHub to follow along — it genuinely helps others discover the project.
Table of Contents
🎯 Why CrawlForge?
- 26 MCP-native tools — scraping, crawling, search, deep research, an autonomous
agent, a unified multi-format scrape, document processing, stealth browsing, and more, callable directly from your AI assistant.
- Generous free tier — 1,000 credits to start instantly, no credit card. Credits never expire and roll over month-to-month.
- Local-LLM by default —
extract_with_llm runs against a local Ollama model out of the box: no LLM API key, no per-token cost, and your data never leaves your machine. Cloud (OpenAI/Anthropic) is opt-in.
- LLM-ready output — clean Markdown, structured JSON (schema-driven), screenshots, links, and metadata from a single fetch.
- Autonomous
agent — describe what you need in natural language; it plans, gathers, and shapes an answer under orchestrator-enforced hard stops (max steps/URLs/wall-clock) — no URLs required.
- Security-hardened — SSRF protection on every request, a fail-closed backend allow-list, a vetted action allowlist for browser automation, and per-tool credit gating.
- Works everywhere MCP does — Claude Desktop, Claude Code, Cursor, and any other MCP-enabled client, configured in one command.
📊 CrawlForge vs. alternatives
| Native MCP server | ✅ 26 tools | ✅ | ❌ |
| Free tier | ✅ 1,000 credits, rollover | Limited | Varies |
| Self-hosted / local LLM extraction (Ollama) | ✅ default, $0/token | ❌ | ❌ |
| Autonomous agent (no URLs needed) | ✅ agent | ✅ | ❌ |
| Deep research with source verification | ✅ deep_research | Partial | ❌ |
| Browser automation / actions | ✅ scrape_with_actions | ✅ | Varies |
| Stealth / anti-detection engines | ✅ Chromium + Camoufox | ✅ | Add-on |
| Pre-built site templates | ✅ 10 sites | ❌ | ❌ |
| License | MIT | AGPL-3.0 | Proprietary |
Comparison reflects publicly documented capabilities at time of writing. CrawlForge is MIT-licensed and MCP-first — built to plug straight into AI coding assistants.
🚀 Quick Start (2 Minutes)
1. Install from NPM
npm install -g crawlforge-mcp-server
2. Setup Your API Key (optional for the free local tools)
The 15 free local tools work immediately with no API key at all — skip straight to step 3 if that's all you need. To unlock the metered premium tools (search_web, crawl_deep, stealth_mode, agent, …):
npx crawlforge-setup
This will:
- Guide you through getting your free API key
- Configure your credentials securely
- Auto-configure Claude Code and Cursor (if installed)
- Verify your setup is working
Don't have an API key? Get one free at https://www.crawlforge.dev/signup
One-step setup (v4.6.0+): crawlforge init detects your API key, installs the agent skill, and idempotently merges the MCP config stanza into Claude Code, Claude Desktop, and Cursor. Use crawlforge init --all --yes to configure every detected client non-interactively.
3. Configure Your IDE (if not auto-configured)
🤖 For Claude Desktop
Add to claude_desktop_config.json:
{
"mcpServers": {
"crawlforge": {
"command": "npx",
"args": ["-y", "crawlforge-mcp-server"]
}
}
}
Location:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json
- Windows:
%APPDATA%/Claude/claude_desktop_config.json
- Linux:
~/.config/Claude/claude_desktop_config.json
Restart Claude Desktop to activate.
🖥️ For Claude Code CLI (Auto-configured)
The setup wizard automatically configures Claude Code by adding to ~/.claude.json:
{
"mcpServers": {
"crawlforge": {
"type": "stdio",
"command": "crawlforge-mcp"
}
}
}
After setup, restart Claude Code to activate.
💻 For Cursor IDE (Auto-configured)
The setup wizard automatically configures Cursor by adding to ~/.cursor/mcp.json:
{
"mcpServers": {
"crawlforge": {
"type": "stdio",
"command": "crawlforge-mcp"
}
}
}
Restart Cursor to activate.
Which launch command? npx -y crawlforge-mcp-server needs no global install and always runs the published version (recommended for Claude Desktop). For a global install (npm i -g crawlforge-mcp-server), use the dedicated crawlforge-mcp bin — it resolves on your PATH, so it survives Node/nvm version switches. The bare crawlforge command still launches the server when an MCP client spawns it over stdio (backward compatibility for configs created before v4.2.5); interactively it's the CLI — run crawlforge mcp to start the server by hand.
📊 Available Tools
CrawlForge is open-core: 15 tools run locally on your machine and are completely free — no API key required. The metered premium tools cover real infrastructure (search fees, proxies, browser farms) and need an API key.
Free Local Tools (0 credits, no API key needed)
fetch_url | Fetch content from any URL |
extract_text | Extract clean text from web pages |
extract_links | Get all links from a page |
extract_metadata | Extract page metadata (title, OG tags, schema.org) |
scrape | Unified single-fetch, multi-format extraction. Pass a formats array (markdown/html/rawHtml/text/links/metadata/screenshot/json-schema) plus onlyMainContent; one fetch serves every requested format with per-format partial-success warnings. The screenshot format is the one metered exception (2 credits — needs a server browser) |
scrape_structured | Extract structured data with CSS selectors |
scrape_template | Structured data from well-known sites (Amazon, GitHub, LinkedIn, YouTube, Reddit, Hacker News, npm, and more) without writing selectors |
extract_content | Enhanced content extraction |
summarize_content | Generate intelligent summaries |
analyze_content | Comprehensive content analysis |
extract_structured | LLM-powered schema-driven extraction (your own LLM key or local Ollama) |
extract_with_llm | Natural-language extraction. Defaults to a local Ollama model — no API key, no API costs. Pass provider: "openai" | "anthropic" with the matching key for cloud models |
process_document | Multi-format document processing |
list_ollama_models | List the Ollama models installed locally (helps you pick a model for extract_with_llm) |
get_batch_results | Retrieve paginated results for a batch_scrape job by batchId |
Metered Premium Tools (3–10 credits, API key required)
map_site | 3 | Discover and map website structure (optional search= ranks the discovered URLs) |
track_changes | 3 | Monitor content changes over time |
search_web | 5 | Search the web using Google Search API |
crawl_deep | 5 | Deep crawl entire websites |
batch_scrape | 5 | Process multiple URLs simultaneously |
scrape_with_actions | 5 | Browser automation chains |
generate_llms_txt | 5 | Generate AI interaction guidelines |
localization | 5 | Multi-language and geo-location management |
agent | 8 | Autonomous research/extraction from a natural-language prompt — no URLs required. Plans, gathers, and shapes an answer under hard safety stops (max steps/URLs/wall-clock enforced by the orchestrator, never the LLM) |
deep_research | 10 | Multi-stage research with source verification |
stealth_mode | 10 | Anti-detection browser management |
For the full canonical capabilities reference (all tools, CLI commands, stealth engines, research workflow), see SKILL.md.
↑ Back to top
💳 Pricing
15 local tools are free forever — no API key, no credit card. Credits only meter the premium tools that run on CrawlForge infrastructure.
| Free | 1,000 | Testing & personal projects |
| Hobby ($19) | 5,000 | Small projects & development |
| Professional ($99) | 50,000 | Professional use & production |
| Business ($399) | 250,000 | Large scale operations |
All plans include:
- Access to all 26 tools (the 15 local tools never consume credits)
- Credits never expire and roll over month-to-month
- API access and webhook notifications
View full pricing
🔧 Advanced Configuration
Environment Variables
export CRAWLFORGE_API_KEY="cf_live_your_api_key_here"
export CRAWLFORGE_API_URL="https://api.crawlforge.dev"
export OLLAMA_BASE_URL="http://localhost:11434"
export OLLAMA_DEFAULT_MODEL="llama3.2"
export OPENAI_API_KEY="sk-..."
export ANTHROPIC_API_KEY="sk-ant-..."
export RESEARCH_STEALTH_ENGINE="auto"
export RESEARCH_STEALTH_FALLBACK="true"
export RESEARCH_MAX_STEALTH_RETRIES="8"
extract_with_llm defaults to a local Ollama model — no API key, no API costs, no data leaving your machine.
ollama pull llama3.2
deep_research automatically retries sources that block the normal fetch path (Reddit, Quora, forums, and Cloudflare/DataDome-protected pages return HTTP 403) through a real fingerprinted browser, then re-extracts from the rendered HTML. It's bounded (RESEARCH_MAX_STEALTH_RETRIES, default 8, plus a per-page timeout) and lazy — the browser stack only loads when a source is actually blocked.
Engine selection (RESEARCH_STEALTH_ENGINE):
auto (default) — prefer Camoufox (Firefox anti-detect), fall back to Chromium stealth, then plain fetch.camoufox — force Camoufox.chromium — force the Chromium stealth engine.
Headless Chromium cannot clear modern challenges (Cloudflare Turnstile, DataDome) — Camoufox can. In testing it recovered Quora and Trustpilot pages that were otherwise fully blocked. To enable it, install the optional dependency and run its one-time binary fetch:
npm install camoufox
npx camoufox fetch
Without the Camoufox binary, deep_research silently falls back to Chromium stealth and then to plain fetch — no errors, just lower recovery on heavily-protected sites. Disable the whole fallback with RESEARCH_STEALTH_FALLBACK=false.
Note: Hard IP-reputation blocks (e.g. Reddit's edge 403) resist headless stealth from any IP and require residential/mobile proxies, which CrawlForge does not provide. See docs/stealth-engines.md for details.
Manual Configuration
Your configuration is stored at ~/.crawlforge/config.json:
{
"apiKey": "cf_live_...",
"userId": "user_...",
"email": "you@example.com"
}
📖 Usage Examples
Once configured, use these tools in your AI assistant:
"Search for the latest AI news"
"Extract all links from example.com"
"Crawl the documentation site and summarize it"
"Monitor this page for changes"
"Extract product prices from this e-commerce site"
🔒 Security & Privacy
- Secure Authentication: API keys required for all metered premium tools (the 15 free local tools run without one)
- Local Storage: API keys stored securely at
~/.crawlforge/config.json
- HTTPS Only: All connections use encrypted HTTPS
- No Data Retention: We don't store scraped data, only usage logs
- Rate Limiting: Built-in protection against abuse
- Compliance: Respects robots.txt and GDPR requirements
Security & Approvals
- SSRF enforcement: Every scraped URL is validated before the request is sent — http/https only; blocks loopback, RFC1918, IPv6 private/link-local ranges, cloud metadata endpoints (GCP, Azure), and dangerous ports (SSH, SMTP, DNS, MySQL, Postgres, Redis, MongoDB, etc.). Redirects are re-validated each hop, capped at 5.
- Backend endpoint guard (v3.0.18): The server's own calls to CrawlForge.dev use a separate fail-closed allow-list (
{crawlforge.dev, www.crawlforge.dev, api.crawlforge.dev}, HTTPS required). Setting CRAWLFORGE_API_URL to an arbitrary host is blocked at parse time.
- Action allowlist:
scrape_with_actions accepts only 7 action types (wait, click, type, press, scroll, screenshot, executeJavaScript). No download, file-write, or arbitrary cross-page navigation primitives exist.
- JavaScript gate: The
executeJavaScript action throws by default. Set ALLOW_JAVASCRIPT_EXECUTION=true at deploy time to enable (not recommended in production).
- MCP Elicitation (v3.6.0): Four tools request user confirmation before executing expensive operations —
deep_research (>50 URLs), batch_scrape (sync mode, >25 URLs), crawl_deep (projected >500 pages), extract_structured (schema has >3 required fields with no LLM configured). Credit-low situations also elicit. Confirmation is best-effort: if the MCP client does not support elicitation the tool proceeds (fail-open).
- Per-tool credit gating: Every tool is wrapped with
withAuth(); metered tools check and deduct credits before execution (fail-closed since v3.0.18). Free local tools (cost 0) skip the credit path entirely.
See docs/sandboxing-and-approvals.md for the full reference.
Security Updates
v3.0.3 (2025-10-01): Removed authentication bypass vulnerability. All users must authenticate with valid API keys.
For the full security policy and how to report a vulnerability, see SECURITY.md.
↑ Back to top
🆘 Support
📄 License
MIT License - see LICENSE file for details.
🤝 Contributing
Contributions are welcome! Please read our Contributing Guide first.
Built with ❤️ by the CrawlForge team
Website | Documentation | API Reference