What is isbot?
The 'isbot' npm package is a lightweight utility for detecting bots, crawlers, and spiders based on the user agent string. It helps developers identify non-human traffic to their websites or applications.
What are isbot's main functionalities?
Basic Bot Detection
This feature allows you to check if a given user agent string belongs to a bot. The function returns true if the user agent is identified as a bot, otherwise false.
const isBot = require('isbot');
const userAgent = 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)';
console.log(isBot(userAgent)); // true
Custom Bot Patterns
You can extend the default bot detection patterns with custom patterns. This is useful if you have specific bots that are not covered by the default list.
const isBot = require('isbot');
isBot.extend(['my-custom-bot']);
const userAgent = 'my-custom-bot';
console.log(isBot(userAgent)); // true
Bot Detection in HTTP Requests
This feature demonstrates how to use 'isbot' to detect bots in incoming HTTP requests. Depending on whether the user agent is a bot, the server responds with a different message.
const isBot = require('isbot');
const http = require('http');
http.createServer((req, res) => {
if (isBot(req.headers['user-agent'])) {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, bot!');
} else {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, human!');
}
}).listen(3000);
Other packages similar to isbot
useragent
The 'useragent' package provides detailed parsing of user agent strings, including bot detection. It offers more comprehensive information about the user agent, such as browser, version, and OS, but may be more complex to use compared to 'isbot'.
express-useragent
The 'express-useragent' package is an Express middleware for parsing user agent strings. It includes bot detection and provides additional details about the user agent. It is specifically designed for use with Express.js applications.
ua-parser-js
The 'ua-parser-js' package is a JavaScript library for parsing user agent strings. It includes bot detection and provides detailed information about the browser, engine, OS, and device. It is a more general-purpose library compared to 'isbot'.
isbot 🤖/👨🦰






Detect bots/crawlers/spiders using the user agent string.
Usage
import isbot from 'isbot'
isbot(request.getHeader('User-Agent'))
isbot(req.get('user-agent'))
isbot(navigator.userAgent)
isbot('Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)')
isbot('Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36')
Additional functionality
Extend: Add user agent patterns
Add rules to user agent match RegExp: Array of strings
isbot('Mozilla/5.0')
isbot.extend([
'istat',
'^mozilla/\\d\\.\\d$'
])
isbot('Mozilla/5.0')
Exclude: Remove matches of known crawlers
Remove rules to user agent match RegExp (see existing rules in src/list.json file)
isbot('Chrome-Lighthouse')
isbot.exclude(['chrome-lighthouse'])
isbot('Chrome-Lighthouse')
Find: Verbose result
Return the respective match for bot user agent rule
isbot.find('Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0 DejaClick/2.9.7.2')
Matches: Get patterns
Return all patterns that match the user agent string
isbot.matches('Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0 SearchRobot/1.0')
Clear:
Remove all matching patterns so this user agent string will pass
const ua = 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0 SearchRobot/1.0';
isbot(ua)
isbot.clear(ua)
isbot(ua)
Spawn: Create new instances
Create new instances of isbot. Instance is spawned using spawner's list as base
const one = isbot.spawn()
const two = isbot.spawn()
two.exclude(['chrome-lighthouse'])
one('Chrome-Lighthouse')
two('Chrome-Lighthouse')
Create isbot using custom list (instead of the maintained list)
const lean = isbot.spawn([ 'bot' ])
lean('Googlebot')
lean('Chrome-Lighthouse')
Definitions
- Bot. Autonomous program imitating or replacing some aspect of a human behaviour, performing repetitive tasks much faster than human users could.
- Good bot. Automated programs who visit websites in order to collect useful information. Web crawlers, site scrapers, stress testers, preview builders and other programs are welcomed on most websites because they serve purposes of mutual benefits.
- Bad bot. Programs which are designed to perform malicious actions, ultimately hurting businesses. Testing credential databases, DDoS attacks, spam bots.
Clarifications
What does "isbot" do?
This package aims to identify "Good bots". Those who voluntarily identify themselves by setting a unique, preferably descriptive, user agent, usually by setting a dedicated request header.
What doesn't "isbot" do?
It does not try to recognise malicious bots or programs disguising themselves as real users.
Why would I want to identify good bots?
Recognising good bots such as web crawlers is useful for multiple purposes. Although it is not recommended to serve different content to web crawlers like Googlebot, you can still elect to
- Flag pageviews to consider with business analysis.
- Prefer to serve cached content and relieve service load.
- Omit third party solutions' code (tags, pixels) and reduce costs.
It is not recommended to whitelist requests for any reason based on user agent header only. Instead other methods of identification can be added such as reverse dns lookup.
Data sources
We use external data sources on top of our own lists to keep up to date
Crawlers user agents:
Non bot user agents:
Missing something? Please open an issue
Major releases breaking changes (full changelog)
Remove testing for node 6 and 8
Change return value for isbot: true instead of matched string
No functional change
Real world data
| Execution times in milliseconds |
|---|
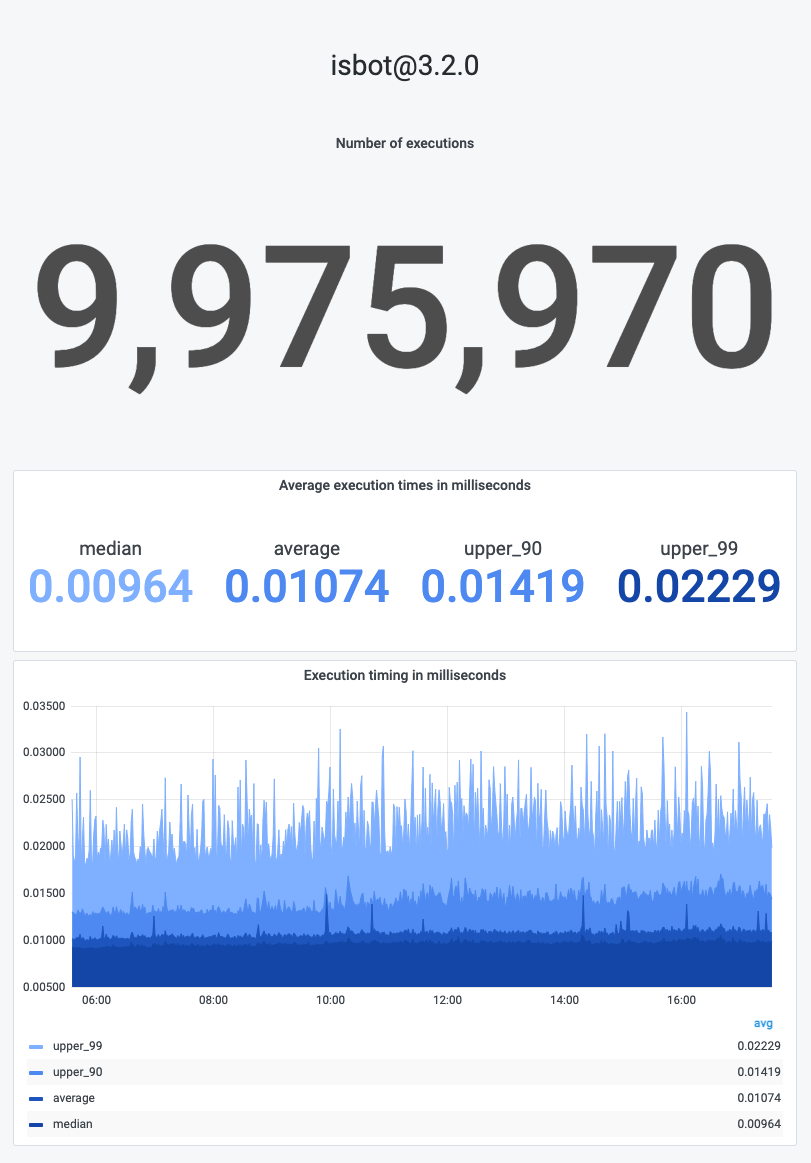 |



