Research
/Security News
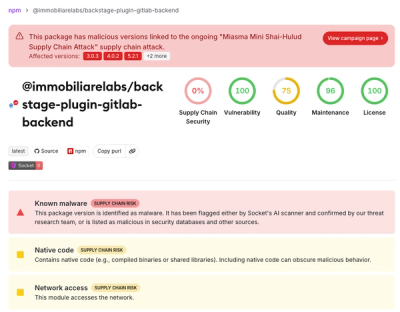
Miasma Mini Shai-Hulud Hits ImmobiliareLabs npm Packages
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.
By Socket Research Team - Jun 26, 2026
Learn as you build. Build with intent. — A multi-platform agentic engineering system for Windsurf, Claude Code, Cursor, OpenCode, Gemini CLI, and Codex: 57 spec-driven workflows, 17 specialist agent personas, integrated learning, and production-grade desi

![]()

![]()


Agentic engineering done right. Learn as you build. Build with intent.
A context engineering and spec-driven development system for Claude Code, Windsurf, Cursor, OpenCode, Gemini CLI, and Codex CLI.
Install · 5 Commands · Phase Loop · How It Works · All Workflows · Full Docs · Changelog

npx learnship
Works on Mac, Windows, and Linux. Requires Node.js ≥ 22 and Git. The installer auto-detects your platform.
npx learnship --global # all projects
npx learnship --local # this project only
npx learnship --all --global # all 6 platforms at once
Then open your AI agent and type:
/ls
That's it. /ls tells you where you are, what to do next, and offers to run it.
| Platform | Install command | Invoke commands as |
|---|---|---|
| Windsurf | npx learnship --windsurf --global | /ls, /new-project |
| Claude Code | npx learnship --claude --global | /learnship:ls, /learnship:new-project |
| Cursor | /add-plugin learnship (marketplace) | @learnship rules load automatically |
| OpenCode | npx learnship --opencode --global | /learnship-ls, /learnship-new-project |
| Gemini CLI | npx learnship --gemini --global | /learnship:ls, /learnship:new-project |
| Codex CLI | npx learnship --codex --global | $learnship-ls, $learnship-new-project |
Via marketplace (no terminal required):
# Claude Code — community marketplace
/plugin marketplace add FavioVazquez/learnship-marketplace
/plugin install learnship@learnship-marketplace
# Cursor — after marketplace approval
/add-plugin learnship
# Gemini CLI — native extension
gemini extensions install https://github.com/FavioVazquez/learnship
Custom install directory:
npx learnship --claude --global --target /path/to/custom/dir
--target overrides the default platform directory. Works with install and uninstall on all 6 platforms.
learnship is published to npm — npx learnship pulls the latest release directly. No github: prefix, no clone needed. The same bin/install.js runs regardless of install method.

learnship has 57 workflows. You need five. Everything else surfaces naturally from /ls.
| Command | What it does | When to use |
|---|---|---|
/ls | Show status, recent work, and next step (and offer to run it) | Start every session here |
/next | Read state and immediately run the right next workflow | When you just want to keep moving |
/new-project | Full init: questions → research → requirements → roadmap | Starting a new project |
/quick "..." | One-off task with atomic commits, no planning ceremony | Small fixes, experiments |
/help | All 57 workflows organized by category | Discovering capabilities |
Tip:
/lsworks for both new and returning users. No project? It explains learnship and offers/new-project. Returning? It shows your progress and suggests exactly what to do next.

Every feature ships through a 7-step loop:
flowchart LR
DP["/discuss-phase N<br/>Capture decisions"]
PP["/plan-phase N<br/>Vertical slice plans"]
EP["/execute-phase N<br/>Build + commit"]
VW["/verify-work N<br/>UAT + diagnose"]
RV["/review<br/>Two-pass review"]
SH["/ship<br/>Test → PR"]
CP["/compound<br/>Capture knowledge"]
DP --> PP --> EP --> VW
VW --> RV --> SH --> CP
CP -->|"next phase"| DP
VW -->|"all done"| DONE["✓ /complete-milestone"]
| Step | Command | What happens |
|---|---|---|
| 1. Discuss | /discuss-phase N | You and the agent align on implementation decisions before any code. Add --deep for extended deep questioning that walks every branch (v2.3.4) |
| 2. Plan | /plan-phase N | Agent researches the domain, creates vertical slice plans (tracer bullets), verifies them — including horizontal slice detection (v2.3.4) |
| 3. Execute | /execute-phase N | Plans run in dependency order, one atomic commit per task |
| 4. Verify | /verify-work N | You do UAT; agent diagnoses any gaps and creates fix plans |
| 5. Review | /review | Two-pass review: spec compliance check then 6-lens quality review (v2.4.0) |
| 6. Ship | /ship | Test → lint → commit → push → PR (v2.0) |
| 7. Compound | /compound | Capture what you learned as searchable documentation (v2.0) |
Just starting? /ls or /next will route you into the right step automatically.

Three integrated layers that reinforce each other:
| Layer | What it does |
|---|---|
| Workflow Engine | Spec-driven phases → context-engineered plans → wave-ordered execution → verified delivery |
| Learning Partner | Neuroscience-backed checkpoints at every phase transition: retrieval, reflection, spacing, struggle |
| Design System | 21 impeccable steering commands for production-grade UI: /audit, /critique, /polish, and more |

Each platform gets the best experience it supports:
| Feature | Windsurf | Claude Code | OpenCode | Gemini CLI | Codex CLI |
|---|---|---|---|---|---|
| Slash commands | ✓ | ✓ | ✓ | ✓ | $skills |
| Real parallel subagents | — | ✓ | ✓ | ✓ | ✓ |
| Parallel wave execution | — | ✓ | ✓ | ⚠️ experimental | ✓ |
| Agent personas (17) | model_decision rules | Task() subagents | Task() subagents | Task() subagents | Task() subagents |
| Interactive questions | ask_user_question | AskUserQuestion | question | ask_user | request_user_input |
| Session hooks | — | ✓ | — | ✓ | — |
Skills (native @invoke) | ✓ | — | — | — | — |
| Skills (context files) | ✓ | ✓ | ✓ | ✓ | ✓ |
Cursor uses context injection via cursor-rules/learnship.mdc — it gets the full workflow library, design system, and learning partner, but does not appear in the feature matrix above because it has no first-class slash command or subagent API (rules load automatically as context).
Parallel subagents: Claude Code, OpenCode, and Codex default to parallel execution — execute-phase spawns a dedicated executor per plan within a wave, each with its own 200k context budget. Up to 5 concurrent agents per wave. To run sequentially, set "parallelization": { "enabled": false } in .planning/config.json. Windsurf, Cursor, and Gemini CLI use sequential execution (no real subagent API on those platforms).
learnship is an agent harness — the scaffolding that makes your AI coding agent actually reliable across real projects.
Every serious AI coding tool converges on the same architecture: a simple execution loop wraps the model, and the harness decides what information reaches the model, when, and how. The model is interchangeable. The harness is the product.
learnship gives you that harness as a portable, open-source layer that adds:
/new-project generates an AGENTS.md loaded automatically every session. No more repeating yourself./compound captures solved problems. /review runs two-pass code review (spec compliance then quality). /ship runs the full delivery pipeline./secure-phase for STRIDE + OWASP Top 10 verification. /forensics for post-mortem. /undo for safe revert.If you've used AI coding assistants for more than a few sessions, you've hit this wall:
The agent forgets everything. Each session starts from scratch. Decisions get repeated. Code quality drifts. You ship fast but understand less.
This is a harness problem, not a model problem. The same model scores 42% with one scaffold and 78% with another. Same model. The only variable is the harness.
learnship solves this with progressive disclosure — context revealed incrementally, not dumped upfront. The right files, decisions, and phase context reach the agent exactly when needed.
| Without learnship | With learnship |
|---|---|
| Context resets every session | AGENTS.md loaded automatically every conversation |
| Ad-hoc prompts, unpredictable results | Spec-driven plans, verifiable deliverables |
| Architectural decisions get forgotten | DECISIONS.md tracked and honored by the agent |
| Everything dumped into context at once | Phase-scoped context: only what this step needs |
| You ship code you don't fully understand | Learning checkpoints build real understanding at every step |
| UI looks generic, AI-generated | impeccable design system prevents AI aesthetic slop |
Anyone who wants to build and ship real products with AI agents — founders, designers, researchers, makers, not just developers.
It's the right tool if:
It's probably overkill for one-off scripts. Use /quick for that.
faviovazquez.github.io/learnship
@agentic-learning actions + 21 impeccable design commandsv2.4.0 adds spec compliance checking to /review, OWASP Top 10 coverage to /secure-phase, a numeric score to /health, and Playwright MCP smoke-test guidance to /verify-work and /ship:
Two-stage /review: Pass 1 checks spec compliance — reads PLAN.md must-haves and classifies each as COVERED / PARTIAL / MISSING — before Pass 2 runs the existing 6-persona quality review. The spec compliance result appears in the report header. Use --quality-only to skip Pass 1 and run only the quality review.
OWASP Top 10 in /secure-phase: The security-auditor agent now cross-maps STRIDE findings against OWASP Top 10 (A01–A10). Every SECURITY.md output includes an OWASP coverage table alongside the STRIDE analysis.
Numeric /health score: The health check now outputs a 0–100 numeric score alongside the qualitative status. Starts at 100, deducts per issue found. Bands: HEALTHY (90–100), DEGRADED (70–89), BROKEN (0–69).
Playwright MCP guidance in /verify-work and /ship: Optional live UI smoke-test sections activate when @playwright/mcp is configured. Supported on all 6 MCP-capable platforms (Claude Code, OpenCode, Cursor, Windsurf, Codex CLI, Gemini CLI). In /verify-work, walks the golden path using mcp__playwright__* tools. In /ship, runs a quick smoke test before creating the PR.
v2.3.4 adds two planning quality features:
Deep questioning mode (--deep flag or workflow.discuss_mode: "deep" in config): Both /discuss-phase and /new-project now support extended questioning that walks every decision branch until shared understanding is reached. Each question includes a recommended answer. Standard mode (4 focused exchanges) remains the default.
Vertical slice planning (enforced in plan-phase): Plans are now required to be tracer bullets — thin vertical slices through all integration layers (data → logic → API → UI → test) for one demoable user-facing behavior. The plan-checker flags any plan that covers only one architectural layer across all features. Single-layer phases (migrations, style passes) use single_layer_justified: true in the plan frontmatter.
v2.3 adds 5 new agent personas, Windsurf-native persona adoption via model_decision rules, and inline <persona_context> blocks across all 18 persona-aware workflows:
5 new agent personas: project-researcher (domain ecosystem research for /new-project), research-synthesizer (synthesizes 4 research files into SUMMARY.md), roadmapper (creates phased roadmaps from requirements), phase-researcher (focused research for /plan-phase and /research-phase), doc-verifier (verifies docs match live code). Total agent pool: 17 specialist personas.
Windsurf model_decision rules: Agent personas are now installed as .windsurf/rules/learnship-{name}.md with trigger: model_decision frontmatter. Windsurf's Cascade sees the rule description in every system prompt and reads the full persona when context is relevant — the native equivalent of Claude Code's subagent spawning.
Inline <persona_context> blocks: All 18 workflows that reference agent personas now include inline persona instructions directly in the workflow text. This works on every platform — no special tool needed. Belt-and-suspenders with @./agents/ file references and platform-native mechanisms.
Codex sandbox map: All 17 agent personas now have per-agent sandbox modes (read-only for checkers/auditors, workspace-write for executors/planners).
Published agents synced: The agents/ directory now contains all 17 agents with proper frontmatter (name:, description:, tools:, color:) — in sync with the source learnship/agents/ directory.
v2.2 adds session intelligence, structured interactivity, and research templates:
Session hooks (Claude Code + Gemini CLI): 4 hooks installed via settings.json — statusline showing context usage, context monitor that warns before context runs out, prompt guard that scans .planning/ writes for injection patterns, and session state that injects project orientation at startup.
Context profiles: Set "context": "dev" (default), "research", or "review" in config.json to control agent output style. Switch with /settings.
Interactive questions: 14 workflows present decisions via your platform's native structured question tool — clickable cards on Claude Code, dropdowns on Windsurf, etc. install.js rewrites the tool name per platform automatically.
Agent persona delegation: 18 workflows use inline <persona_context> blocks and @./agents/ references for sequential persona adoption, with Task() subagent spawning when parallelization is enabled.
Research templates: 5 structured fill-in-the-blanks templates (STACK.md, FEATURES.md, ARCHITECTURE.md, PITFALLS.md, SUMMARY.md) that prevent the AI from skipping file writes.
Upgrade safety: SHA-256 file manifest after every install. Locally modified files detected and backed up before overwriting. Run /reapply-patches to restore customizations.
v2.1 adds 8 new workflows, 5 new references, 3 new templates, and 2 new agents:
| Category | New workflows |
|---|---|
| Security | /secure-phase — per-phase STRIDE threat-model security verification |
| Documentation | /docs-update — generate and verify project docs against codebase |
| Recovery | /forensics — post-mortem investigation · /undo — safe git revert |
| Session | /note — zero-friction capture · /session-report — stakeholder summaries |
| Learning | /extract-learnings — decisions, lessons, patterns, surprises · /milestone-summary — team onboarding |
Enhanced: /discuss-phase (scope guardrails + domain probes + --deep extended questioning v2.3.4), /new-project (--deep extended questioning v2.3.4), /plan-phase (vertical slice tracer bullets + horizontal slice detection v2.3.4), /execute-phase (--wave flag + context scaling), /quick (--research --validate --full composable flags), /ideate (--explore Socratic mode).
Optional per-phase: /secure-phase N (STRIDE security), /extract-learnings N (meta-knowledge).
Recovery: /forensics (post-mortem), /undo (safe revert).

| Vibe coding | Agentic engineering | |
|---|---|---|
| Context | Resets every session | Engineered into every agent call |
| Decisions | Implicit, forgotten | Tracked in DECISIONS.md, honored by the agent |
| Plans | Ad-hoc prompts | Spec-driven, verifiable, wave-ordered |
| Outcome | Code you shipped | Code you shipped and understand |

Every agent invocation is loaded with structured context. Nothing is guessed:
flowchart LR
subgraph CONTEXT["Loaded into every agent call"]
A["AGENTS.md<br/>Project soul + current phase"]
B["REQUIREMENTS.md<br/>What we're building"]
C["DECISIONS.md<br/>Every architectural choice"]
D["Phase CONTEXT.md<br/>Implementation preferences"]
end
CONTEXT --> AGENT["AI Agent"]
AGENT --> P["Executable PLAN.md"]
AGENT --> S["Commits + SUMMARY.md"]

/new-project generates an AGENTS.md at your project root. On Windsurf, Claude Code, and Cursor it loads automatically every session. On other platforms, workflows reference it explicitly. Either way: the agent always knows the project, current phase, tech stack, and past decisions.
AGENTS.md ← your AI agent reads this every conversation
├── Soul & Principles # Pair-programmer framing, 10 working principles
├── Platform Context # Points to .planning/, explains the phase loop
├── Current Phase # Updated automatically by workflows
├── Project Structure # Filled during new-project from your answers
├── Tech Stack # Filled from research results
└── Regressions # Updated by /debug when bugs are fixed
These are all 57 workflows. Most users discover them naturally from
/ls. Scan this when you want to know if a specific capability exists.
| Workflow | Purpose | When to use |
|---|---|---|
/new-project | Full init: questions → research → requirements → roadmap | Start of any new project |
/discuss-phase [N] | Capture implementation decisions before planning | Before every phase |
/plan-phase [N] | Research + create + verify plans | After discussing a phase |
/execute-phase [N] | Wave-ordered execution of all plans | After planning |
/verify-work [N] | Manual UAT with auto-diagnosis and fix planning. Optional Playwright MCP live UI smoke test when @playwright/mcp is configured. | After execution |
/complete-milestone | Archive milestone, tag release, prepare next | All phases verified |
/audit-milestone | Pre-release: requirement coverage, stub detection | Before completing milestone |
/new-milestone [name] | Start next version cycle | After completing a milestone |
| Workflow | Purpose | When to use |
|---|---|---|
/ls | Status + next step + offer to run it | Start every session here |
/next | Auto-pilot: reads state and runs the right workflow | When you just want to keep moving |
/progress | Same as /ls: status overview with smart routing | "Where am I?" |
/resume-work | Restore full context from last session | Starting a new session |
/pause-work | Save handoff file mid-phase | Stopping mid-phase |
/quick [description] | Ad-hoc task with full guarantees | Bug fixes, small features |
/help | Show all available workflows | Quick command reference |
| Workflow | Purpose | When to use |
|---|---|---|
/add-phase | Append new phase to roadmap | Scope grows after planning |
/insert-phase [N] | Insert urgent work between phases | Urgent fix mid-milestone |
/remove-phase [N] | Remove future phase and renumber | Descoping a feature |
/research-phase [N] | Deep research only, no plans yet | Complex/unfamiliar domain |
/list-phase-assumptions [N] | Preview intended approach before planning | Validate direction |
/plan-milestone-gaps | Create phases for audit gaps | After audit finds missing items |
| Workflow | Purpose | When to use |
|---|---|---|
/map-codebase | Analyze existing codebase | Before /new-project on existing code |
/discovery-phase [N] | Map unfamiliar code area before planning | Entering complex/unfamiliar territory |
/debug [description] | Systematic triage → diagnose → fix | When something breaks |
/diagnose-issues [N] | Batch-diagnose all UAT issues by root cause | After verify-work finds multiple issues |
/execute-plan [N] [id] | Run a single plan in isolation | Re-running a failed plan |
/add-todo [description] | Capture an idea without breaking flow | Think of something mid-session |
/check-todos | Review and act on captured todos | Reviewing accumulated ideas |
/add-tests | Generate test coverage post-execution | After executing a phase |
/validate-phase [N] | Retroactive test coverage audit | After hotfixes or legacy phases |
| Workflow | Purpose | When to use |
|---|---|---|
/decision-log [description] | Capture decision with context and alternatives | After any significant architectural choice |
/knowledge-base | Aggregate all decisions and lessons into one file | Before starting a new milestone |
/knowledge-base search [query] | Search the project knowledge base | When you need to recall why something was built a certain way |
| Workflow | Purpose | When to use |
|---|---|---|
/discuss-milestone [version] | Capture goals, anti-goals before planning | Before /new-milestone |
/milestone-retrospective | 5-question retrospective + spaced review | After /complete-milestone |
/transition | Write full handoff document for new session/collaborator | Before handing off or long break |
| Workflow | Purpose | When to use |
|---|---|---|
/compound | Capture solved problem as searchable documentation | After /debug, /verify-work, or any aha moment |
/review | Two-pass review: spec compliance check then 6-persona quality review. --quality-only skips spec compliance. | After /verify-work, before shipping |
/challenge | Stress-test scope through product + engineering lenses | Before committing to a milestone or large feature |
/ship | Test → lint → commit → push → PR. Optional Playwright MCP smoke test before PR creation when @playwright/mcp is configured. | After review, ready to deploy |
/ideate | Codebase-grounded idea generation | Before /discuss-milestone, between milestones |
/guard | Safety mode: protect sensitive directories | Working on auth, payments, migrations |
/sync-docs | Detect stale documentation | Before /complete-milestone, after refactors |
| Workflow | Purpose | When to use |
|---|---|---|
/settings | Interactive config editor | Change mode, toggle agents |
/set-profile [quality|balanced|budget] | One-step model profile switch | Quick cost/quality adjustment |
/health | Project health check with numeric 0–100 score (HEALTHY ≥90, DEGRADED ≥70, BROKEN <70) | Stale files, missing artifacts |
/cleanup | Archive old artifacts | End of milestone |
/update | Update the platform itself | Check for new workflows |
/reapply-patches | Restore local edits after update | After /update if you had local changes |
Project settings live in .planning/config.json. Set during /new-project or edit with /settings.
{
"mode": "interactive",
"granularity": "standard",
"model_profile": "balanced",
"learning_mode": "auto",
"context": "dev",
"test_first": false,
"planning": {
"commit_docs": true,
"commit_mode": "auto",
"search_gitignored": false
},
"workflow": {
"research": true,
"plan_check": true,
"verifier": true,
"validation": true,
"review": true,
"solutions_search": true,
"security_enforcement": true,
"discuss_mode": "discuss",
"tdd_mode": false
},
"parallelization": {
"enabled": false,
"plan_level": true,
"task_level": false,
"max_concurrent_agents": 5,
"min_plans_for_parallel": 2
},
"gates": {
"confirm_project": true,
"confirm_phases": true,
"confirm_roadmap": true,
"confirm_plan": true,
"execute_next_plan": true,
"issues_review": true,
"confirm_transition": true
},
"safety": {
"always_confirm_destructive": true,
"always_confirm_external_services": true
},
"review": {
"auto_after_verify": false
},
"ship": {
"auto_test": true,
"conventional_commits": true,
"pr_template": true
},
"hooks": {
"context_warnings": true
},
"git": {
"branching_strategy": "none",
"phase_branch_template": "phase-{phase}-{slug}",
"milestone_branch_template": "{milestone}-{slug}"
}
}
| Setting | Options | Default | What it controls |
|---|---|---|---|
mode | auto, interactive | auto | auto auto-approves steps; interactive confirms at each decision |
granularity | coarse, standard, fine | standard | Phase size: 3-5 / 5-8 / 8-12 phases |
model_profile | quality, balanced, budget | balanced | Agent model tier (see table below) |
learning_mode | auto, manual | auto | auto offers learning at checkpoints; manual requires explicit invocation |
context | dev, research, review | dev | Output profile: dev (concise), research (detailed), review (audit-focused) |
parallelization.enabled | true, false | true (Claude Code, OpenCode, Codex) / false (others) | Parallel subagents per plan on supported platforms |
test_first | true, false | false | TDD mode: write failing test first, verify red, implement, verify green |
planning.commit_mode | auto, manual | auto | auto commits after each workflow step; manual skips all git commits |
| Setting | Default | What it controls |
|---|---|---|
workflow.research | true | Domain research before planning each phase |
workflow.plan_check | true | Plan verification loop (up to 3 iterations), including vertical slice integrity check |
workflow.verifier | true | Post-execution verification against phase goals |
workflow.validation | true | Test coverage mapping during plan-phase |
workflow.review | true | Enable /review suggestions after /verify-work (v2.0) |
workflow.solutions_search | true | Search .planning/solutions/ during /plan-phase (v2.0) |
workflow.security_enforcement | true | Per-phase STRIDE security verification via /secure-phase |
workflow.discuss_mode | "discuss" | Questioning depth: "discuss" (4 exchanges) or "deep" (extended, walks every branch) (v2.3.4) |
workflow.tdd_mode | false | Instruct planner to apply TDD task ordering to eligible tasks |
| Setting | Default | What it controls |
|---|---|---|
review.auto_after_verify | false | Auto-run /review after /verify-work passes |
ship.auto_test | true | Run test suite before shipping |
ship.conventional_commits | true | Use conventional commit format |
ship.pr_template | true | Auto-generate PR description |
branching_strategy | Creates branch | Best for |
|---|---|---|
none | Never | Solo dev, simple projects |
phase | At each execute-phase | Code review per phase |
milestone | At first execute-phase | Release branches, PR per version |
| Agent | quality | balanced | budget |
|---|---|---|---|
| Planner | large | large | medium |
| Executor | large | medium | medium |
| Phase Researcher | large | medium | small |
| Debugger | large | medium | medium |
| Verifier | medium | medium | small |
| Plan Checker | medium | medium | small |
| Solution Writer | medium | medium | small |
| Code Reviewer | large | medium | medium |
| Challenger | large | medium | medium |
| Ideation Agent | large | medium | small |
Platform note: Tiers map to the best available model on your platform. On Claude Code:
large= Opus,medium= Sonnet,small= Haiku. On Gemini CLI and Codex CLI the installer maps tiers to the best available model at install time. Windsurf, Cursor, and OpenCode use the platform default model — tiers signal intended task complexity.
| Scenario | mode | granularity | model_profile | Research | Plan Check | Verifier |
|---|---|---|---|---|---|---|
| Prototyping | auto | coarse | budget | off | off | off |
| Normal dev | auto | standard | balanced | on | on | on |
| Production | interactive | fine | quality | on | on | on |
The learning partner is woven into the platform, not bolted on. It fires at natural workflow transitions to build genuine understanding, not just fluent answers.
learning_mode: "auto" → offered automatically at checkpoints (default)
learning_mode: "manual" → only when you explicitly invoke @agentic-learning
| Action | Trigger | What it does |
|---|---|---|
@agentic-learning learn [topic] | Any time | Active retrieval: explain before seeing, then fill gaps |
@agentic-learning quiz [topic] | Any time | 3-5 questions, one at a time, formative feedback |
@agentic-learning reflect | After execute-phase | Three-question structured reflection: learned / goal / gaps |
@agentic-learning space | After verify-work | Schedule concepts for spaced review → writes docs/revisit.md |
@agentic-learning brainstorm [topic] | After new-project | Collaborative design dialogue before any code |
@agentic-learning struggle [topic] | During quick | Hint ladder: try first, reveal only when needed |
@agentic-learning either-or | After discuss-phase | Decision journal: paths considered, choice, rationale |
@agentic-learning explain-first | Any time | Oracy exercise: you explain, agent gives structured feedback |
@agentic-learning explain [topic] | Any time | Project comprehension log → writes docs/project-knowledge.md |
@agentic-learning interleave | Any time | Mixed retrieval across multiple topics |
@agentic-learning cognitive-load [topic] | After plan-phase | Decompose overwhelming scope into working-memory steps |
Core principle: Fluent answers from an AI are not the same as learning. Every action makes you do the cognitive work, with support rather than shortcuts.
| Platform | How agentic-learning works |
|---|---|
| Windsurf | Native skill: invoke with @agentic-learning learn, @agentic-learning quiz, etc. |
| Claude Code, OpenCode, Gemini CLI, Codex CLI | Installed as a context file in learnship/skills/agentic-learning/. The AI reads and applies the techniques automatically. Reference it explicitly with use the agentic-learning skill or just work normally and it activates at checkpoints. |
The impeccable skill suite is always active as project context for any UI work. It provides design direction, anti-patterns, and 21 steering commands that prevent generic AI aesthetics. Based on @pbakaus/impeccable.
| Command | What it does |
|---|---|
/teach-impeccable | One-time setup: gathers project design context and saves persistent guidelines |
/audit | Comprehensive audit: accessibility, performance, theming, responsive design |
/critique | UX critique: visual hierarchy, information architecture, emotional resonance |
/polish | Final quality pass: alignment, spacing, consistency before shipping |
/normalize | Normalize design to match your design system for consistency |
/colorize | Add strategic color to monochromatic or flat interfaces |
/animate | Add purposeful animations and micro-interactions |
/bolder | Amplify safe or boring designs for more visual impact |
/quieter | Tone down overly aggressive designs to reduce intensity and gain refinement |
/distill | Strip to essence: remove complexity, clarify what matters |
/clarify | Improve UX copy, error messages, microcopy, labels |
/typeset | Improve typography: font choices, hierarchy, sizing, weight, and readability |
/arrange | Improve layout, spacing, and visual rhythm; fix monotonous grids and weak hierarchy |
/optimize | Performance: loading speed, rendering, animations, bundle size |
/harden | Resilience: error handling, i18n, text overflow, edge cases |
/delight | Add moments of joy and personality that make interfaces memorable |
/overdrive | Push past conventional limits — shaders, spring physics, scroll-driven reveals |
/extract | Extract reusable components and design tokens into your design system |
/adapt | Adapt designs across screen sizes, devices, and contexts |
/onboard | Design onboarding flows, empty states, first-time user experiences |
The AI Slop Test: If you showed the interface to someone and said "AI made this", would they believe you immediately? If yes, that's the problem. Use /critique to find out.
Automatic UI standards during execute-phase: When a phase involves UI work, learnship detects it automatically and activates @impeccable frontend-design principles before any code is written. You'll see a banner announcing it. The agent then applies typography, color, layout, and component standards across every task in the phase — not as a post-hoc review but as an active constraint during execution.
Post-action milestone recommendation: After any impeccable action produces recommendations, the agent suggests running /new-milestone to create a dedicated "UI Polish" milestone. This turns impeccable findings into versioned, traceable phases with plans and commits — so improvements don't disappear into chat history. Applying directly is always an option too.
| Platform | How impeccable works |
|---|---|
| Windsurf | Native skills: invoke each command directly with /audit, /polish, /critique, etc. |
| Claude Code, OpenCode, Gemini CLI, Codex CLI | Installed as context files in learnship/skills/impeccable/. The AI reads design principles and anti-patterns automatically. Reference commands explicitly with run the /audit impeccable skill or just ask for UI work and it applies the standards. |
/new-project # Answer questions, configure, approve roadmap
/discuss-phase 1 # Lock in your implementation preferences
/plan-phase 1 # Research + plan + verify
/execute-phase 1 # Wave-ordered execution
/verify-work 1 # Manual UAT
/review # two-pass review: spec compliance + quality (v2.4.0)
/ship # v2.0: test → commit → push → PR
/compound # v2.0: capture what you learned
# Repeat for each phase
/sync-docs # v2.0: detect stale documentation
/audit-milestone # Check everything shipped
/complete-milestone # Archive, tag, done
/map-codebase # Structured codebase analysis
/new-project # Questions focus on what you're ADDING
# Normal phase workflow from here
/quick "Fix login button not responding on mobile Safari"
/quick --discuss --full "Add dark mode toggle"
/ls # See where you left off (offers to run next step)
# or
/next # Just pick up and go: auto-pilot
# or
/resume-work # Full context restoration
/add-phase # Append new phase to roadmap
/insert-phase 3 # Insert urgent work between phases 3 and 4
/remove-phase 7 # Descope phase 7 and renumber
/audit-milestone # Check requirement coverage, detect stubs
/plan-milestone-gaps # If audit found gaps, create phases to close them
/complete-milestone # Archive, tag, done
/debug "Login flow fails after password reset"
Every project accumulates decisions: architecture choices, library picks, scope trade-offs. The platform tracks them in a structured register so future sessions understand why the project is built the way it is.
.planning/DECISIONS.md is the decision register:
## DEC-001: Use Zustand over Redux
Date: 2026-03-01 | Phase: 2 | Type: library
Context: Needed client-side state for dashboard filters
Options: Zustand (simple, no boilerplate), Redux (complex, overkill for scope)
Choice: Zustand
Rationale: 3x less boilerplate, sufficient for current data flow complexity
Consequences: Locks React as UI framework; migration would require state rewrite
Status: active
Populated automatically by:
discuss-phase surfaces prior decisions before each phase discussionplan-phase reads decisions before creating plans (never contradicts active ones)debug puts architectural lessons from bugs into the registerdecision-log manually captures any decision from any conversationQueried by:
audit-milestone checks decisions were honored in implementationknowledge-base aggregates all decisions into a searchable KNOWLEDGE.mdEvery project creates a structured .planning/ directory:
.planning/
├── config.json # Workflow settings
├── PROJECT.md # Vision, requirements, key decisions
├── REQUIREMENTS.md # v1 requirements with REQ-IDs
├── ROADMAP.md # Phase breakdown with status tracking
├── STATE.md # Current position, decisions, blockers
├── DECISIONS.md # Cross-phase decision register
├── KNOWLEDGE.md # Aggregated lessons (from knowledge-base)
├── research/ # Domain research from new-project
│ ├── STACK.md
│ ├── FEATURES.md
│ ├── ARCHITECTURE.md
│ ├── PITFALLS.md
│ └── SUMMARY.md
├── codebase/ # Brownfield mapping (from map-codebase)
│ ├── STACK.md
│ ├── ARCHITECTURE.md
│ ├── CONVENTIONS.md
│ └── CONCERNS.md
├── todos/
│ ├── pending/ # Captured ideas awaiting work
│ └── done/ # Completed todos
├── solutions/ # Knowledge compounding (from /compound) (v2.0)
│ ├── auth/ # Solutions by category
│ ├── performance/
│ └── ...
├── debug/ # Active debug sessions
│ └── resolved/ # Archived debug sessions
├── quick/
│ └── 001-slug/ # Quick task artifacts
│ ├── 001-PLAN.md
│ ├── 001-SUMMARY.md
│ └── 001-VERIFICATION.md (if --full)
└── phases/
└── 01-phase-name/
├── 01-CONTEXT.md # Your implementation preferences
├── 01-DISCOVERY.md # Unfamiliar area mapping (from discovery-phase)
├── 01-RESEARCH.md # Ecosystem research findings
├── 01-VALIDATION.md # Test coverage contract (from /validate-phase)
├── 01-01-PLAN.md # Executable plan (wave 1)
├── 01-02-PLAN.md # Executable plan (wave 1, independent)
├── 01-01-SUMMARY.md # Execution outcomes
├── 01-UAT.md # User acceptance test results
└── 01-VERIFICATION.md # Post-execution verification
/new-project found .planning/PROJECT.md already exists. If you want to start over, delete .planning/ first. To continue, use /progress or /resume-work.
Start each major workflow with a fresh context. The platform is designed around fresh context windows; every agent gets a clean slate. Use /resume-work or /progress to restore state after clearing.
Run /discuss-phase [N] before planning. Most plan quality issues come from unresolved gray areas. Run /list-phase-assumptions [N] to see the intended approach before committing to a plan.
Plans with more than 3 tasks are too large for reliable single-context execution. Re-plan with smaller scope: /plan-phase [N] with finer granularity.
Run /ls. It reads all state files, shows your progress, and offers to run the next step.
Use /quick for targeted fixes, or /verify-work to systematically identify and fix issues through UAT. Do not re-run /execute-phase on a phase that already has summaries.
Switch to budget profile via /settings. Disable research and plan-check for familiar domains. Use granularity: "coarse" for fewer, broader phases.
Set commit_docs: false during /new-project or via /settings. Add .planning/ to .gitignore. Planning artifacts stay local.
Run /debug "description of what's broken". It runs triage → root cause diagnosis → fix planning with a persistent debug session.
Run /audit-milestone to surface all gaps, then /plan-milestone-gaps to create fix phases before release.
| Problem | Solution |
|---|---|
| Lost context / new session | /ls or /next |
| Phase went wrong | git revert the phase commits, re-plan |
| Need to change scope | /add-phase, /insert-phase, or /remove-phase |
| Milestone audit found gaps | /plan-milestone-gaps |
| Something broke | /debug "description" |
| Quick targeted fix | /quick |
| Plans don't match your vision | /discuss-phase [N] then re-plan |
| Costs running high | /settings → budget profile, toggle agents off |
learnship/
├── .windsurf/
│ ├── workflows/ # 57 workflows as slash commands
│ ├── rules/ # 17 model_decision rules (agent personas for Windsurf)
│ └── skills/
│ ├── agentic-learning/ # Learning partner (SKILL.md + references), native on Windsurf + Claude Code
│ └── impeccable/ # Design suite: 21 skills, native on Windsurf + Claude Code
│ ├── frontend-design/ # Base skill + 7 reference files (typography, color, motion…)
│ ├── audit/ # /audit
│ ├── critique/ # /critique
│ ├── polish/ # /polish
│ └── …14 more/ # /colorize /animate /bolder /quieter /distill /clarify…
│ # → on OpenCode/Gemini/Codex: both skills copied to learnship/skills/ as context files
├── commands/ # 57 Claude Code-style slash command wrappers
│ └── learnship/ # /learnship:ls, /learnship:new-project, etc.
├── learnship/ # Payload installed into the target platform config dir
│ ├── workflows/ # 57 workflow markdown files (the actual instructions)
│ ├── references/ # Reference docs (questioning, verification, git, design, learning)
│ └── templates/ # Document templates for .planning/ + AGENTS.md template
├── agents/ # 17 agent personas (planner, researcher, project-researcher, research-synthesizer, phase-researcher, roadmapper, executor, verifier, debugger, plan-checker, solution-writer, code-reviewer, challenger, ideation-agent, security-auditor, doc-writer, doc-verifier)
├── assets/ # Brand images (banner, explainers, diagrams)
├── bin/
│ └── install.js # Multi-platform installer (Claude Code, OpenCode, Gemini CLI, Codex CLI, Windsurf)
├── tests/
│ └── run_all.sh # 17 test suites, 1330+ checks across 6 platforms
├── SKILL.md # Meta-skill: platform context loaded by Cascade / AI agents
├── install.sh # Shell installer wrapper
├── package.json # npm package (npx learnship)
├── CHANGELOG.md # Version history
└── CONTRIBUTING.md # How to extend the platform
learnship builds on ideas and work from these open-source projects:
learnship adapts, combines, and extends these into a unified, multi-platform system with integrated learning. All are used as inspiration and learnship is original work built on their shoulders.
MIT © Favio Vazquez
FAQs
Learn as you build. Build with intent. — A multi-platform agentic engineering system for Windsurf, Claude Code, Cursor, OpenCode, Gemini CLI, and Codex: 57 spec-driven workflows, 17 specialist agent personas, integrated learning, and production-grade desi
The npm package learnship receives a total of 137 weekly downloads. As such, learnship popularity was classified as not popular.
We found that learnship demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.

Security News
Rolldown paused Rust React Compiler integration after a 5MB binary size increase raised concerns about shipping React-specific code to all Vite users.

Security News
/Research
Mini Shai-Hulud expands into the Go ecosystem after hitting LeoPlatform npm packages and targeting GitHub Actions workflows.